1. Redis 구조
서론
지금부터 다룰 Redis 시리즈는 개인 공부 내용 정리 목적으로 작성하였습니다. 주요 포스팅 내용은 redis-cli 명령어 학습과 Spring Data Redis를 활용해서 해당 명령어 적용방법에 대해서 살펴보겠습니다.
이번 포스팅은 Redis를 다루는 첫 포스팅으로 Redis 구조에 대해서 개략적으로 살펴보겠습니다. 전문지식을 기반으로 작성한 내용이 아닌만큼 틀린 부분이 있다면 피드백 부탁드립니다.
1. Redis 접속

DBMS을 사용하기 위해서는 명령어 처리를 위한 별도 프로그램이 필요합니다. 이를 위해 각 DBMS 벤더사에서 DB와 통신을 위한 CLI(Command Line Interface) 프로그램을 제공합니다. 가령 oracle 사용한다면, oracle에서 기본적으로 제공하는 sql * plus 프로그램을 사용해서 DB에 접속할 수 있습니다.
마찬가지로 Redis를 사용하기 위해서는 Redis에 접속할 수 있는 프로그램이 필요합니다.

Redis에서는 이를 위해 redis-cli를 제공하며, Redis가 설치된 환경에서 사용자가 Redis를 사용하기 위해 가장 처음 접하게 되는 프로그램이 redis-cli입니다.

typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
Redis에 접속하게되면, redis-server는 Client 구조체로 저장하여 linked list 형식으로 관리합니다. 여기서 주목할 점은 Client 명령을 처리하기 위해 필요한 인자는 argc와 argv 멤버 변수를 통해 전달되며, 해당 구조는 redisObject 구조체로 정의되어있습니다.
해당 구조체에서 type 멤버 변수는 Redis에서 지원하는 데이터 타입을 의미합니다. 지원하는 타입 종류로는 String, List, Set, Sorted Set, Hash, Bitmap, HyperLogLogs 등이 있습니다. 각 데이터 타입에 대한 소개는 차후 포스팅을 통해 살펴보겠습니다.
그외 redisObject 구조체 각 멤버 변수에 대한 설명은 redisgate 홈페이지에 자세히 소개되어있으니 참고 바랍니다.
2. Redis 구조
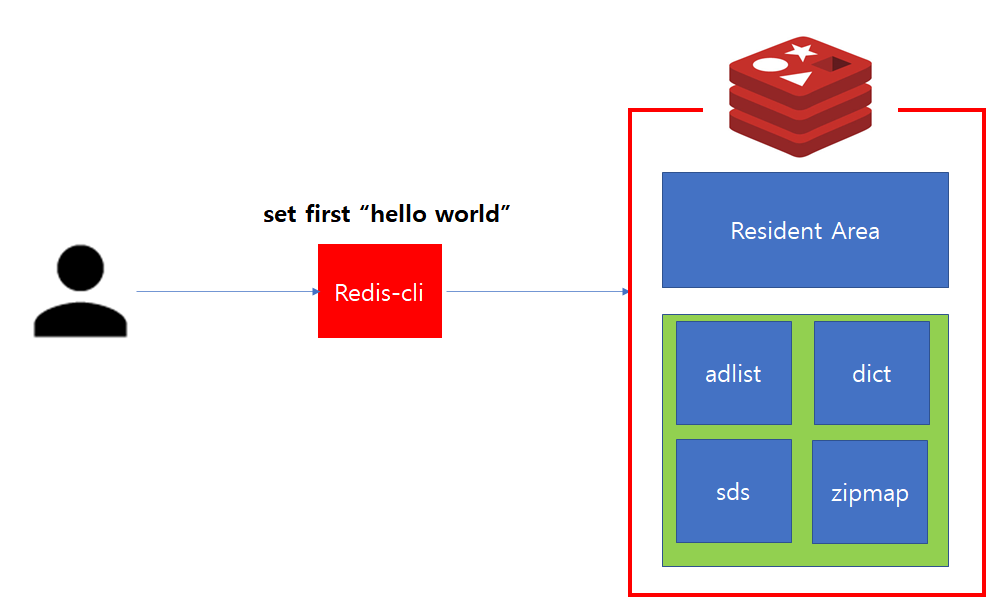
인스턴스에 정상적으로 접속했다면, 명령어 전달을 통해 데이터를 저장하거나 조작할 수 있습니다. Redis는 In Memory 데이터 구조 저장소로써 위 그림에서 해당되는 데이터 구조는 모두 메모리에 상주합니다.
위 구조에서 Resident Area는 명령어를 통해 실제 데이터가 저장 및 작업이 수행되는 공간입니다. 초록색 영역은 내부적으로 서버 상태를 저장하고 관리하기 위한 메모리 공간으로 사용되며, Data Structure 영역으로 불립니다.
Data Structure 영역에 대한 설명은 차후 데이터 타입 포스팅을 진행할 때 다루어보겠습니다.
