3. [envoy-internals] Cluster Manager - 역할
1. 서론
앞선 두 개의 포스팅을 통해 envoy 고수준 아키텍처 구조 및 쓰레딩 모델에 대해서 학습하였습니다. 이번 포스팅 부터는 Envoy의 가장 핵심이되는 주요 컴포넌트에 대해서 각 컴포넌트가 세부적으로 어떻게 구성되어있는지 그리고 컴포넌트간에 상호 작용이 어떻게 이루어지는지에 대해 자세하게 살펴보겠습니다.
참고로 이번 포스팅의 내용은 TCP 기반 설정이 구성되었다는 가정하에 작성하였습니다.
2. Envoy 구조

이 시리즈의 첫 번째 포스팅에서 Listener, Endpoint, Cluster 개념에 대해서 간략하게 살펴봤습니다. 그 중 Endpoint의 경우 Cluster와 종속적인 관계를 지니므로 Cluster에서 Endpoint를 관리합니다. 따라서 envoy의 핵심 컴포넌트를 꼽자면 Listener와 Cluster라고 봐도 무방합니다. 그렇다면 Listener와 Cluster는 누가 관리하고 어떻게 생성될까요? 위 그림을 보면 Listener Manager와 Cluster Manager가 해당 컴포넌트를 관리하는 것을 짐작할 수 있습니다.
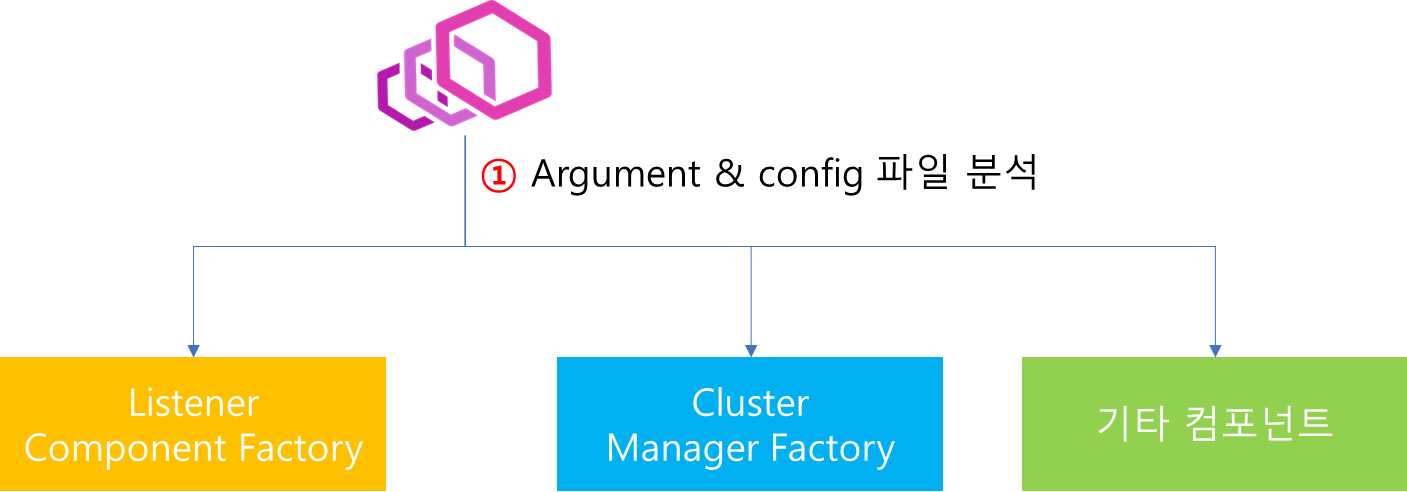
실제로 envoy server 기동 코드를 살펴보면 config.yaml 파일을 읽어서 envoy 기동에 필요한 사용자 정의 설정을 파싱하는 작업을 선행합니다. 그 이후 주요 컴포넌트 기동에 필요한 항목등을 생성합니다.
이때 위 그림을보면 Listener Component Factory와 Cluster Manager Factory를 생성하는 것을 볼 수 있습니다. 여기서 Factory라는 말에서 의미가 바로 전달되듯이 해당 Factory 들은 Listener Manager와 Cluster Manager를 생성하는데 있어 중요 역할을 수행합니다.
지금부터는 Listener Component Factory로부터 생성되는 Listener Manager의 세부 구조와 Cluster Manager Factory로부터 생성되는 Cluster Manager에 대해서 상세하게 알아보고자 합니다. 다만 이번 포스팅에서는 Cluster Manager에 대해서 중점적으로 알아보고 Listener는 다음 포스팅에서 다루겠습니다.
3. Subscription Factory 관리
Cluster Manager는 Cluster Manager Factory로 부터 생성되는 컴포넌트로써, 이름을 통해 유추할 수 있듯이 Cluster를 관리하는 역할을 수행합니다. 따라서 이에 대한 이해를 위해서는 Cluster 관리가 어떻게 이루어지는지 먼저 학습하는 것이 좋습니다. 하지만 그 전에 Cluster Manager의 주요 역할 중 하나인 Subscription Factory 관리와 gRPC Multiplexer에 대해서 먼저 다루어보고자 합니다.
이를 먼저 다루는 이유는 Cluster Manager에서 관리하는 Cluster를 등록하는 방식에는 Static 방식과 Dynamic 방식이 존재하는데, Dynamic 방식의 Cluster Update 과정에 대해 이해하려면 Subscription과 gRPC Multiplexer에 대한 이해가 선행되어야하기 때문입니다.
방금 전 언급했듯이 Cluster Manager의 역할 중 하나는 Subscription Factory를 관리하는 것이라고 설명했습니다. 그렇다면, Subscription은 무엇이고 Subscription Factory는 어떤 역할을 수행할까요? 이 부분에 대해서 살펴보겠습니다.
이전에 Envoy는 xDS API를 통한 Resource(Listener, Endpoint 등)를 관리한다고 언급한바 있습니다.

참고로 xDS API에는 gRPC, Rest API, 파일 동기화 방법이 있지만, 여기서는 gRPC 방식을 사용한다고 가정하겠습니다.
이때 gRPC 통신을 위해서 내부적으로 Multiplexer를 사용하는데, 자원 동기화 요청이 Envoy로 전달되면, 이를 수신받아 해당 Resource를 처리하는 모듈(CDS, LDS, EDS 등)에게 전달 해줘야합니다. 그리고 처리하는 모듈 쪽에서는 사전에 Callback을 등록하여 응답이 전달되면 해당 Callback을 실행할 수 있도록 합니다.

이 과정에서 중간 매개체 역할을 하는 것이 Subscription입니다. 즉 Resource를 처리하는 모듈에서 Config 대상 오브젝트 타입과 Callback을 Subscription 객체로 생성하여 등록합니다. 그리고 해당 Subscription 생성은 Subscription Factory가 수행하고, 추후 gRPC Multiplexer에 등록합니다. 이후 gRPC Multiplexer로 부터 Resource 동기화 요청이 수신되면, 해당 요청에 상응하는 Subscription의 Callback이 호출되어 데이터 동기화 처리를 수행할 수 있게됩니다.
예를 통해서 살펴보겠습니다. 가령 Listener Manager에서 LDS를 등록한다고 가정하겠습니다. 이 경우 먼저 Cluster Manager의 Subscription Factory로부터 Subscription 생성을 요청합니다. 이때 Subscription Factory는 내부 gRPC Multiplexer에 해당 정보를 등록합니다. 이후 LDS 요청 타입의 응답이 전달되었을 경우 Callback을 통해 Listener Manager에게 응답을 전달합니다.
이때 Cluster Manager는 Subscription Factory를 내부 프로퍼티로 가지고 있고, 외부의 다른 컴포넌트로부터 Subscription 생성, 삭제 등의 처리를 위임받아 처리하는 역할을 수행합니다.
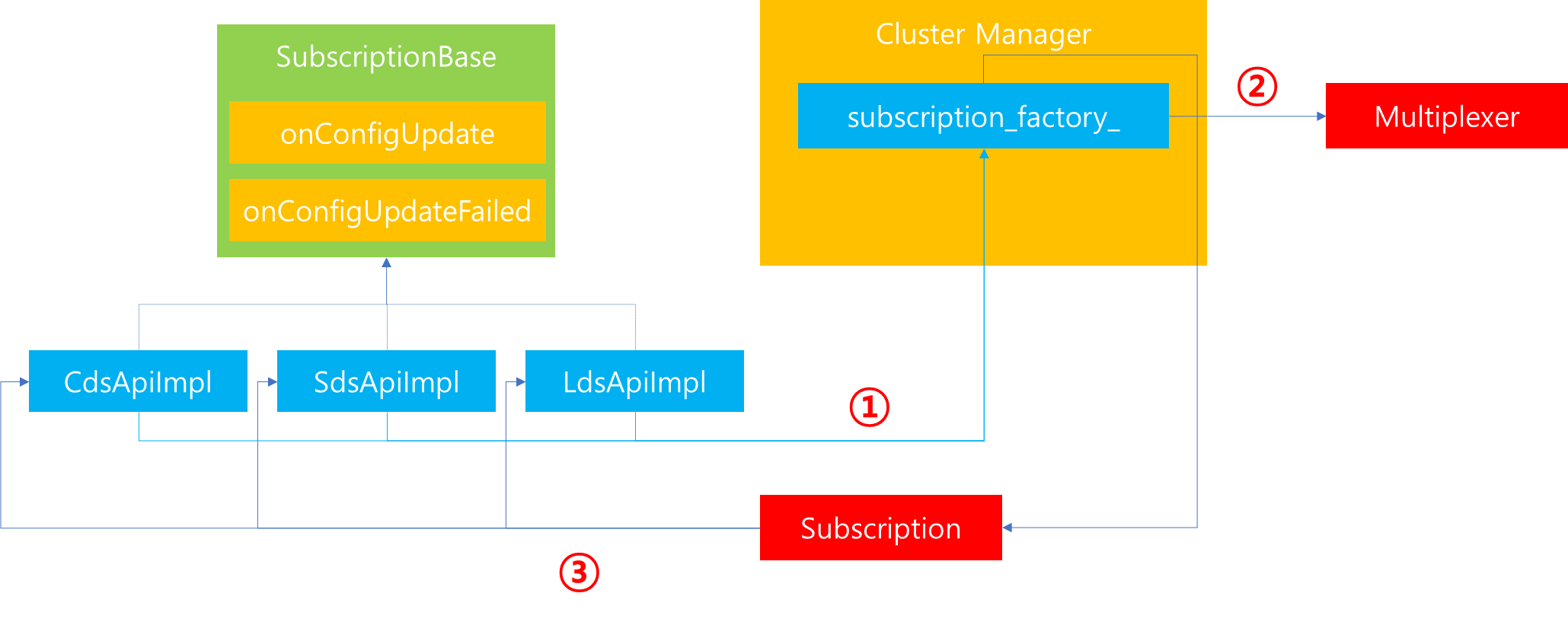
이를 조금 더 자세히 표현하면, 개별 xDS API들은 SubscriptionBase 클래스를 상속받고 있으며, 해당 클래스에는 각각 Config Update에 대하여 수행해야할 메소드들이 정의되어있습니다. 따라서 각각의 API는 구현이 요구되는 메소드들에 대해서 모듈 특성에 따라 처리방법이 기술되어있습니다. 이후 xDS API를 사용하기 위해서 Cluster Manager에 존재하는 Subscription Factory로부터 Subscription을 요청하는데, 이때 Subscription Factory 내부에서는 Multiplexer에 해당 Callback 정보를 등록하고 생성된 Subscription을 반환합니다.
