
2. gRPC는 왜 빠를까? (Payload) - 1
서론
이전 포스팅에서는 gRPC에 대한 기본적인 소개를 다루어 봤습니다. 이번에는 gRPC에서 사용하는 Protocol Buffer(aka Protobuf)와 보편적으로 사용하는 JSON 메시지 포맷에 대한 비교를 통해 어떤 부분에서 Protobuf가 이점이 있는지를 살펴보겠습니다.
1. JSON, Protobuf 변환 속도 비교
이전 포스팅에서 살펴봤듯이 REST 통신에서는 JSON 규격으로 메시지를 주고 받았고 이때 발생하는 Serialization & Deserialization 과정은 비용이 소모되는 작업임을 살펴봤습니다. 반면 gRPC에서는 binary 포맷으로 데이터를 주고받기 때문에 변환 과정에 따른 비용이 JSON에 비해서 적다고 설명했습니다.
그렇다면 실제 Protobuf 변환 과정과 JSON 변환 과정을 측정해보면 얼마나 유의미한 결과를 나타낼까요? 테스트를 통해 차이가 얼마나 발생하는지 살펴봅시다.
data class PersonDto(
val name : String,
val age : Int,
val hobbies : List<String>? = null,
val address : AddressDto? = null
)
data class AddressDto(
val city : String,
val zipCode : String
)
JSON 변환 테스트를 위해 Sample 객체를 위와 같이 디자인합니다. 위 데이터 구조는 Person이라는 객체를 생성함에 있어 이름, 나이, 주소 정보를 입력받으며 취미의 경우 다수가 존재하므로 List로 입력받도록 디자인 했습니다.
syntax = "proto3";
option java_multiple_files = true;
option java_package = "grpc.polar.penguin";
message Address{
string city = 1;
string zip_code = 2;
}
message Person{
string name = 1;
int32 age = 2;
repeated string hobbies = 3;
optional Address address = 4;
}
앞서 구현한 data class에 대응되는 Proto 파일은 위와 같이 구현합니다. 아직 Protobuf에 대해서 본격적으로 다루어보지 않은만큼 syntax가 이해되지 않더라도 좋습니다.

기본 Spec을 정의하였으면 이제 변환 과정 테스트 시나리오를 정의해봅시다.
| 1. 10, 100 ... 천만번까지 10의 거듭제곱 횟수만큼 변환 과정을 수행하면서 각 단계에서 걸린 총 시간을 측정한다. 2. 단계별 warm up 과정을 추가하고 해당 단계에서의 결과는 제외한다. 따라서 단계별 50회 변환 과정을 추가한다. 3. JSON, Proto 변환 측정 과정은 다음과 같다. - JSON : DTO를 JSON Byte 배열로 변환한 다음 해당 Byte을 다시 DTO로 변환하는데 걸린 시간 - Proto : Stub을 Byte 배열로 변환한 다음 해당 Byte 배열을 다시 Stub 객체로 변환하는데 걸린 시간 |
테스트 시나리오를 위해 작성한 메인 프로그램의 흐름은 위와 같습니다. 10 부터 천만번까지 각각 변환과정을 수행한 결과를 출력하도록 구성했습니다.
측정 과정은 앞서 시나리오대로 단계별 변환 횟수에 맞추어 변환 작업을 수행하며, 단계별 최초 50회는 warm up 단계로 구성하여 결과에서 제외한 총 수행시간을 반환하도록 작성했습니다.
Stub 객체를 Byte 배열로 변환하고 이를 다시 Stub 객체로 변환하는 코드는 위와 같습니다.
DTO 객체를 JSON Byte 배열로 저장한 다음 이를 다시 Person DTO 객체로 변환하는 코드는 위와 같습니다. 이 과정에서 Parser로는 Jackson을 사용했습니다.
코드 작성은 모두 마무리되었습니다. 이제 프로그램을 수행시킨 결과를 확인해봅시다.
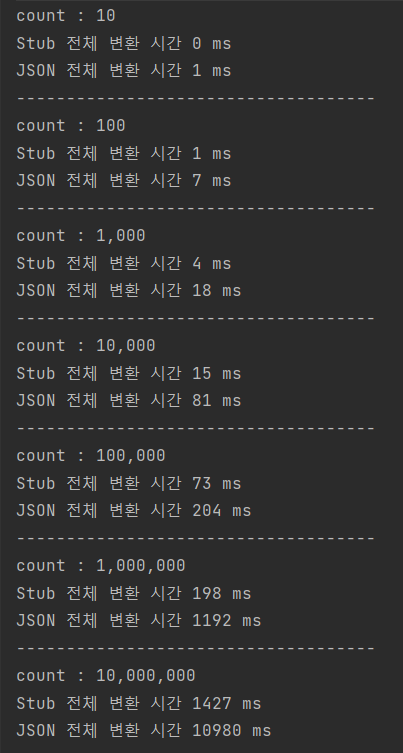
측정 결과는 위와 같습니다. 살펴보면 변환 횟수가 증가하면서 두 방식의 변환 시간의 차가 크게 벌어지는 것을 확인할 수 있습니다. 가령 천만번 변환의 경우 7배 빠른 것으로 확인되었습니다.