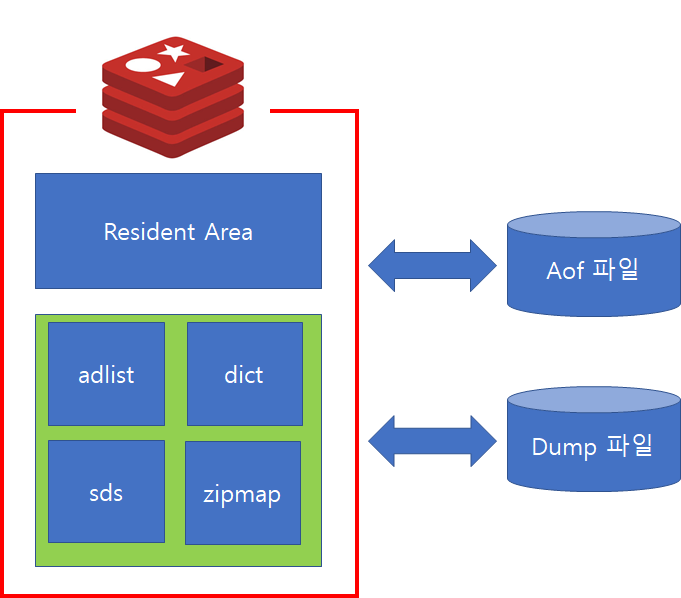
앞서 Redis는 In Memory 데이터 구조 저장소라고 설명했습니다. 하지만 Memory는 휘발성이기 때문에, 프로세스를 종료하게되면 데이터는 모두 유실됩니다. 따라서 단순 캐시용도가 아닌 Persistence 저장소로 활용을 위해서는 Disk에 저장하여 데이터 유실이 발생되지 않도록 해야합니다. 이를 위해 AOF(Append Only File)기능과 RDB(Snapshot) 기능이 존재합니다.

AOF는 전달된 명령을 별도에 파일에 기록하는 방법으로 RDBMS의 Redo 메커니즘과 유사합니다. AOF의 역할은 재기동시 파일에 기록된 명령어를 일괄 수행하여 데이터를 복구하는데 사용됩니다.
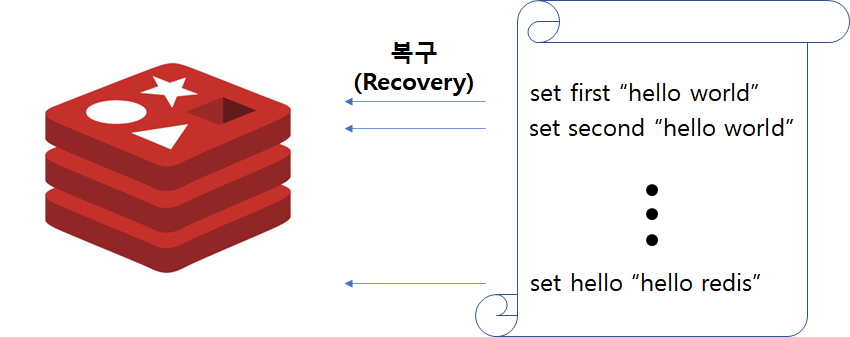
AOF의 장점으로는 데이터 유실이 발생하지 않습니다. 하지만 매 명령어마다 File과의 동기화가 필요하기 때문에 처리속도가 현격히 줄어듭니다. 따라서 이를 해소하기위해 File Sync 옵션(appendfsync)이 존재하며, 해당 옵션에 따라 Sync 주기를 조절할 수 있으나 그만큼 데이터 유실이 발생할 수 있습니다.
반면 RDB는 특정 시점의 메모리 내용을 복사하여 파일에 기록하는 방법으로 RDBMS Full Backup에 해당합니다. 따라서, 정기적 혹은 비정기적으로 저장이 필요할 시점에 데이터를 저장이 가능합니다.
RDB의 장점으로는 AOF에 비해 부하가 적으며, LZF 압축을 통해 파일 압축이 가능합니다. 또한 덤프파일을 그대로 메모리에 복원(Restore)하므로 AOF에 비해 빠릅니다. 반면 덤프를 기록한 시점이후 데이터는 저장되지 않으므로 복구시에 데이터 유실이 발생할 수 있는 문제점이 있습니다.

AOF와 RDB를 사용할 때는 유의해야할 점이 있습니다. 바로 Copy On Write입니다. AOF를 백그라운드로 수행하거나 RDB를 수행할때 redis-server에서 자식 프로세스를 fork하여 처리를 위임합니다. 만약 이과정에서 redis-server의 데이터에 쓰기 작업을 수행한다면, 기존 페이지를 수정하는 것이 아닌 이를 별도 공간에 저장 후 처리합니다. 따라서 해당 작업을 수행도중에 쓰기 작업이 증가한다면, 메모리 사용량이 급격히 증가될 수 있습니다.(최대 2배) 따라서 이를 유의해야합니다.
3. Redis 복제(Replication)
이번에는 Redis 복제에 대해서 알아보겠습니다. 먼저 복제가 필요한 이유에 대해서 먼저 알아봅시다.

Redis는 충분히 빠르고 안정적입니다. 하지만 서비스가 갑자기 잘되어 트래픽이 몰린다면 어떻게 될까요?
서버의 한계점을 넘어간다면, 인스턴스 장애가 발생할 수 있습니다. 이때 만약 단일 인스턴스로만 구성되었다면, Redis의 장애가 모든 Application에 영향을 미칩니다.
한편, Redis를 운영하는 입장에서 버전 업그레이드 혹은 서버 PM 작업이 필요하나 Application 영향도로 인해 섯불리 작업할 수 없는 문제가 생깁니다.
마지막으로, 캐시 목적으로 사용하는 Redis는 쓰기 작업보다는 읽기 작업이 주로 발생합니다. 따라서 읽기 작업 성능을 높힐 수 있는 아키텍처 구성이 필요할 수 있습니다.
이를 위해 Redis에서는 어느정도 고가용성을 확보 및 쓰기/읽기 작업 성능을 개선할 수 있는 Master/Replica 토폴로지를 제공합니다.