4. gRPC Multiplexer
지금까지 xDS API 사용을 위해 Subscription Factory로부터 Subscription을 생성받는 과정에 대해서 살펴봤습니다. 이번에는 subscription 생성 이후 상호작용 수행하는 gRPC Multiplexer의 구성요소 및 동작 원리에 대해서 살펴보겠습니다.

gRPC Multiplexer에는 SotW를 위한 GrpcMuxSotw, Delta XDS를 위한 GrpcMuxDelta 등 여러가지 GrpcMuxImpl을 위한 구현체가 존재합니다. 그리고 해당 구현체는 공통적으로 위 3가지 컴포넌트가 내부에 존재합니다. 해당 컴포넌트가 무엇이고 어떠한 역할을 하는지 살펴보겠습니다.
1. watchMap은 외부에서 생성한 Subscription을 기반으로 gRPC 통신 수행결과를 전달받아 Callback 함수를 실행시키기 위한 자료구조로써 Watch 객체를 생성하여 저장합니다. Watch 객체에는 사용자가 지정한 Callback이 매핑되어있습니다.
2. gRPC 통신을 위해서는 SubscriptionState가 필요합니다. 해당 객체는 SubscriptionStateFactory로 부터 생성이 가능하며, SubscriptionState에는 WatchMap에 존재하는 Watch 객체를 매핑하여, 향후 gRPC 응답이 반환되었을 때 이를 전달할 수 있도록 기능이 구현되어있습니다.
3. grpcStream은 gRPC 통신을 수행하는 주체로써 외부 Management Server와 통신을 담당합니다.
gRPC Multiplexer는 여러개가 존재할 수 있는데, 개별 Multiplexer들을 관리하기 위해서 외부에 AllMuxes가 존재합니다. AllMuxes는 생성되는 여러개의 GrpcMuxImpl의 정보를 관리하기 위한 자료구조로써 hash set 형태로 생성되는 모든 GrpcMuxImpl을 관리합니다.
지금까지 gRPC Multiplexer와 관련하여 컴포넌트 정보를 확인했습니다. 아직은 gRPC를 통한 동기화 과정을 살펴보지 않았기 때문에 위 컴포넌트가 어떻게 상호작용하며 어떤 역할을 수행하는지 와닿지 않을 수 있습니다. 따라서 실제 사용자가 Subscription을 요청하여 데이터가 처리되는 과정을 살펴보면서 각각의 컴포넌트가 어떻게 연계되는지를 살펴보겠습니다.
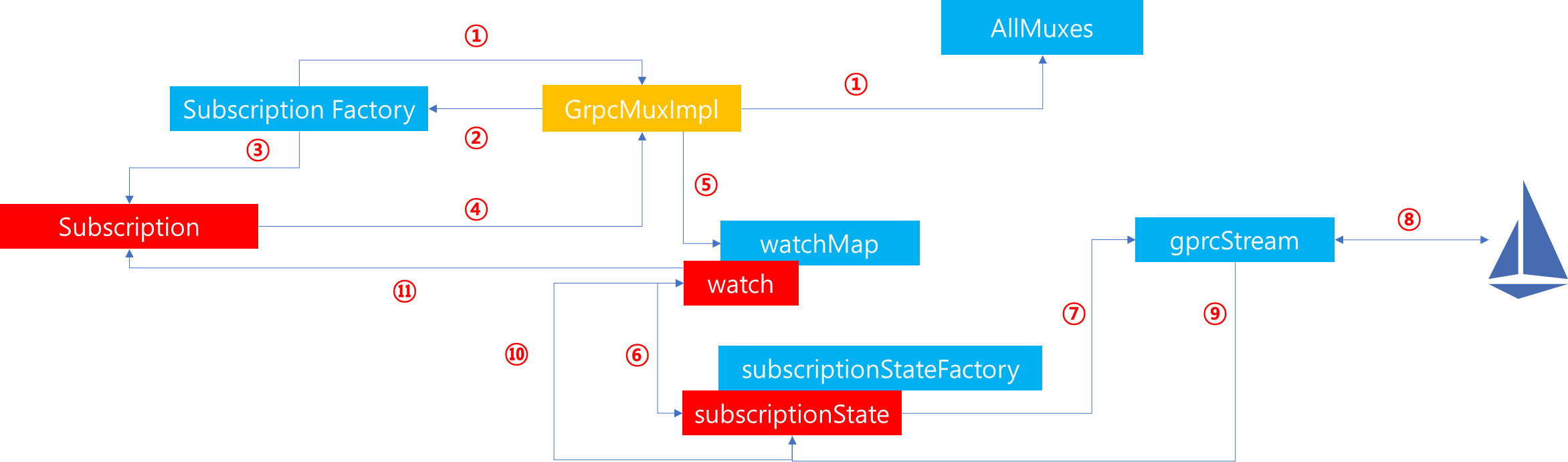
1. 이전에 설명했듯이 xDS API를 사용하려는 CDS, EDS, LDS 등은 Cluster Manager가 가지고 있는 Subscription Factory로부터 Subscription을 전달받아야합니다. 따라서 먼저 Cluster Manager로부터 Subscription Factory 정보를 얻어옵니다.
2. Subscription Factory는 CDS, EDS, LDS 등에 매핑되어있는 api_type(SotW, Delta 등)을 분석하여 적절한 GrpcMuxImpl 구현체를 반환하도록 요청합니다.
3. api_type에 따른 GrpcMuxImpl 구현체를 생성한 이후 Subscription에 해당정보를 매핑하여 반환합니다.
4. Subscription을 전달받으면, 이후 통신 수행을 위하 GrpcMuxImpl에게 통신 수행을 요청합니다.
5. GrpcMuxImpl은 WatchMap에 Subscription에서 요구하는 type_url 정보에 해당하는 Watch 정보가 존재하는지 확인합니다. 만약 존재하지 않는다면 새로운 Watch를 생성합니다. 이때 Watch에는 Subscription에 존재하는 Callback을 저장합니다.
6. WatchMap에 type_url에 해당하는 Watch 정보가 없을 경우 SubscriptionStateFactory로부터 새로운 SubscriptionState를 생성합니다. 이때 생성되는 SubscriptionState에는 5번 단계에서 생성한 Watch 정보를 포함시켜, 향후 gRPC 응답이 왔을 때 해당 Watch에게 응답 수신 행위를 수행할 수 있도록 설정합니다. SubscriptionState 생성이 완료되면, 해당 정보는 GrpcMuxImpl 내부에 존재하는 subscriptions_ 자료구조에 저장됩니다.
7. SubscriptionState를 통해 gRPC 통신을 수행을 요청합니다.
8. gRPCStream은 xDS의 Management Server(ex: istio)와 연결을 수행하여 DiscoveryRequest를 요청합니다. 이후 Management Server로부터 Discovery Response를 전달하면 이를 수신받습니다.
9. gRPCStream은 응답 메시지의 type_url을 기준으로 subscriptions_ 자료구조에서 해당 type_url에 해당하는 Subscription을 찾아 응답 메시지를 전달합니다.