그렇다면 위 측정결과를 gRPC가 REST 방식에 비해 7배 빠르다고 말할 수 있을까요?

요청에 대해서 응답을 처리하는 전체 flow를 아주 간략하게 표현한다면, 위와 같이 표현할 수 있을 것입니다. 위 과정에서 오래걸리는 영역은 당연히 Business Logic 처리를 위한 수행시간일 것입니다. 따라서 Business Logic 수행 시간이 오래 걸릴 수록 격차는 현격히 줄어들 것입니다.
하지만 TPS가 높은 시스템에서는 1ms라도 응답 속도를 줄이는 것이 중요하기 때문에 이런 경우 매우 유의미한 결과라고 볼 수 있습니다.
2. JSON, Protobuf 크기 비교
이번에는 기존에 사용했던 DTO, Stub 인스턴스를 byte 배열로 변환하였을 때 크기에 대해서 비교해보고 차이점을 통해 Protobuf의 특징을 확인해보겠습니다.
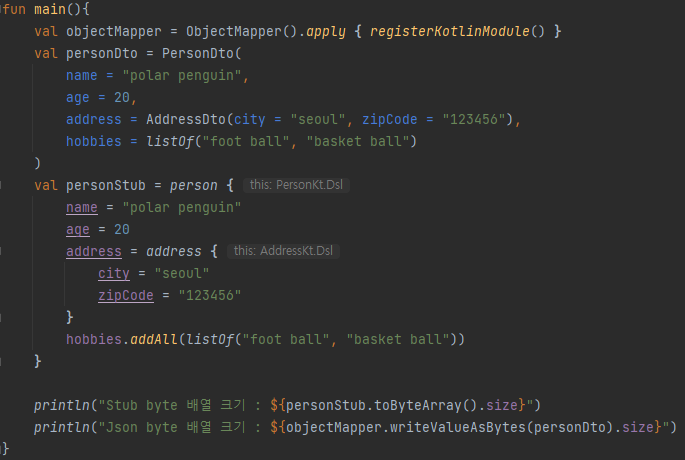
사이즈 크기 비교를 위해 작성한 프로그램은 위와 같습니다. 이전 내용과 같이 PersonDTO와 Stub 객체를 생성 후 둘 다 byte 배열로 변환한 크기를 출력하도록 구성했습니다.
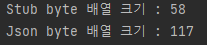
실행 결과를 보면, 동일한 데이터 입력에 있어 JSON 방식과 Proto 방식간의 결과물 크기가 상당히 차이나는 것을 확인할 수 있습니다.
이러한 차이가 발생하는 이유는 Proto 메시지 정의에 따라서 Binary 데이터를 만드는 encoding 과정에서 데이터가 압축되기 때문입니다. 이와 관련하여 자세한 기술적인 내용은 아래 네이버 기술 블로그와 구글 Protocol Encoding 공식문서를 살펴보시면 도움 되실 것 같습니다.
[NBP 기술&경험] 시대의 흐름, gRPC 깊게 파고들기 #2
google에서 개발한 오픈소스 RPC(Remote Procedure Call) 프레임워크, gRPC를 알아봅니다.
medium.com
구글 Protocol Buffer Encoding 공식 문서
Encoding | Protocol Buffers | Google Developers
Encoding This document describes the binary wire format for protocol buffer messages. You don't need to understand this to use protocol buffers in your applications, but it can be very useful to know how different protocol buffer formats affect the size of
developers.google.com
이번에는 address와 hobbies를 제거한 다음의 수행 결과를 비교해보도록 하겠습니다.
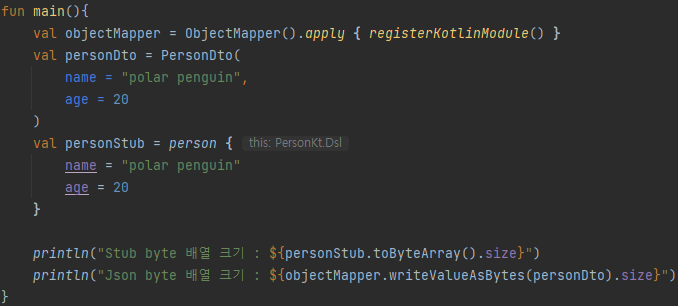
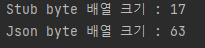
결과를 측정해보면 값이 모두 들어있을 때보다 일부 필드에 값이 입력되지 않았을 경우 Stub 객체의 Byte 배열 크기와 JSON의 결과값이 더욱 차이가 나며, 이는 전체 값을 입력했을 때 보다 압축률이 더 좋음을 의미합니다.
그렇다면 필드에 데이터가 없을 때 어떻게 압축 효율이 더 좋을 수 있을까요? 이에 대해서 한번 살펴봅시다.
{"name":"polar penguin","age":20,"hobbies":null,"address":null}
위 결과는 DTO를 JSON으로 변환한 결과입니다. 길이를 살펴보면 63바이트인 것을 확인할 수 있습니다.