1. Master/Replica 구조
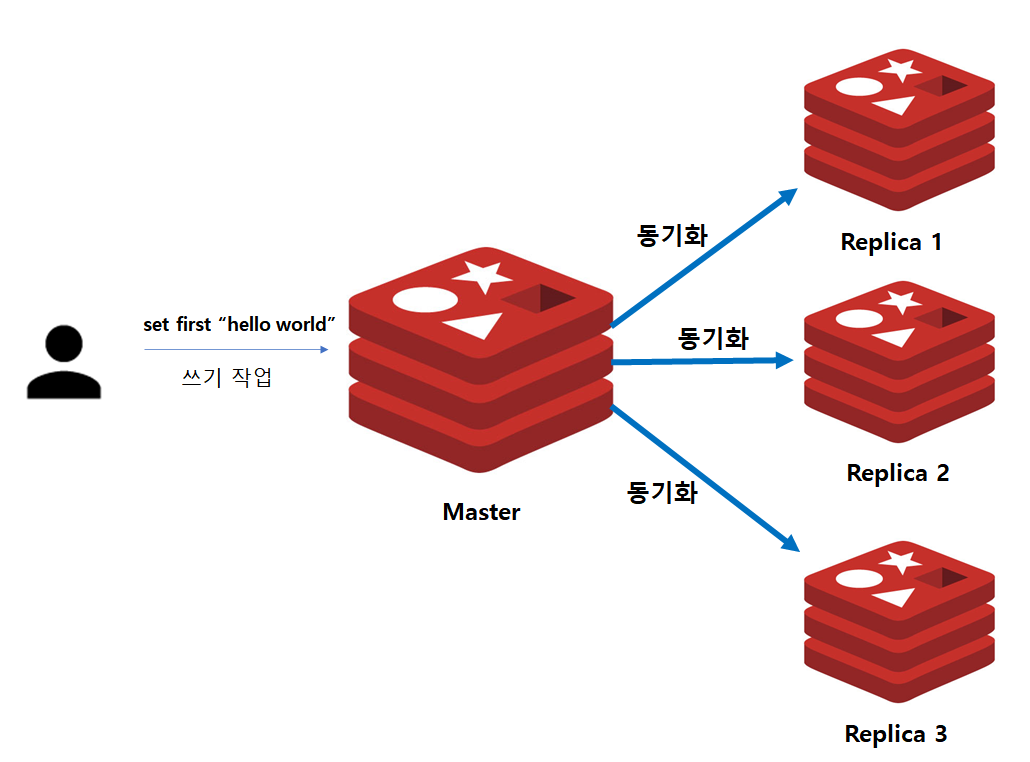
위 그림은 Master/Replica의 구조를 나타냅니다.
최초 Master/Replica 구성시 Master의 데이터는 모든 Replica에 복사합니다. 따라서 어느 Redis 인스턴스에서 데이터를 조회해도 원하는 결과를 얻을 수 있습니다.
만약 데이터의 변경이 발생한다면, 변경 작업은 Master에서만 가능합니다. 이후 변경된 데이터는 비동기적으로 모든 Replica에게 전달되어 반영됩니다.
(※ replica-read-only 옵션을 no로 설정하면, Replica 상태를 변경할 수 있으나 전체 동기화가 발생하면 모두 유실되므로 추천하지 않습니다.)
이러한 과정은 Oracle Data Guard의 SQL Apply 서비스와 유사합니다. 데이터가 아닌 문장(Statement)이 전달되므로 LuaScript가 적용된 문장이라면 Master와 Replica의 결과가 다를 수 있습니다.
2. Master/Replica 동기화 과정
이번에는 Master/Replica 동기화 과정에 대해서 살펴보겠습니다.
Replica에는 Master 노드에 적재된 데이터가 하나도 존재하지 않으므로 최초 구성시에는 전체 동기화가 발생합니다.
전체 동기화 과정은 다음과 같습니다.
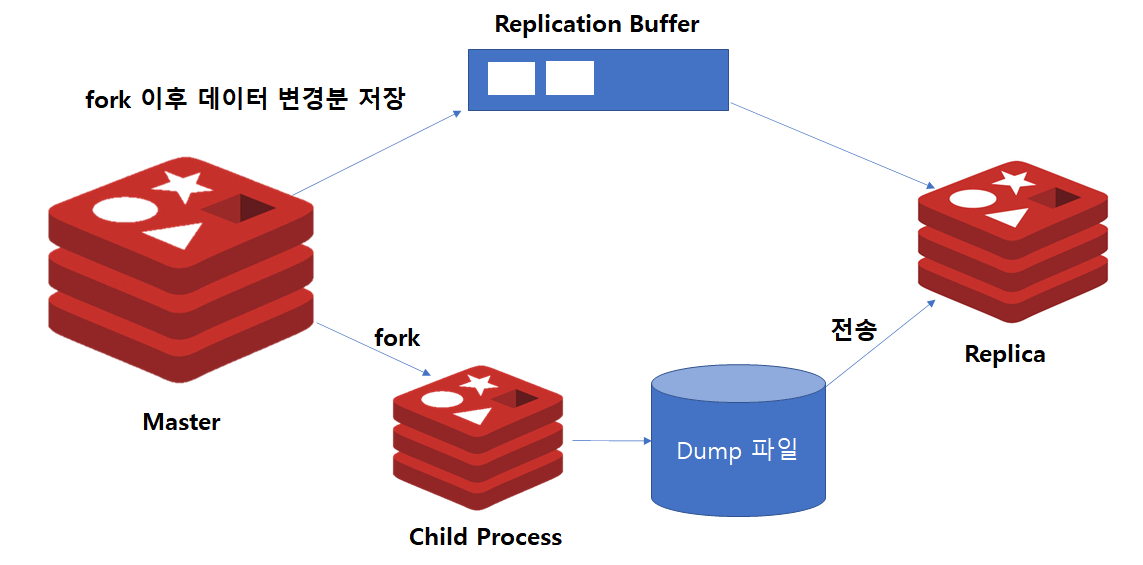
1. Master와 Replica 인스턴스를 별도로 구성합니다.
2. Replica 인스턴스에서 ReplicaOf 명령어를 통해 Master 인스턴스와의 동기화 명령을 수행합니다.
3. Master에서는 fork를 통해 자식 프로세스를 생성합니다.
4. 자식 프로세스에서는 Master 메모리에 있는 모든 데이터를 Disk로 dump 합니다.