10. SubscriptionState는 6번 단계에서 매핑한 Watch를 통해 응답 처리를 위임합니다.
11. Watch는 생성당시 저장된 요청자의 Callback을 수행하여 처리를 위임합니다.
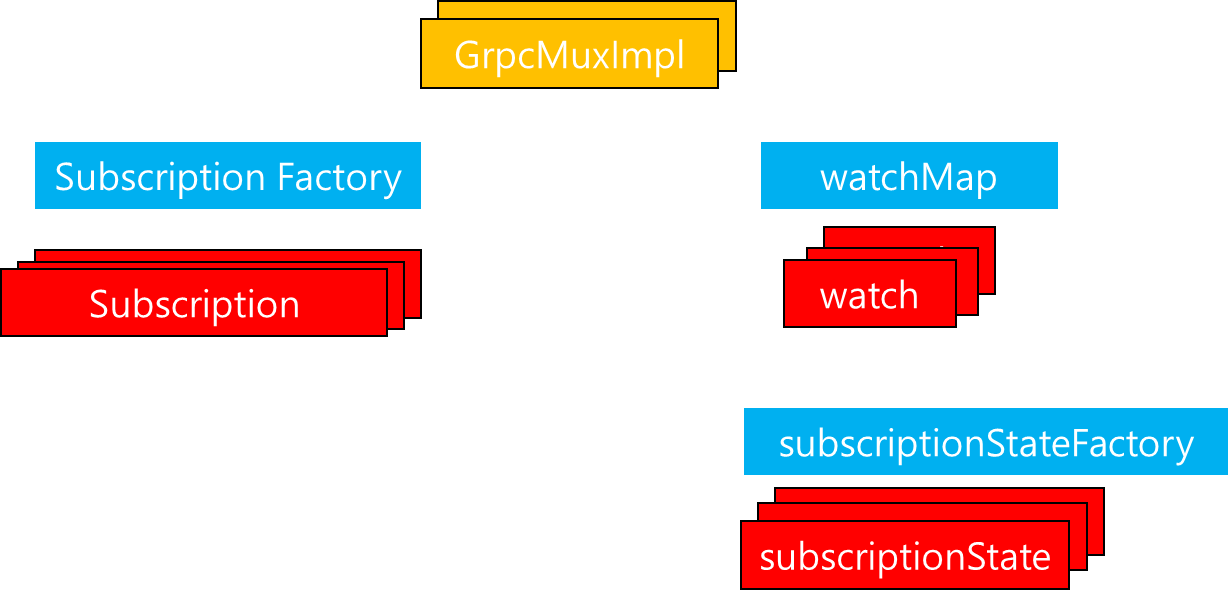
지금까지 gRPC Multiplexer에 대해서 살펴봤습니다. 이전 시나리오에서는 1개의 Subscription이 등록되고 gRPC 통신이 수행되는 과정에 대해서 살펴봤습니다. 실제로는 CDS, EDS, LDS 등 여러개의 Subscription이 존재하기 때문에 Subscription Factory에서 생성되는 Subscription은 다수가 될 수 있으며, 그에 따라 gRPC Mux 내부에는 Watch와 SubscriptionState 수가 다수가 될 수 있습니다. 마찬가지로 gRPC를 통해 수행되는 Mux 타입이 다수라면 해당 타입 또한 여러개가 될 수 있습니다.
5. Cluster 관리
지금까지 Cluster Manager의 기능 중 하나인 gRPC Multiplexer와 Subscription 관리에 대해서 살펴봤습니다. 이번에는 Cluster Manager에서 가장 핵심이 되는 Cluster 관리에 대해서 살펴보겠습니다.
Cluster Manager는 이름 그대로 Cluster를 관리하는 컴포넌트이기 때문에 가장 중요한 역할은 Cluster의 생성과 삭제 수정등을 수행하는 것 입니다.
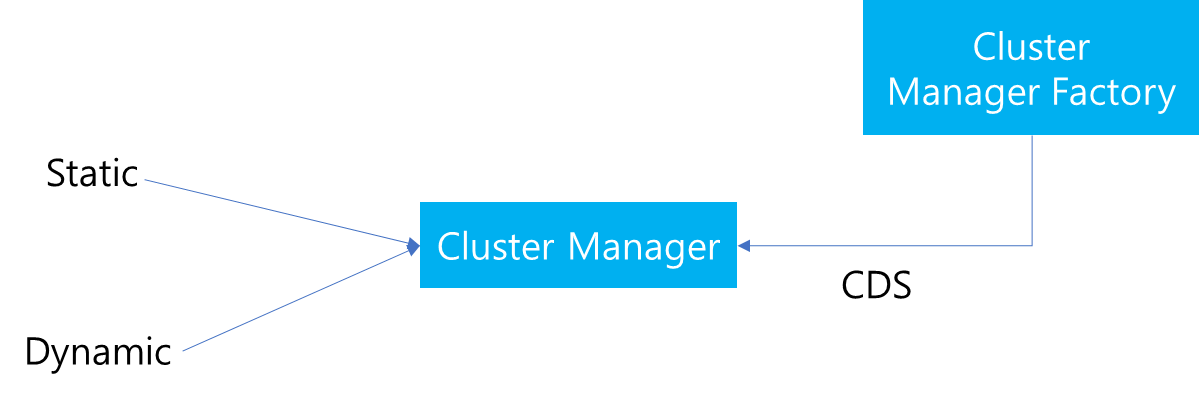
Cluster Manager는 기동 당시에 Cluster Manager Factory에 의해서 생성됨을 이전에 설명했습니다. 이때 생성 과정에서 주요하게 살펴볼 부분은 Cluster Manager 생성과 동시에 CDS 설정이 존재한다면, CDS를 생성하고 config.yaml에 존재하는 Static Resource는 Parsing 정보를 토대로 읽어들어 ClusterData를 생성하는 것입니다. 또한 이후 CDS를 통해 ClusterData 정보가 업데이트되면, 해당 정보를 Cluster Manager가 전달받아 업데이트를 수행하는 것 또한 Cluster Manager의 역할입니다.
static_resources:
clusters:
- name: local_service
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: local_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address: { address: webservice, port_value: 90 }
health_checks:
timeout: 3s
interval: 90s
unhealthy_threshold: 5
healthy_threshold: 5
no_traffic_interval: 240s
http_health_check:
path: "/ping"
event_log_path: /var/log/envoy/health_check.log
expected_statuses:
start: 200
end: 201
outlier_detection:
consecutive_5xx: 2
base_ejection_time: 30s
max_ejection_percent: 40
interval: 20s
success_rate_minimum_hosts: 5
success_rate_request_volume: 10
해당 과정에 대해서 조금 더 알아보기 위해 예를 통해서 살펴보겠습니다. 가령 위와 같이 static cluster 정보가 존재한다고 가정해봅시다. 여기서 Cluster 정보를 살펴보면, Load Balancing, Health Check, Outlier Detection 정보가 포함되어있는 것을 확인할 수 있습니다. 따라서 이를 통해 유추하자면 Envoy 내부에서 Cluster를 관리할 때 그 안에는 Load Balancing, Health Check 및 Outlier Detection을 수행하는 컴포넌트가 존재할 것이라는 것을 알 수 있습니다.
이번에는 Cluster Manager에서 Cluster를 만드는 과정에 대해서 살펴보겠습니다.

먼저 살펴볼 것은 static resource에 존재하는 cluster 정보를 Cluster Manager에서 관리하는 방법입니다. 해당 과정은 Envoy 기동 과정에서 수행되는 작업으로 생성 과정을 간략하게 살펴보면 다음과 같습니다. 먼저 envoy 기동시에 config 파일을 파싱합니다. 이후 Cluster Manager의 Cluster 저장을 위해 ClusterData 구조로 만들어서 이를 active_clusters_ 라고 불리는 map에 Cluster 정보를 저장합니다. 그렇다면 active_clusters_는 어떻게 구성되어있을까요?

해당 자료구조는 위 그림과 같이 Cluster 이름과 Cluster 정보로 이루어진 Map입니다. Cluster가 생성된 이후에 active_clusters_에 ClusterData를 추가하며, Cluster 삭제 이벤트가 발생하면 이를 삭제하는 등 해당 자료구조를 통하여 Cluster Manager가 관리하고 있는 Cluster의 종류와 갯수 현행화를 수행합니다.
이때 Map의 Value로 저장되는 것은 ClusterDataPtr으로써 파싱된 결과를 ClusterData 데이터 구조로 만들고 이에 대한 포인터 값을 저장하는데, ClusterData가 보유한 내부 속성 중 중요한 속성 설명 및 생성 과정에 대해 조금 더 자세히 알아보겠습니다.
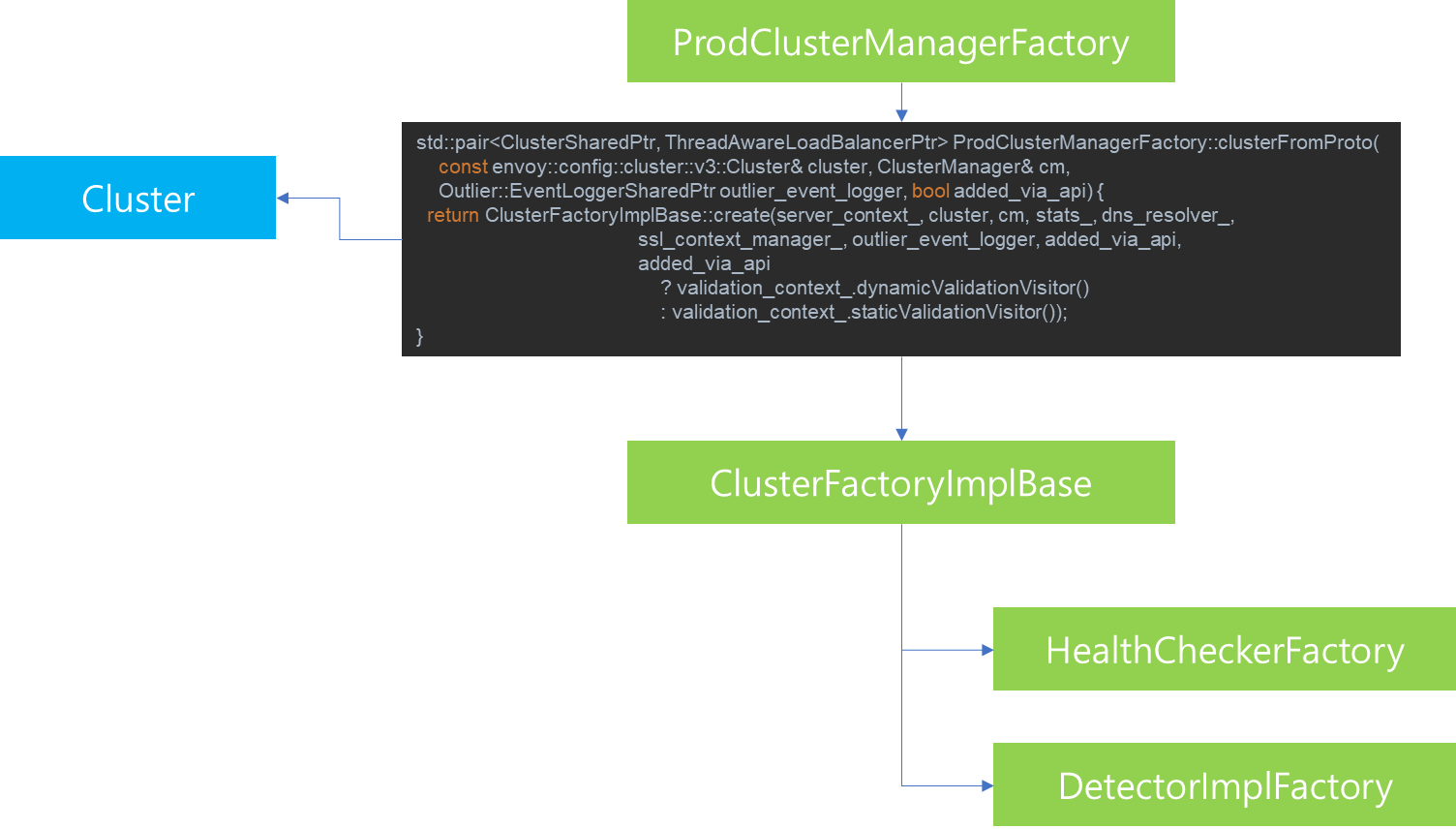
먼저 Parsing된 Cluster 정보를 토대로 ClusterData 인스턴스 생성을 위해 ProdClusterManagerFactory에게 처리를 위임합니다. 해당 Factory 내부에서는 다시 ClusterFactoryImplBase에게 Cluster 생성 주체를 위임합니다.