결과를 통해 살펴본 흥미로운 사실은 hobbies와 address는 실질적으로 아무런 값을 입력하지 않았음에도 불구하고 JSON에서는 Key와 value를 포함시킨다는 사실입니다. 이로인해 불필요한 overhead가 추가됩니다.
반면 Protobuf의 경우는 무엇이 다를까요?
message Person{
string name = 1;
int32 age = 2;
repeated string hobbies = 3;
optional Address address = 4;
}
이전에 살펴본 Person의 proto 정의는 위와 같습니다. 그리고 테스트 프로그램에서 수행한 실제 Stub 객체에는 hobbies와 address가 포함되지 않았음을 확인할 수 있습니다.
proto 파일에서 눈여겨 볼 점은 실제 Property 옆에 표시된 field 번호가 존재하는 점입니다. 가령 name에는 1이 age에는 2가 지정되어있습니다.
해당 번호는 Protobuf의 필드를 인식하게 만들어주는 Key를 구성하는 요소입니다. 참고로 이전에 첨부한 Naver 기술 블로그나 Google 공식 문서에서는 해당 Field 번호와 Wiretype가 조합된 Key를 이용하여 Encoding 및 Decoding을 수행하여 필드 값을 Parsing 함을 자세히 확인할 수 있습니다.
그렇다면 hobbies와 address가 입력되지 않았을 때 개념적으로 어떤 변화가 발생했을까요? 먼저 개념적으로 이해하기 위해 추상적으로 어떻게 표현되었는지 살펴봅시다.

protobuf에서는 field 번호가 해당 객체 내에서 필드 값을 식별하는데 있어 주요 역할을 수행합니다. 따라서 protobuf를 설계할 때 field 별로 부여하는 field 번호는 unique 해야합니다.
결과물을 살펴보면, JSON 표현 방식에 비해서 2가지 특징을 지닌 것을 확인할 수 있습니다.
| 1. 해당 객체 값에 값이 입력되지 않았을 경우 결과물에 포함시키지 않습니다. 따라서 JSON에 비해서 Byte 배열 크기가 줄어들 수 있습니다. 2. 실제 필드명의 길이가 어떻든 관계없이 field 번호를 기반으로 Binary 데이터가 만들어지기 때문에 payload 크기가 감소됩니다. 이는 field 명이 길어질 수록 payload 크기가 커지는 JSON과 대비하여 공간을 절약할 수 있습니다. |
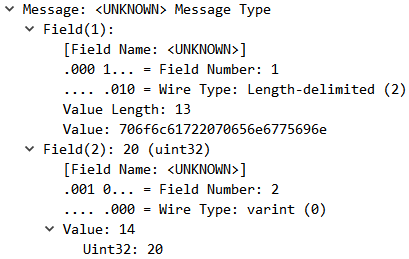
이번에는 패킷 수준에서 메시지 내용을 자세하게 살펴보겠습니다. 내용을 보면 방금전 설명했던 설명과 유사함을 확인할 수 있습니다.
데이터 구조를 살펴보면 Field Number와 Wire Type을 기반으로 ( (Field Number << 3) | Wire Type ) 형태로 Hex 값으로 구성되어 있습니다. 또한 모든 Field 내용이 저장되어있지 않고 사용자가 기입한 내용만 저장되어있는 것을 확인할 수 있습니다.

더 자세히 확인하기 위해 실제 Stub 객체에서 생성되는 Binary 내용을 해석해보도록 하겠습니다.
| 0A : name의 field 번호 1, wire type 2이므로 ( (1 << 3) | 2 ) 수행하면 10입니다. 따라서 이는 Hex 값으로 0A입니다. 0D : value의 길이를 의미합니다. 여기서 name에 저장된 값은 polar penguin 총 13자이므로 이는 Hex 값으로 0D입니다. 70 6F 6C 61 72 20 70 65 6E 67 75 69 6E : "polar penguin" 문자열의 Hex 값입니다. 10 : age의 field 번호 2, wire type 0이므로 ( (2 << 3) | 0 ) 수행하면 16입니다. 따라서 이는 Hex 값으로 10입니다. 14 : age의 값인 20입니다. 이는 Hex 값으로 14입니다. |
지금까지 Proto에 저장되는 결과를 알아보기 위해 실제 저장된 Binary 구조까지 살펴봤습니다. 모든 기술이 장점이 있으면 단점이 존재하듯이 Protobuf는 결과물이 Binary 포맷이기 때문에 결과 값을 유추하기 쉽지 않은 점은 단점이라고 볼 수 있습니다. 하지만 성능이 더 중요시되는 환경에서는 짧은 Payload는 전송 속도에 있어 강점입니다.
마치며
이번 포스팅에서는 Protobuf와 JSON을 비교하여 변환 속도와 Payload 크기 차이점을 비교해봤습니다. Protobuf는 gRPC의 핵심 요소로써 gRPC가 가지는 성능 이점의 주요 부분 중 하나라고 생각합니다. 다음 포스팅에서는 HTTP 2.0 기반으로 gRPC의 통신 방법에 대해서 살펴보겠습니다.