5. dump가 완료되면, 이를 Replica에 전달하여 반영합니다.
6. Master에서는 복제가 진행되는 동안 변경 데이터를 Replication Buffer에 저장합니다.
7. Dump 전송이 완료되면, Replication Buffer의 내용을 Replica에게 전달하여 데이터를 최신상태로 만듭니다.
8. 작업이 완료되면, 이후에는 데이터 변경발생분만 비동기방식으로 전달됩니다.
최초 구성시에는 전체 동기화(Full Syncronization)이 발생하고, 이때 fork가 발생하므로 메모리 사용량이 증가할 수 있습니다. 따라서 이를 유의해야 합니다.
만약 Master/Replica 구성이 완료된 이후에 네트워크 지연이 발생되면 동기화는 어떻게 처리가 될까요?
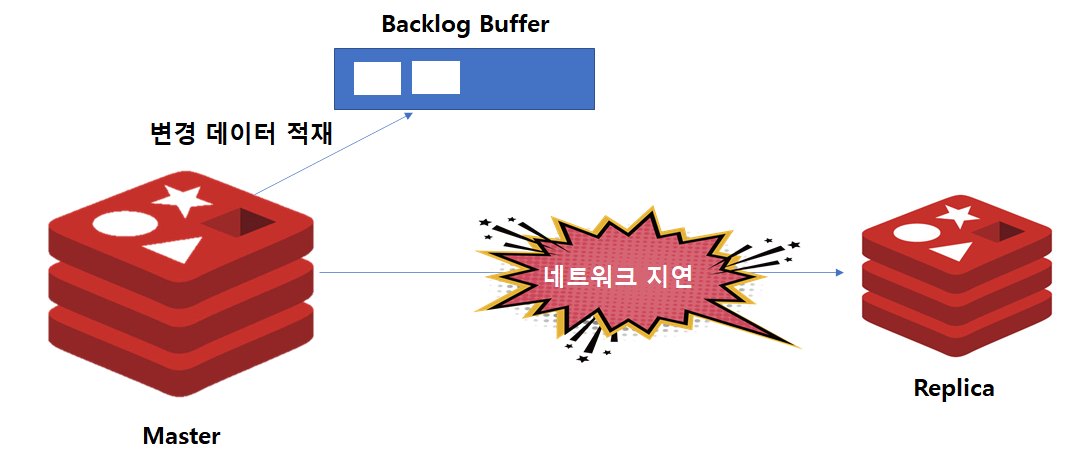
ReplicaOf 명령어를 통해 Master/Replica 구조가되면, Master 인스턴스에서는 내부적으로 repl-backlog-size 옵션 만큼의 Backlog Buffer가 만들어집니다. 이후 Replica와의 단절이 발생하게 되면, Master 인스턴스에서는 변경 데이터를 Backlog Buffer에 저장합니다. Backlog Buffer는 유한한 크기를 지녔으므로, 지연이 오랫동안 발생한다면 Buffer가 넘칠 수 있습니다.

단절 이후 다시 재연결 되었을 때 과정은 다음과 같습니다.
1. Replica에서 Master와 동기화를 위해 부분 동기화를 시도합니다.
2. 만약 Backlog Buffer에 네트워크 단절 이후의 데이터가 모두 존재하면, Buffer에있는 데이터를 전달받아 최신 상태를 만듭니다.
3. 만약 오랜 시간 네트워크 단절로 인해 Backlog Buffer에 데이터가 유실되었을 경우에는 전체 동기화 과정을 진행합니다.
ADB, RDB를 설명할때도 살펴봤지만, 프로세스 fork가 일어나게되면 메모리 사용율이 급격하게 증가할 수 있으므로 전체 동기화 작업 혹은 Replica 추가 작업시에는 모니터링과 메모리 조정등이 필요합니다.
참고 :
3. Master/Replica 장단점
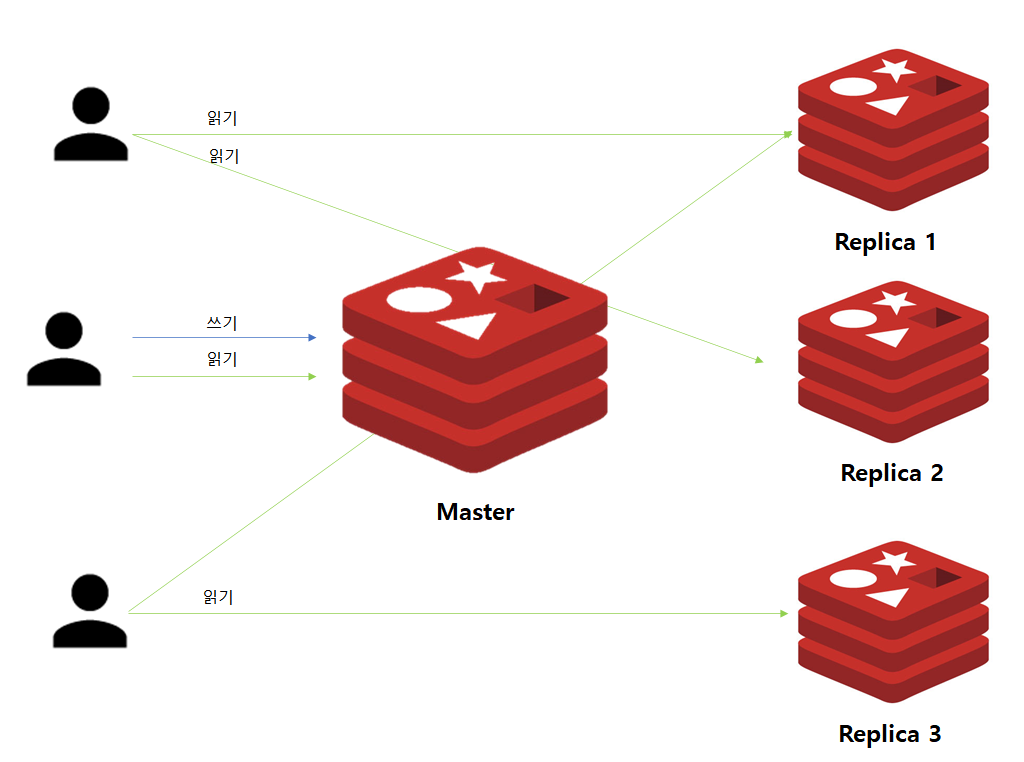
지금까지 Master/Replica 구조에 대해서 살펴보았습니다. 해당 구조의 장점은 무엇이 있을까요?