cluster_factory_impl.cc
std::pair<ClusterSharedPtr, ThreadAwareLoadBalancerPtr>
ClusterFactoryImplBase::create(Server::Configuration::ServerFactoryContext& server_context,
const envoy::config::cluster::v3::Cluster& cluster,
ClusterFactoryContext& context) {
auto stats_scope = generateStatsScope(cluster, context.stats());
std::unique_ptr<Server::Configuration::TransportSocketFactoryContextImpl>
transport_factory_context =
std::make_unique<Server::Configuration::TransportSocketFactoryContextImpl>(
server_context, context.sslContextManager(), *stats_scope, context.clusterManager(),
context.stats(), context.messageValidationVisitor());
std::pair<ClusterImplBaseSharedPtr, ThreadAwareLoadBalancerPtr> new_cluster_pair =
createClusterImpl(server_context, cluster, context, *transport_factory_context,
std::move(stats_scope));
if (!cluster.health_checks().empty()) {
if (cluster.health_checks().size() != 1) {
throw EnvoyException("Multiple health checks not supported");
} else {
new_cluster_pair.first->setHealthChecker(HealthCheckerFactory::create(
cluster.health_checks()[0], *new_cluster_pair.first, context.runtime(),
context.mainThreadDispatcher(), context.logManager(), context.messageValidationVisitor(),
context.api()));
}
}
new_cluster_pair.first->setOutlierDetector(Outlier::DetectorImplFactory::createForCluster(
*new_cluster_pair.first, cluster, context.mainThreadDispatcher(), context.runtime(),
context.outlierEventLogger(), context.api().randomGenerator()));
new_cluster_pair.first->setTransportFactoryContext(std::move(transport_factory_context));
return new_cluster_pair;
}
ClusterFactoryImplBase의 처리 과정을 살펴보기 위해 코드레벨로 확인해보겠습니다. ProdClusterManagerFactory로 부터 Cluster 생성 처리를 위임받은 ClusterFactoryImpl의 create 메소드내용을 살펴보면, Socket 관리, Cluster, HeathChecker, OutlierDetector를 생성하기 위해 각각의 Factory에게 처리를 위임하고 생성 결과를 전달받아 Cluster에 할당하는 것을 볼 수 있습니다. 참고로 여기서 생성되는 HealthCheker 및 OutlierDetector에 대한 자세한 설명은 조금 뒤에 다시 살펴보겠습니다.
위 코드에서 실제 Cluster 생성은 createClusterImpl 메소드내에서 이루어지며, 해당 메소드 내에서는 Proto 파일 정의에 따른 인스턴스 생성과 실제 Parsing 내용을 결합한 Cluster 인스턴스를 전달받습니다.
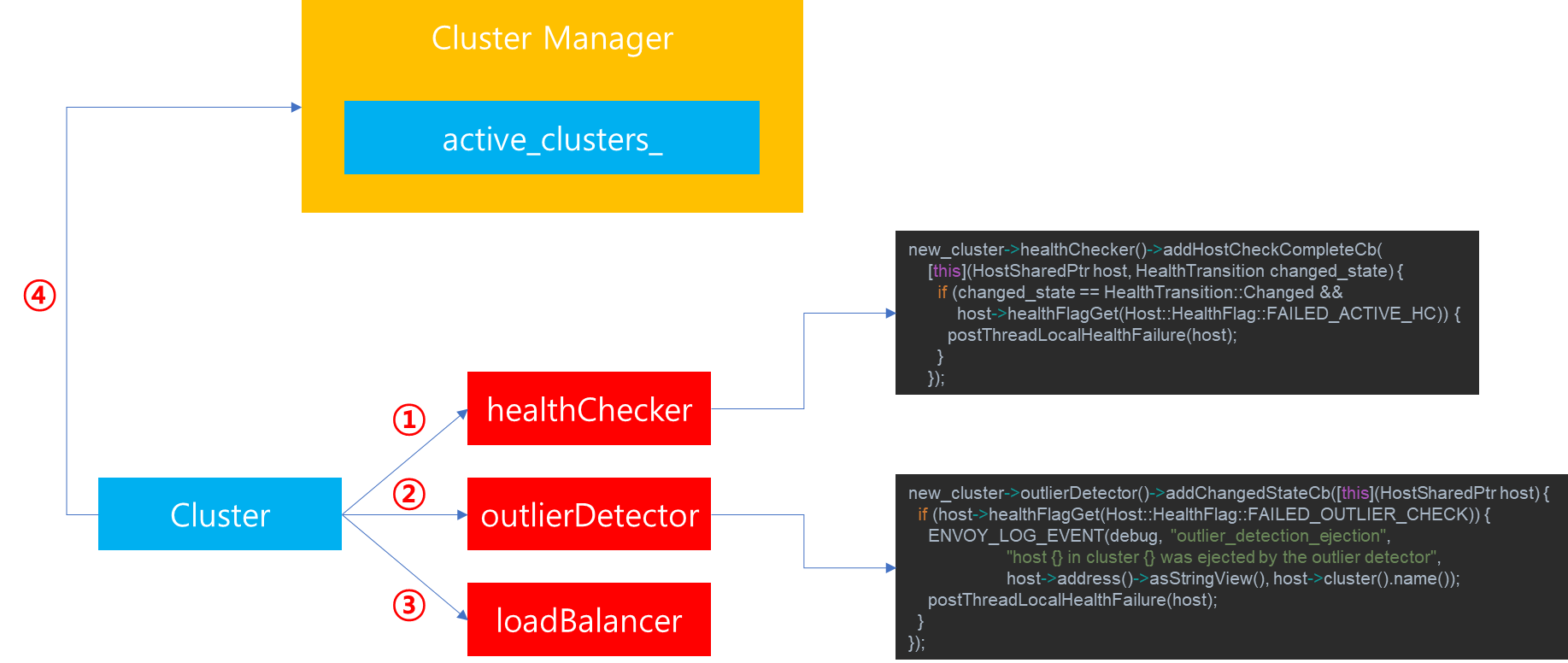
Cluster 생성이 완료된 이후에는 Cluster 인스턴스와 내부에 Parsing된 정보를 토대로 생성된 HealthChecker, OutlierDetector, LoadBalancer가 존재할 것입니다. 이후에는 다음과 과정을 추가로 거칩니다.
1. healthChecker가 등록되어있다면, hostCheckCompleteCallback 함수를 등록시킵니다. 해당 함수는 host가 Health Check가 실패했을 때, 해당 정보를 Cluster Manager에게 전달하고, 결과적으로는 해당 Cluster가 Connection Pool에서 해제하도록 후속 작업을 수행하기 위한 용도로 사용됩니다.
2. outlierDector가 등록되어있다면, changeStateCallback 함수를 등록시킵니다. 해당 함수는 만약 host가 Outlier로 판정되고, ejection 상황이라면, 해당 정보를 Cluster Manager에게 전달하고, 결과적으로는 해당 Cluster가 Connection Pool에서 해제하도록 후속 작업을 수행하기 위한 용도로 사용됩니다.
3. Callback이 모두 등록이 완료되면, Cluster에 설정된 Load Balancer를 생성하기 위한 메타데이터를 등록합니다. 이때 등록되는 Load Balancer 타입은 lb_policy에 명시된 종류에 따라 다르게 생성되며, Round Robin, Least Request, Hash Ring과 같은 타입들을 지원합니다.
4. 생성된 Cluster 정보를 Cluster Manager가 관리하는 active_clusters_ 에 추가합니다.
위 네가지 과정을 거치게되면 ClusterData 설정은 마무리됩니다. 지금까지 static resource로 등록된 Cluster 처리 과정에 대해서 살펴봤습니다. 이번에는 CDS를 통해 dynamic으로 등록되는 resource 처리 과정에 대해서 살펴보겠습니다.