우선 Master 인스턴스와 Replica 인스턴스간 데이터가 공유되어있습니다. 따라서 Replica 중 어느 인스턴스가 다운되더라도 Application의 영향을 최소화할 수 있습니다.
또한, 데이터 조회를 위해 굳이 Master에게 요청하지 않아도 되므로 Read 작업에 대한 부하를 여러 인스턴스로 분산시킬 수 있는 장점이 있습니다.
이번에는 Master/Replica 구성했을 경우 발생되는 문제점에 대해서 살펴보겠습니다.
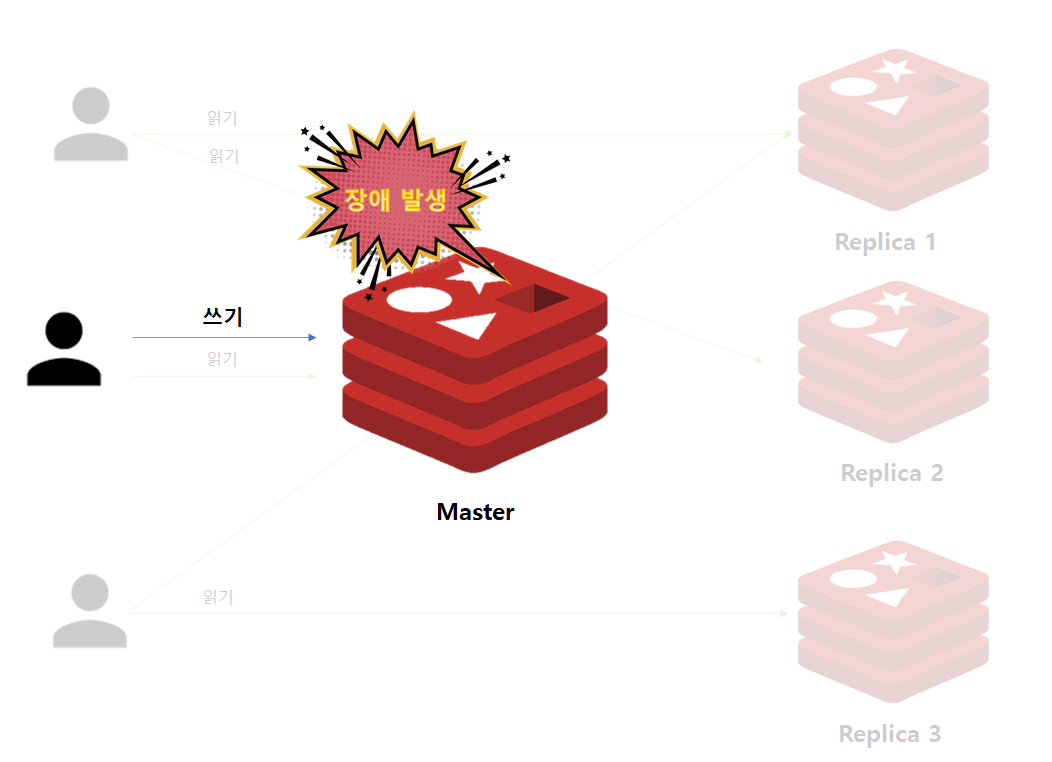
Master 인스턴스에 장애가 발생하여도 다른 Replica에 데이터가 모두 복제되어있으므로 읽기 연산은 문제가 없습니다. 하지만 쓰기 작업은 Master를 통해 이루어지므로 더이상 쓰기 작업 수행될 수 없는 문제가 있습니다.

따라서 단순 Master/Replica 구성을 했을 경우에는 관리자가 모니터링을 통해 장애 여부를 감지하고, 수동으로 Replica 인스턴스 중 하나를 Master로 선정하고, 나머지 Replica에서 새로 변경한 Master를 바라보도록 설정을 변경해야합니다.
즉 다시말해 Master 인스턴스 Crash 발생 시, 자동으로 Failover 해주지 않습니다. Master/Replica를 구성하는 이유 중 하나는 고가용성을 달성하기 위함인데, Failover를 자동으로 해주지 않는 것은 운영자 입장에서는 많이 불편할 수 밖에 없습니다.
따라서 이러한 이슈를 해결하기 위해 Redis Sentinel 기능을 제공하였습니다. Sentinel은 별도의 프로세스로 Master 인스턴스 다운시, 이를 감지하여 Replica 중 하나를 Master 인스턴스로 Failover 및 이를 Application에게 통지하는 기능을 포함하고 있습니다.
참고:
- Redis 공식 홈페이지 Sentinel 소개 자료
4. Master/Replica/Sentinel 구조
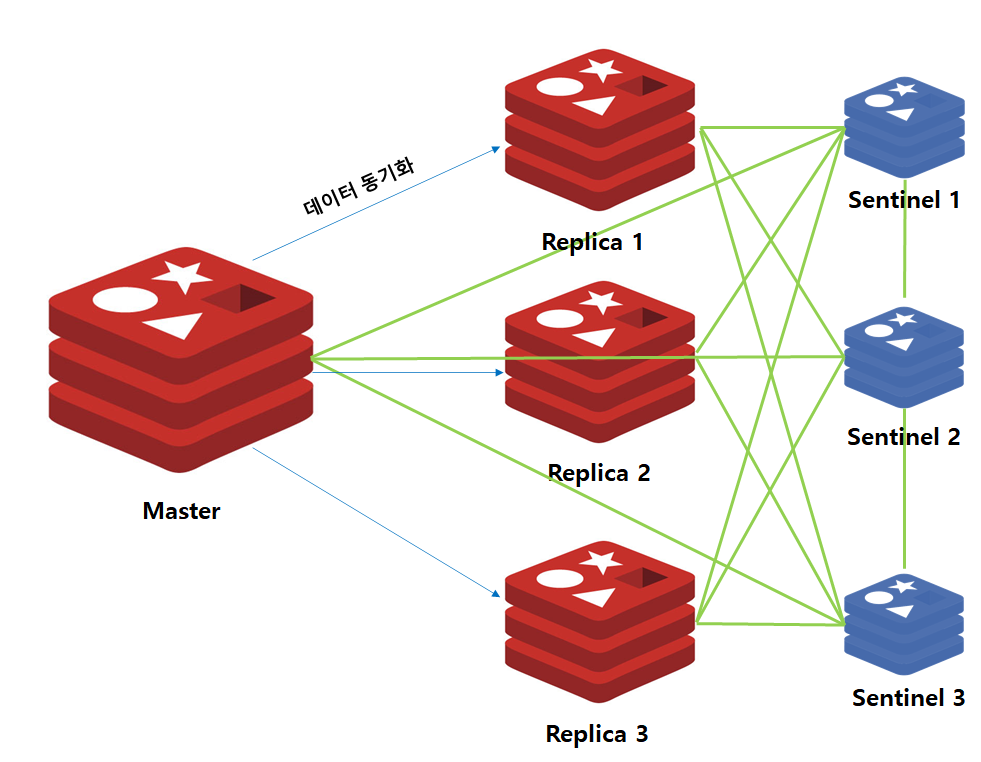
위 그림은 Master/Replica/Sentinel의 구조입니다. 여기서 녹색으로 연결된 선이 Sentinel과 연결된 네트워크 Path를 의미합니다.
Sentinel은 다른 Sentinel을 포함한 모든 Redis 인스턴스와 연결합니다. 이후 1초마다 HeartBeat 통신을 통해 Master 및 Replica 서버가 정상적으로 작동중인지 여부 확인하고 이상 발생시 자동으로 Failover 및 Application에 알림을 전송합니다.
그렇다면, Sentinel을 통해 Failover는 어떤 방식으로 이루어질까요?

Sentinel과 연결된 노드 중 HeartBeat에 일정 시간동안 응답하지 않는 경우 해당 Sentinel은 장애가 발생한 것으로 간주하고 해당 노드를 주관적 다운(Subjectively Down)으로 인지합니다.
주관적 다운으로 별도 지정한 이유는 해당 Sentinel과의 일시적인 네트워크 연결이 끊긴 것일 수도 있기 때문에 정확한 장애 여부는 아직 확정할 수 없기 때문입니다.
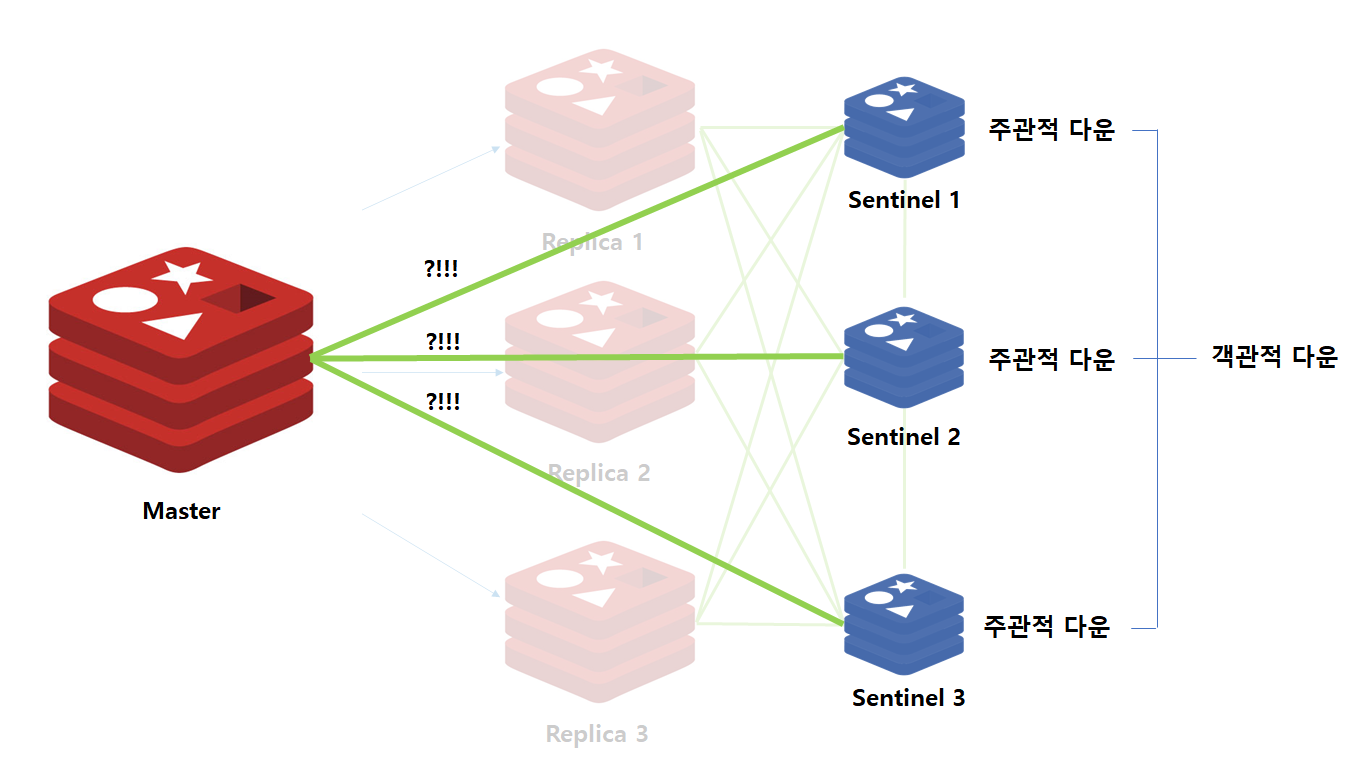