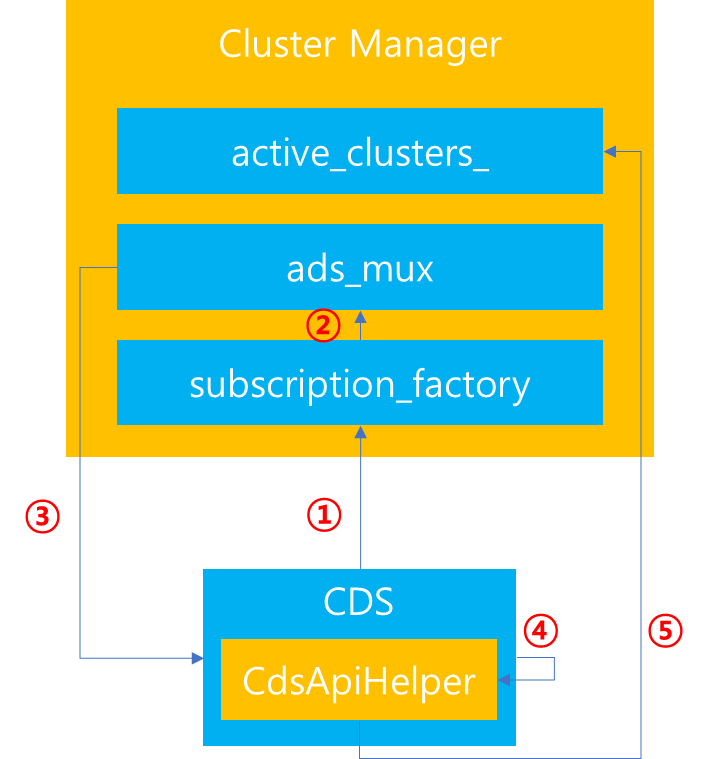
Dynamic 설정의 경우에는 CDS를 통해 처리됨을 설명했습니다. 따라서 CDS 처리를 위해서는 Cluster Manager에서 관리하는 gRPC Multiplexer(ads_mux)와 Subscription Factory와의 상호작용이 필요합니다. 이를 토대로 CDS를 통한 동기화 과정을 살펴보면 다음과 같습니다.
1. CDS 등록을 위해 가장 먼저 Cluster Manager에 존재하는 Subscription Factory로부터 Subscription을 요청합니다.
2. Subscription Factory는 Subscription을 반환하기 CDS가 전달받기 희망하는 Resource 타입에 대한 데이터 요청 및 Callback 처리를 위해 Multiplexer에 이를 등록합니다.
3. CDS가 요청하는 Resource 타입 등록 및 해당 Subscription을 CDS에 반환합니다.
4. 외부에서 Cluster 변화(생성/삭제/수정)가 감지되어 Envoy에 통지되면 해당 내용이 Multiplexer를 지나 Callback을 통해 CDS로 전달될 것입니다. 이때 CDS 내부에서는 이를 처리하기 위해 CdsApiHelper에게 처리를 위임합니다.
5. CdsApiHelper에서는 해당 내용을 정제합니다. Cluster Manager에 위치한 active_clusters_에 해당 내용을 반영합니다.
만약 기존 Cluster의 업데이트라면 해당 내용을 수정하고, 신규 추가라면 Cluster 정보를 active_clusters_에 추가할 것입니다.
5-1. Cluster Entry
지금까지 Static 방식과 Dynamic 방식을 통해서 Cluster Manager가 Cluster를 관리하기 위해 사용되는 active_clusters_에 Cluster 정보를 현행화하는 방식에 대해서 살펴봤습니다. 하지만 여기서 active_clusters_에서 값으로 관리되는 ClusterData는 Cluster의 역할 중 핵심 기능을 포함하고 있지 않습니다.
그렇다면 Cluster가 제공하는 핵심 기능은 무엇일까요?

Cluster 의 가장 중요한 기능 중 하나는 Client가 Cluster 내에 존재하는 여러 B/E host와의 연결을 시도할 때, 중간에서 Client의 연결과 B/E의 연결을 이어주는 Connection Pool 인터페이스 기능을 제공한다는 점입니다.
해당 기능은 active_clusters_가 관리하는 ClusterData에서 이를 제공하지 않습니다. 따라서 Cluster Manager에서는 active_clusters_ 를 Cluster 변경이 생겼을 때(CDS) 관리하는 메타데이터 용도로써 내부적으로 관리하고 외부와의 Cluster 연결 등에는 별도 자료구조(thread_local_clusters_)와 ClusterData를 확장한 ClusterEntry를 통해서 Connection Pool 관리 기능과 Load Balancer 기능을 제공합니다.
따라서 이번에는 Static, Dynamic 방식을 통해서 active_clusters_에 등록된 이후 진행되는 후속 과정과 이를 통해서 생성되는 ClusterEntry 및 ClusterEntry를 관리하는 thread_local_clusters_ 에 대해서 살펴보겠습니다.

Cluster Manager를 구동하는 과정에서 수행하는 작업 중 하나는 Main 쓰레드에 존재하는 Dispatcher를 통해 TLS를 할당받는 것입니다. 이때 생성하는 Slot은 ThreadLocalClustManagerImpl 로써, 외부에 존재하는 모듈이나 내부에서 Cluster 데이터 동기화를 수행할 때 해당 Slot에 존재하는 인스턴스를 활용합니다.
그리고 Cluster Manager 내부에는 thread_local_clusters_라고 불리는 Map이 존재하는데, 해당 Map은 Key로써는 Cluster의 이름을 Value는 ClusterData를 기반으로 만들어진 ClusterEntry를 가지고 있습니다. 즉 이전에 설명했듯이 Connection Pool 기능과 실질적인 LoadBalancer 인스턴스를 지니고 있는 ClusterEntry를 해당 자료구조가 가지고 있으며, 외부 모듈에서는 thread_local_clusters_ 접근을 통해 Cluster Manager가 보유하고 있는 Cluster 정보에 대해 참조가 가능합니다.
그렇다면 Static, Dynamic 등록을 통해서 active_clusters_에 생성된 Cluster 정보를 기반으로 어떤 시점에 thread_local_clusters_를 만들어낼까요? ClusterEntry 생성과 thread_local_clusters_ 삽입 과정을 통해서 이해해보겠습니다. 먼저 Static Cluster 등록부터 살펴보겠습니다.

Static Resource가 모두 등록되면 해당 ClusterData는 모두 active_clusters_에 저장되어있을 것입니다. 이후 Cluster Manager 설정이 끝나게되면, active_clusters_를 순회하면서 초기화 작업을 진행합니다.
이때 수행하는 작업은 크게 4단계로 이루어져있습니다.
1. 개별 ClusterData를 순회하면서 Cluster에 멤버가 추가되거나 우선순위가 변경되었을 때 후속 작업을 수행하기 위한 Callback을 등록합니다.
2. 등록되어있는 Callback의 역할은 Cluster Manager가 여러개일 경우 개별 Cluster Manager에서 보유중인 local cluster를 업데이트 하는 것입니다. 따라서 Cluster Manager 동기화를 위해 TLS Slot에 저장된 ThreadLocalClusterManagerImpl을 참조하여 후속 작업 처리를 요청합니다.
3. Callback 등록이 완료되면, thread_local_clusters_에 Cluster를 생성하기 위해 TLS Slot에 저장된 ThreadLocalClusterManagerImpl를 참조하여 모든 Cluster Manager에게 Cluster 생성에 대한 내용을 통지하고 이를 전달받은 Cluster Manager에서는 ClusterEntry를 생성하여 자신의 thread_local_clusters_에 저장합니다.
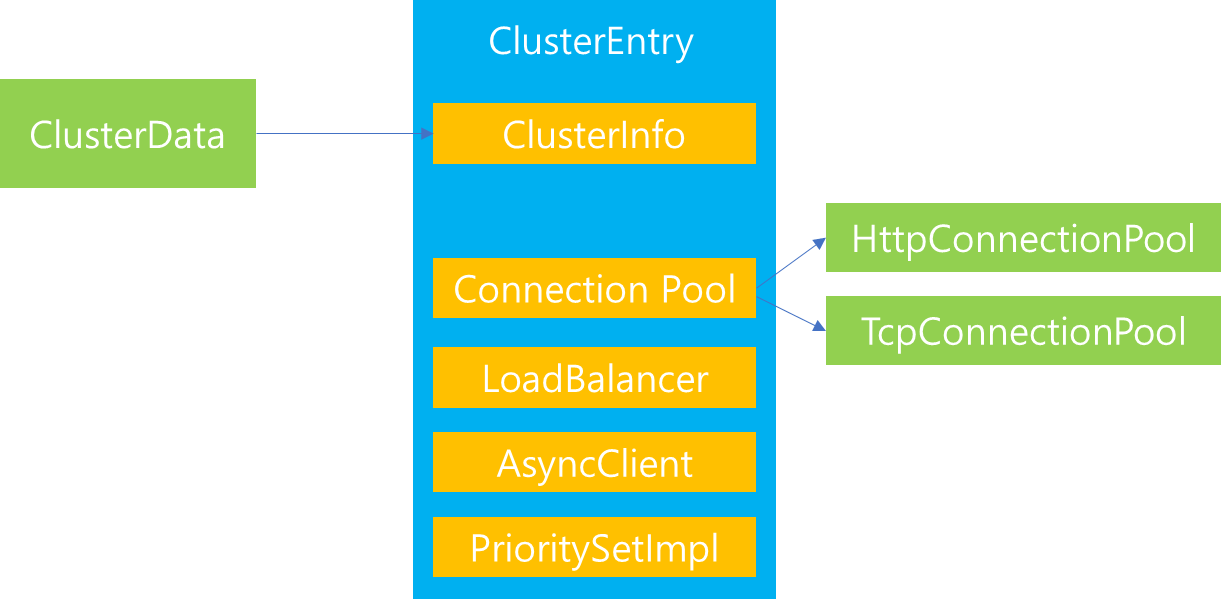
ClusterEntry는 ClusterData에 저장된 info 정보를 포함하고 있으며, 내부에는 클러스터 관리를 위한 여러 속성이 존재합니다. 그 중 몇개만 소개하자면, 먼저 Connection Pool에 접근할 수 있는 인터페이스 기능 제공을 포함합니다. 그리고 등록된 B/E의 host 및 우선순위를 관리하기 위한 PrioritySetIml이 있습니다. LoadBalancer는 해당 Cluster에 대해 외부에서 사용자 접속 요청이 들어왔을 때 실질적으로 LoadBalancer를 수행하기 위한 인스턴스가 매핑되며, AsyncClient를 통해서 Upstream과 연결을 수행합니다.
4. 만약 Cluster의 변경에 대하여 외부에서 통지를 받기위해 Callback을 등록했었다면, Cluster 변경에 대한 통지를 외부에게 알립니다.
위와 같은 과정을 거쳐 Static Resource로 등록한 자원들이 active_clusters_에 최초 저장이되고 이를 토대로 다시 전체 Cluster Manager에서 Cluster Entry를 만들고 이를 자신의 thread_local_clusters_에 저장함으로써 Cluster 관리가 이루어집니다. 또한 이후에는 외부에서 Cluster 접근을 요청할 때 thread_local_clusters_를 통해서 해당 Cluster 정보 참조가 가능해집니다.
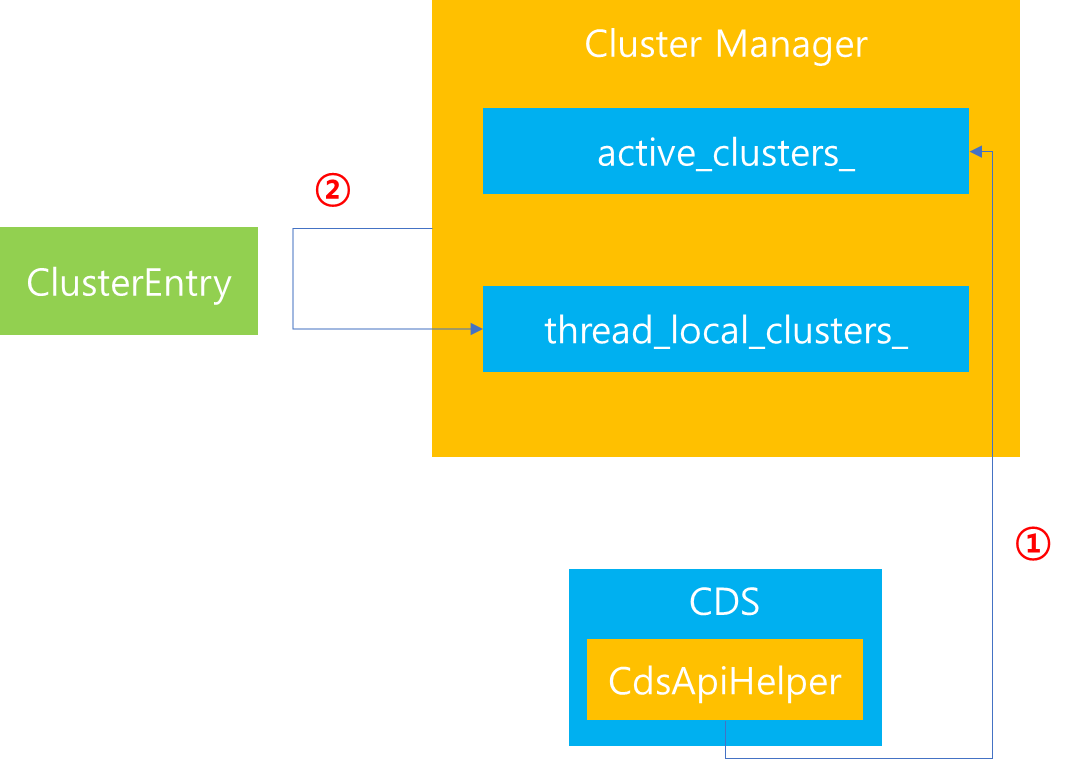
Dynamic Resource 등록의 경우 이전에 active_clusters_ 에 추가함을 설명했는데, 이 과정에서 Cluster 초기화를 후속 진행합니다. 이때 ClusterEntry가 생성되고 해당 데이터가 thread_local_clusters_에 추가되면서 Cluster Manager에서 Cluster 동기화가 이루어집니다.
5-2. Connection Pool 관리
이번에는 Cluster Entry 내부에 있는 ConnectionPool 인스턴스를 통해서 Cluster Manager가 어떻게 Connection Pool을 관리하는지에 대해서 살펴보고자 합니다. 여기서 Connection Pool 관리는 Cluster Manager가 하며, 외부에서는 Cluster Entry를 통해 Cluster Manager에서 관리하는 Connection Pool 획득 및 해제등의 요청을 수행할 수 있습니다. 따라서 이 부분에 대해서 자세히 알아보도록 하겠습니다.

Cluster Manager 내부에는 Connection Pool을 관리하기 위한 map이 여러개 존재합니다. 그 중 host_http_conn_pool_map은 http 요청 관련 Connection Pool을 관리하며, 그 밖에 TCP 기반으로 Connection이 이루어지는 요청의 경우는 host_tcp_conn_pool_map을 통해 Connection Pool을 관리합니다. 본 포스팅에서는 Http 연결 요청에 대한 처리만을 다루고 있으므로 Cluster Manager에서 관리하는 host_http_conn_pool_map에 대해서만 설명하겠습니다.
host_http_conn_pool_map은 이름을 통해 알 수 있듯이 Map 자료구조입니다. 이는 HostPtr을 Key로 하며, Value는 Connection을 관리하기 위한 Container로 구성되어있습니다. 그리고 해당 Container 안에는 Connection Pool Map이 별도로 존재합니다.
따라서, 외부에서 Connection 연결을 시도하기 위해서는 먼저 host를 기반으로 host_http_conn_pool_map으로 부터 Container를 획득해야하며, 그 안에 존재하는 Connection Map을 통해 Connection 할당 및 해제를 수행할 수 있습니다.
그렇다면 Connection 할당 및 해제는 언제 어떻게 이루어질까요?
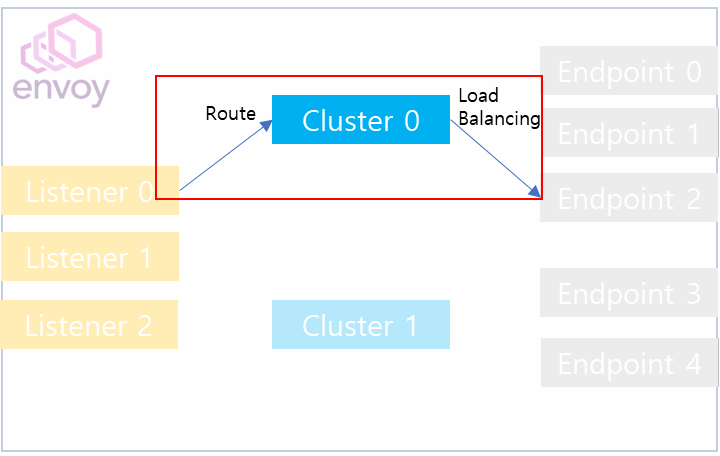
Envoy 관련 첫 포스팅 때, Envoy의 내부 흐름은 위와 같이 진행된다고 설명한 적이 있습니다. 여기서 Listener를 통해 Cluster에 접근하고 Load Balancing을 수행하는 과정에서 Cluster Manager를 통해 Endpoint 즉 host가 지정됩니다. 그리고 이 과정에서 Connection Pool로부터 Connection을 할당받아 요청을 전달할 수 있습니다. 정리하자면 Connection Pool로부터 Connection을 할당 받는 시점은 Load Balancing이 완료된 이후입니다.
위 그림으로 표시된 영역을 조금 더 자세히 확대하여 구체적으로 내부 컴포넌트가 어떻게 연계되는지 살펴보겠습니다.
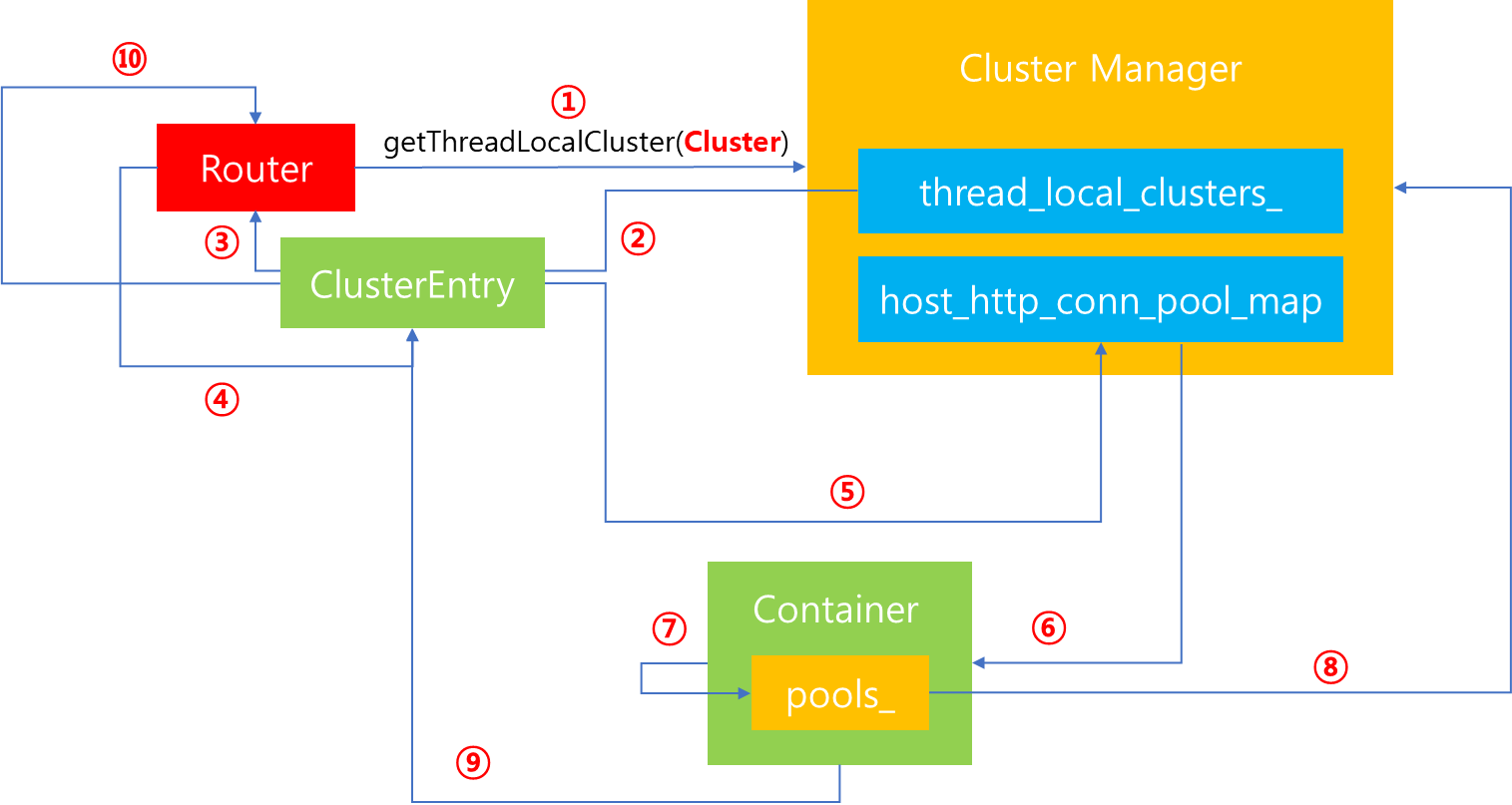
1. Listener를 거쳐 Router에 도달하게되면, Client의 요청이 어떤 Cluster에게 전달되어야하는지 이미 알고 있습니다. 따라서 Router에서는 Cluster Manager에게 자신이 접근하고자 하는 Cluster 정보를 요청합니다.