만약 장애가 발생한 인스턴스가 Master일 경우에는 모든 Sentinel에게 Master Down 여부를 묻습니다. Master Down 여부를 전달받은 Sentinel 들은 실제 Master 인스턴스가 죽었는지를 확인 후 이를 응답합니다.
이때 Master 인스턴스에 장애가 발생했다고 응답하는 비율이 정족수(Quorum)를 넘게 되면 이를 객관적 다운(Objectively Down)이라고 인지하게됩니다. 위 구조에서는 2개의 Sentinel 인스턴스가 Master 장애를 인지하게되면, 정족수를 넘게되는 것이므로 객관적 다운으로 인지하게 됩니다.
객관적 다운이 발생하게 되면, 다른 Sentinel 인스턴스와 통신하여 장애 조치 작업을 시작합니다.
Master 장애가 발생하게 되면 더이상 쓰기 작업이 안되므로 가장 먼저 해야할 작업은 새로운 Master를 선출하는 일입니다. 이를 위해서 Sentinel 프로세스는 새로운 Master 선출 권한이 있는 Sentinel 리더를 뽑는 작업을 합니다.
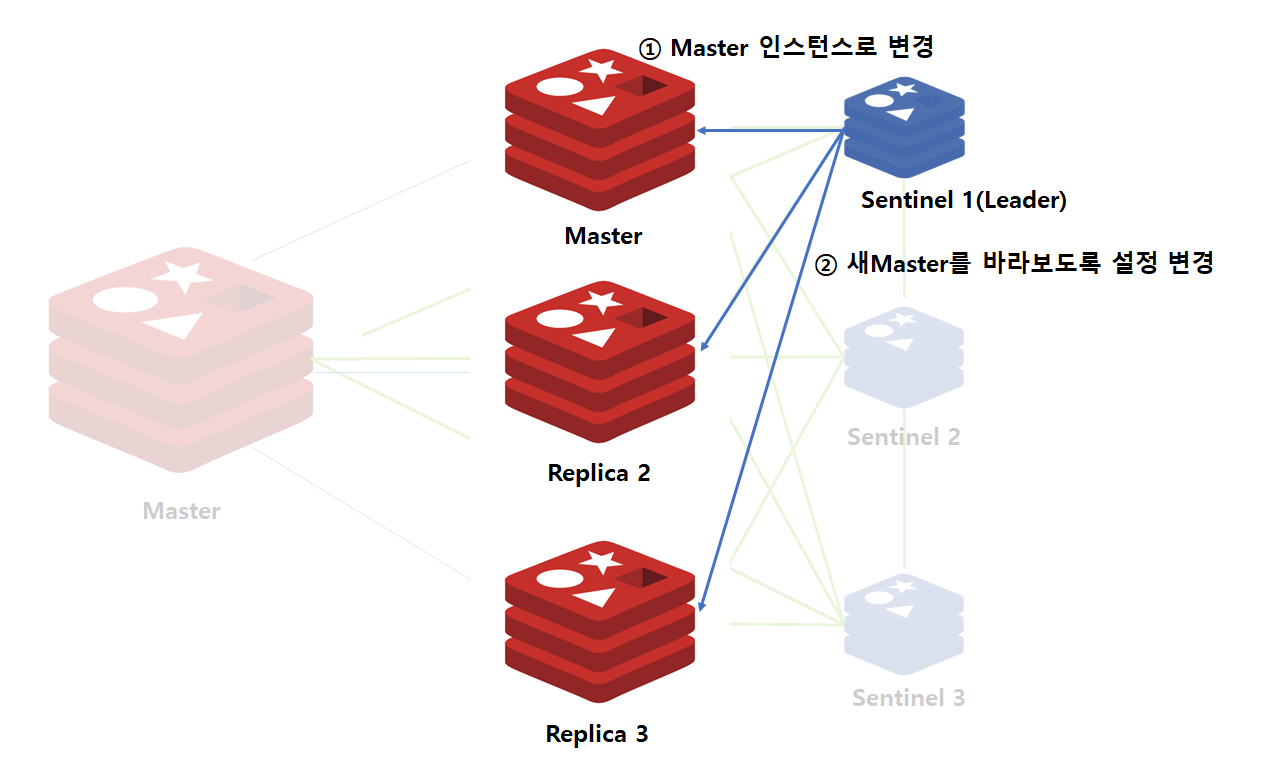
Sentinel 리더가 선출되면, 리더는 Replica 인스턴스 중 하나를 Master로 승격합니다. 이후 나머지 Replica에서 Master 인스턴스를 모니터링할 수 있도록 명령을 수행하고 장애 복구 작업을 종료합니다.