2. Cluster Manager는 자신이 보유하고 있는 thread_local_clusters_ 에서 Router가 요청한 Cluster 정보를 찾습니다.
cluster_manager_impl.cc
ThreadLocalCluster* ClusterManagerImpl::getThreadLocalCluster(absl::string_view cluster) {
ThreadLocalClusterManagerImpl& cluster_manager = *tls_;
auto entry = cluster_manager.thread_local_clusters_.find(cluster);
if (entry != cluster_manager.thread_local_clusters_.end()) {
return entry->second.get();
} else {
return nullptr;
}
}

참고로 이때 thread_local_clusters_에 저장된 값은 ClusterEntry이지만, ClusterEntry는 ThreadLocalCluster를 상속받기 때문에 리턴 타입은 ThreadLocalCluster로 하여 ThreadLocalCluster에서 제공되는 메소드만 호출 가능합니다.
3. Cluster Manager로 부터 ThreadLocalCluster를 찾아서 Router로 반환합니다.
4. Router에서는 Cluster내에 존재하는 host를 통해 Connection 연결을 수행해야되기 때문에, 전달받은 ThreadLocalCluster를 통해 Connection Pool 할당을 요청합니다.
5. 이를 전달받은 ThreadLocalCluster(ClusterEntry)는 Cluster Manager에게 요청하여 host_http_conn_pool_map 에 할당 받은 Connection Pool이 존재하는지를 확인합니다. 만약 존재한다면 해당 Connection Pool Map에 있는 Container에 접근합니다. 반면 존재하지 않는다면 새로운 Container를 생성하여 해당 Map에 추가합니다.
7. Container 내부에는 Cluster 별로 Connection을 관리하는 Pool을 가지고 있습니다. 그리고 여기에서 Pool 존재여부를 최종적으로 확인하고, 해당 Pool을 반환합니다. 해당 과정을 코드로 살펴보면 다음과 같습니다.
conn_pool_map_impl.cc
template <typename KEY_TYPE, typename POOL_TYPE>
typename ConnPoolMap<KEY_TYPE, POOL_TYPE>::PoolOptRef
ConnPoolMap<KEY_TYPE, POOL_TYPE>::getPool(const KEY_TYPE& key, const PoolFactory& factory) {
Common::AutoDebugRecursionChecker assert_not_in(recursion_checker_);
auto pool_iter = active_pools_.find(key);
if (pool_iter != active_pools_.end()) {
return std::ref(*(pool_iter->second));
}
ResourceLimit& connPoolResource = host_->cluster().resourceManager(priority_).connectionPools();
// We need a new pool. Check if we have room.
if (!connPoolResource.canCreate()) {
// We're full. Try to free up a pool. If we can't, bail out.
if (!freeOnePool()) {
host_->cluster().stats().upstream_cx_pool_overflow_.inc();
return absl::nullopt;
}
...(중략)...
}
auto new_pool = factory();
connPoolResource.inc();
for (const auto& cb : cached_callbacks_) {
new_pool->addIdleCallback(cb);
}
auto inserted = active_pools_.emplace(key, std::move(new_pool));
return std::ref(*inserted.first->second);
}
active_pools_가 Container가 보유하고 있는 Pool을 의미합니다. 해당 과정을 살펴보면, 먼저 Container 내부에서 관리하는 active_pools_에서 해당 pool이 존재하는지를 찾습니다. 참고로 여기서 key 값은 protocol을 uint8_t로 캐스팅한 값입니다.
그리고 만약 값이 존재하지 않았을 때에는, 해당 Cluster가 Connection Pool을 생성이 가능한지 Resource Limit 설정 값을 살펴봅니다. 그리고 생성이 불가할 경우에는 위 코드와 같이 nullopt를 반환하는 것을 볼 수 있습니다.
8. 만약 Resource Limit 설정 값을 확인했을 경우 신규 Pool 생성이 가능한 경우에는 기존에 입력받은 factory 메소드로부터 신규로 Pool을 할당받고자 호출합니다.
cluster_manager_impl.cc
Http::ConnectionPool::InstancePtr ProdClusterManagerFactory::allocateConnPool(
Event::Dispatcher& dispatcher, HostConstSharedPtr host, ResourcePriority priority,
std::vector<Http::Protocol>& protocols,
const absl::optional<envoy::config::core::v3::AlternateProtocolsCacheOptions>&
alternate_protocol_options,
const Network::ConnectionSocket::OptionsSharedPtr& options,
const Network::TransportSocketOptionsConstSharedPtr& transport_socket_options,
TimeSource& source, ClusterConnectivityState& state, Http::PersistentQuicInfoPtr& quic_info) {
Http::HttpServerPropertiesCacheSharedPtr alternate_protocols_cache;
if (alternate_protocol_options.has_value()) {
// If there is configuration for an alternate protocols cache, always create one.
alternate_protocols_cache = alternate_protocols_cache_manager_->getCache(
alternate_protocol_options.value(), dispatcher);
} else if (!alternate_protocol_options.has_value() &&
(protocols.size() == 2 ||
(protocols.size() == 1 && protocols[0] == Http::Protocol::Http2)) &&
Runtime::runtimeFeatureEnabled(
"envoy.reloadable_features.allow_concurrency_for_alpn_pool")) {
// If there is no configuration for an alternate protocols cache, still
// create one if there's an HTTP/2 upstream (either explicitly, or for mixed
// HTTP/1.1 and HTTP/2 pools) to track the max concurrent streams across
// connections.
envoy::config::core::v3::AlternateProtocolsCacheOptions default_options;
default_options.set_name(host->cluster().name());
alternate_protocols_cache =
alternate_protocols_cache_manager_->getCache(default_options, dispatcher);
}
absl::optional<Http::HttpServerPropertiesCache::Origin> origin =
getOrigin(transport_socket_options, host);
if (protocols.size() == 3 &&
context_.runtime().snapshot().featureEnabled("upstream.use_http3", 100)) {
ASSERT(contains(protocols,
{Http::Protocol::Http11, Http::Protocol::Http2, Http::Protocol::Http3}));
ASSERT(alternate_protocol_options.has_value());
ASSERT(alternate_protocols_cache);
#ifdef ENVOY_ENABLE_QUIC
Envoy::Http::ConnectivityGrid::ConnectivityOptions coptions{protocols};
if (quic_info == nullptr) {
quic_info = Quic::createPersistentQuicInfoForCluster(dispatcher, host->cluster());
}
return std::make_unique<Http::ConnectivityGrid>(
dispatcher, context_.api().randomGenerator(), host, priority, options,
transport_socket_options, state, source, alternate_protocols_cache, coptions,
quic_stat_names_, stats_, *quic_info);
#else
(void)quic_info;
// Should be blocked by configuration checking at an earlier point.
PANIC("unexpected");
#endif
}
if (protocols.size() >= 2) {
if (Runtime::runtimeFeatureEnabled(
"envoy.reloadable_features.allow_concurrency_for_alpn_pool") &&
origin.has_value()) {
ENVOY_BUG(origin.has_value(), "Unable to determine origin for host ");
envoy::config::core::v3::AlternateProtocolsCacheOptions default_options;
default_options.set_name(host->cluster().name());
alternate_protocols_cache =
alternate_protocols_cache_manager_->getCache(default_options, dispatcher);
}
ASSERT(contains(protocols, {Http::Protocol::Http11, Http::Protocol::Http2}));
return std::make_unique<Http::HttpConnPoolImplMixed>(
dispatcher, context_.api().randomGenerator(), host, priority, options,
transport_socket_options, state, origin, alternate_protocols_cache);
}
if (protocols.size() == 1 && protocols[0] == Http::Protocol::Http2 &&
context_.runtime().snapshot().featureEnabled("upstream.use_http2", 100)) {
return Http::Http2::allocateConnPool(dispatcher, context_.api().randomGenerator(), host,
priority, options, transport_socket_options, state, origin,
alternate_protocols_cache);
}
if (protocols.size() == 1 && protocols[0] == Http::Protocol::Http3 &&
context_.runtime().snapshot().featureEnabled("upstream.use_http3", 100)) {
#ifdef ENVOY_ENABLE_QUIC
if (quic_info == nullptr) {
quic_info = Quic::createPersistentQuicInfoForCluster(dispatcher, host->cluster());
}
return Http::Http3::allocateConnPool(dispatcher, context_.api().randomGenerator(), host,
priority, options, transport_socket_options, state,
quic_stat_names_, {}, stats_, {}, *quic_info);
#else
UNREFERENCED_PARAMETER(source);
// Should be blocked by configuration checking at an earlier point.
PANIC("unexpected");
#endif
}
ASSERT(protocols.size() == 1 && protocols[0] == Http::Protocol::Http11);
return Http::Http1::allocateConnPool(dispatcher, context_.api().randomGenerator(), host, priority,
options, transport_socket_options, state);
}
여기서 할당된 factory 메소드는 ClusterManager에서 관리하는 allocateCoonPool이 최종적으로는 호출되며, Cluster Manager에서는 client가 요구하는 프로토콜이 무엇인지 확인한 다음에 해당 요청을 처리할 수 있는 Connection을 생성하여 반환합니다. 그리고 생성된 Pool을 Container가 보유하고 있는 active_pools_에 삽입합니다.