만약 기존 Master 인스턴스가 다시 살아난다면, 이미 Master가 바뀌었으므로 기존 Master는 Replica로 자동으로 변경됩니다.
이로써, 운영자의 개입없이 자동으로 Failover 하여 고가용성을 어느정도 확보할 수 있게 되었습니다.
여기서 어느정도라는 말을 쓰는 이유는 Master/Replica/Sentinel 구조에서도 데이터 유실이 발생할 수 있기 때문입니다.
예를 위해 다음과 같은 상황을 가정해보겠습니다.
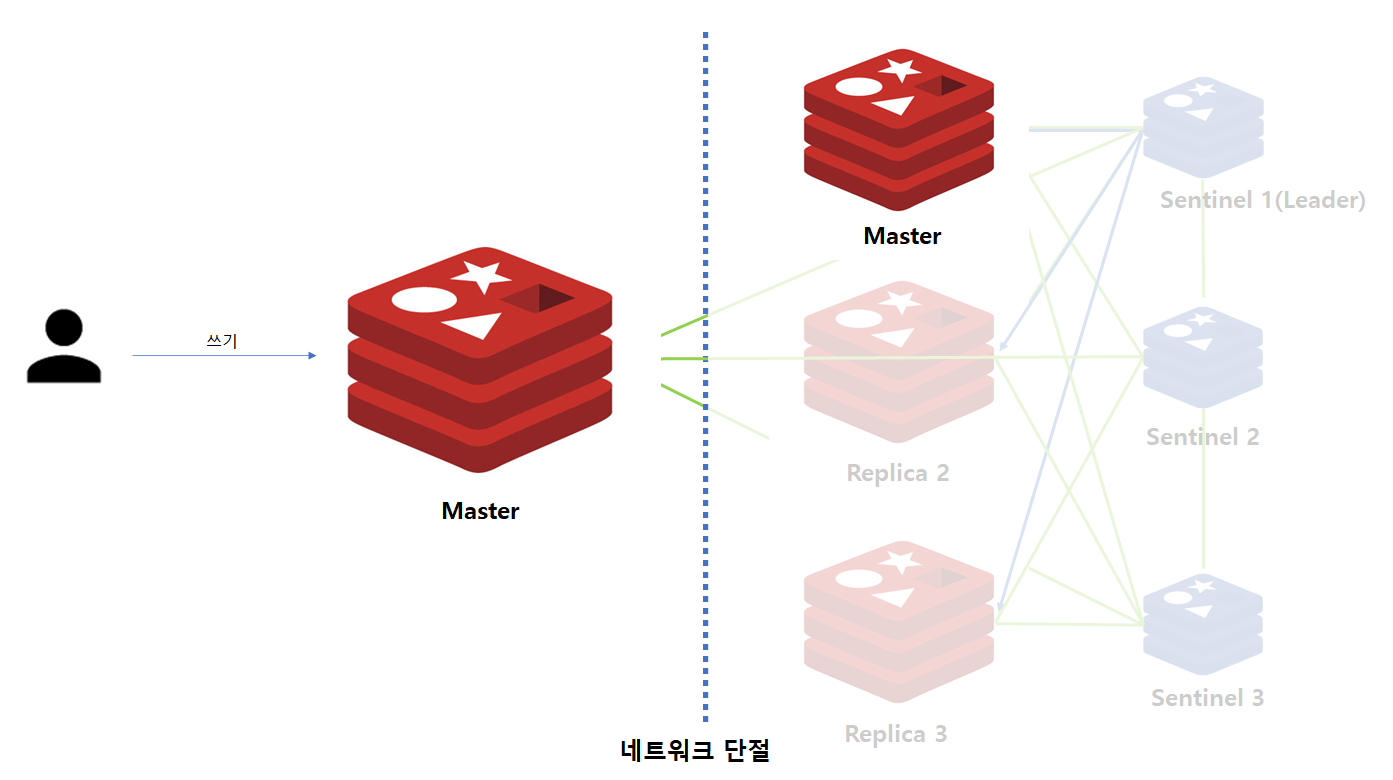
위 그림은 기존 Master 인스턴스와 나머지 Redis 인스턴스 사이 네트워크가 단절된 모습입니다. 네트워크 이슈이므로 Master 인스턴스는 현재 정상적으로 Client와 통신이 가능하며, 데이터 쓰기 작업이 발생하면 Master 인스턴스에 데이터가 저장됩니다.
하지만 Sentinel과 연결이 끊겼기 때문에 Sentinel은 Master가 죽은 것으로 판단하고 Replica 중 하나를 Master로 선출하게됩니다.
만약 이러한 상황에서 네트워크 단절 이슈가 해결된다면 기존 Master 인스턴스는 Sentinel에 의하여 Replica로 변경이 될 것이고, 이때 기존 Master 인스턴스에 새롭게 수정된 데이터는 유실됩니다.
참고:
- https://aphyr.com/posts/287-acynchronous-replication-with-failover
마치며
이번 포스팅에서는 Redis의 기본 구조와 복제에 대해서 살펴봤습니다. 다음 포스팅에서는 Redis 파티셔닝에 대해서 다루도록 하겠습니다.