9. 생성된 Pool을 ThreadLocalCluster에 반환합니다.
10. Pool을 Router에게 반환합니다. 이후 해당 Router에서는 전달받은 Pool을 통해 Downstream과 Upstream과의 연결 작업을 요청할 수 있게됩니다.
위와 같이 10단계를 거치게되면, Router는 Connection Pool을 할당받아 요청을 처리할 수 있게되었음을 확인할 수 있습니다. 반면 Connection 해제는 Router로 전달되었던 Connection Pool을 통해 해제를 요청할 수 있습니다.
6. ADS 관리
dynamic_resources:
lds_config:
resource_api_version: V3
ads: {}
cds_config:
resource_api_version: V3
ads: {}
ads_config:
transport_api_version: V3
api_type: GRPC
grpc_services:
envoy_grpc:
cluster_name: envoy-control-xds
이전 포스팅에서 xDS API와 함께 ADS (Aggregate Discovery Service)에 대해서 설명했습니다. Cluster Manager의 또 다른 ADS를 생성하고 관리하는 것입니다. 즉 Cluster Manager에서는 xDS API를 위한 Subscription, gRPC Multiplxer 및 ADS 관리를 총체적으로 담당합니다.
7. Health Check 동작 원리
지금까지 Static Resource 그리고 CDS를 통한 Cluster 추가에 대해서 살펴봤습니다. 이번에는 ClusterData를 생성하는 과정에서 Health Check, Outlier Detector가 어떻게 생성되고 동작하는지 살펴보겠습니다. 먼저 살펴볼 것은 Health Check 입니다.
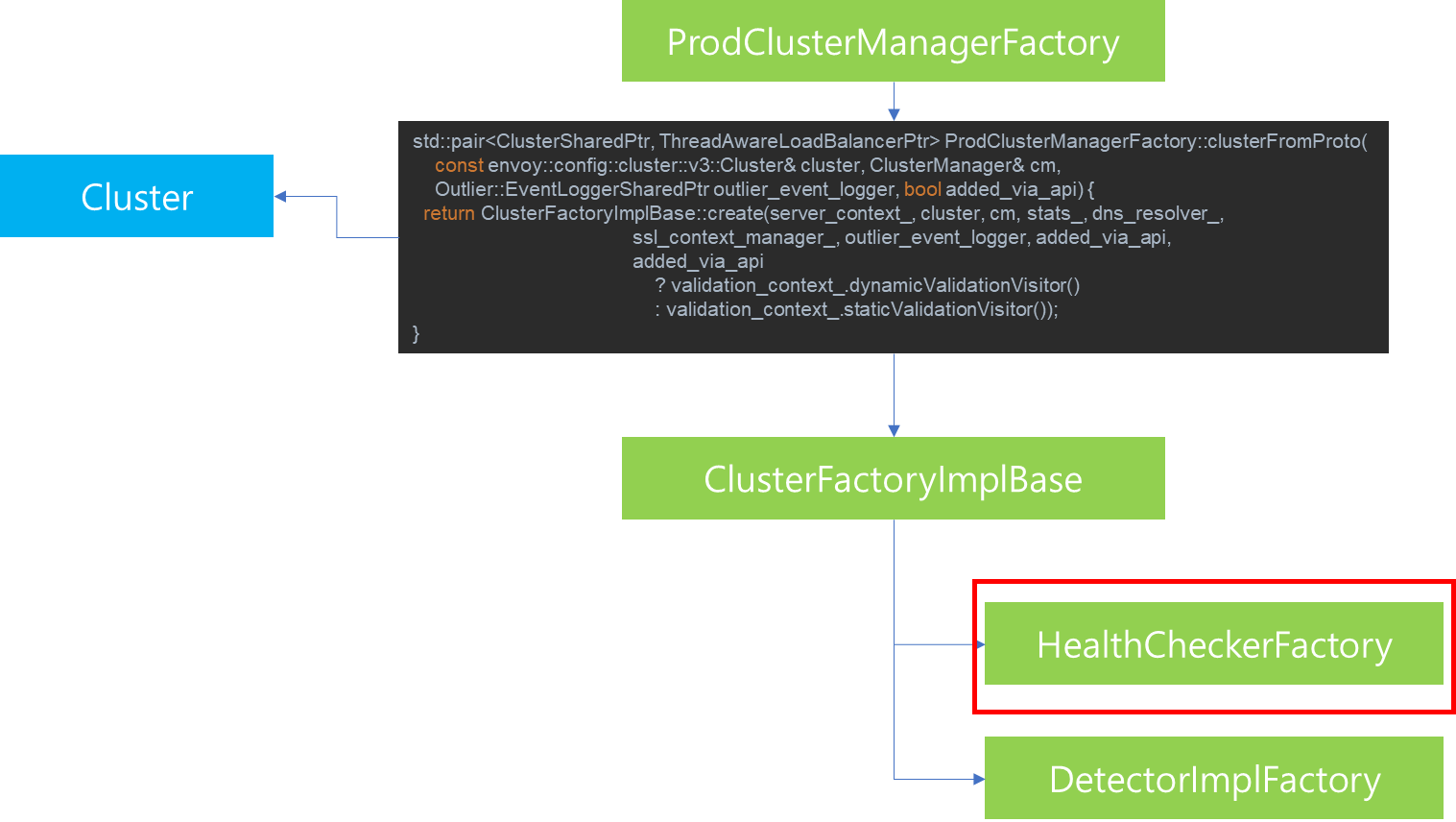
이전에 살펴봤듯이 ClusterData를 생성하는 과정에서 Outlier Detector, Health Chekcer, Load Balancer 등이 추가됨을 확인할 수 있습니다. 이때 Health Checker를 생성하는 역할은 HealthCheckerFactory가 담당하며, 이후 수행과정을 살펴보면 다음과 같습니다.
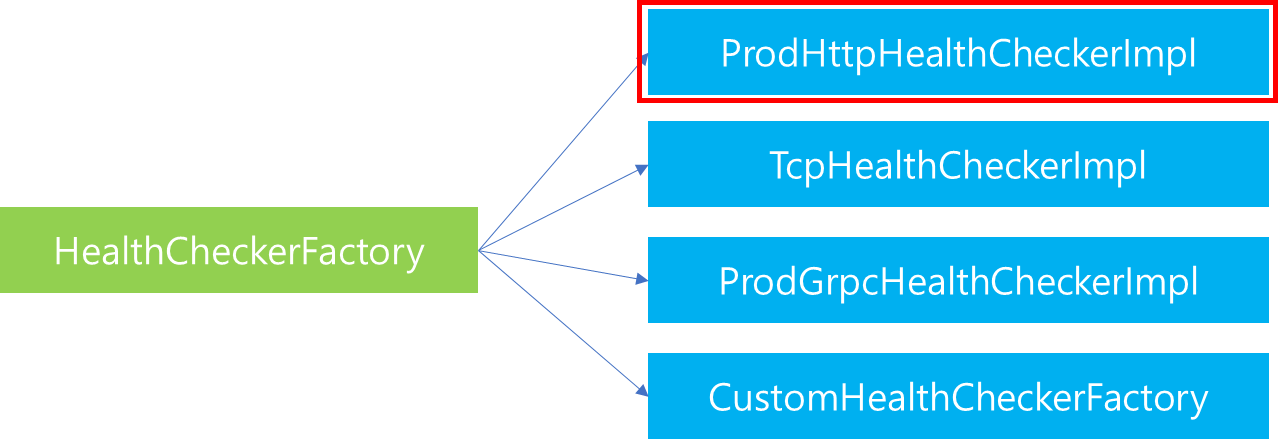
Config를 통해 전달받은 Cluster 내부에는 Http 방식 뿐만 아니라 Tcp, gRPC 혹은 Custom 방식의 Health Check를 지정할 수 있습니다. 따라서 HealthCheckerFactory에서는 사용자가 입력한 Config의 Heath Checker 방식을 확인하고 그에 걸맞는 Health Checker를 생성하도록 지정합니다. 본 포스팅에서는 Http 기반으로 생성했음을 가정하였음으로 ProdHttpHealthCheckerImpl을 생성할 것입니다.

생성된 Health Checker 인스턴스는 ClusterData의 HealthChecker에 바인딩되어 동작합니다.

cluster_manager_impl.cc
if (new_cluster->healthChecker() != nullptr) {
new_cluster->healthChecker()->addHostCheckCompleteCb(
[this](HostSharedPtr host, HealthTransition changed_state) {
if (changed_state == HealthTransition::Changed &&
host->healthFlagGet(Host::HealthFlag::FAILED_ACTIVE_HC)) {
postThreadLocalHealthFailure(host);
}
});
}
Health Checker가 매핑되고 나면 Cluster Manager에서는 Health Checker가 정상적으로 매핑되어있는지를 확인합니다. 그리고 인스턴스가 존재할 경우에는 Health Checker에서 비정상 Health 대상으로 판단한 host에 대해서 ejection 수행을 위한 Callback을 등록합니다.
이때 postThreadLocalHealthFailure는 TLS를 통해서 Health가 실패했음을 전달하며, 이를 수신받은 Cluster Manager에서는 해당 host에 연결된 Connection Pool을 해제하는 작업을 수행합니다.

수행 과정을 살펴보면 위 그림과 같습니다.
1. Health Checker에서 주기적으로 Health Check를 수행하다가 이상이 발생하면, 내부 종료 작업을 먼저 거친 뒤에 등록된 Callback을 통해 외부로 전파합니다.
2. Cluster Manager에서는 기존에 등록한 Callback 함수를 수행합니다. 이때 내부적으로 ThreadLocalClusterManagerImpl을 참조하여 해당 Host 이상 여부를 전체로 전파합니다.
3. Dispatcher를 통해 해당 내역을 전달받은 Cluster Manager에서는 Connection을 해제하기 위하여 Connection Pool에서 해당 host 내부에 존재하는 Connection들을 순차적으로 종료하고 해당 Pool 또한 Close 시킵니다.
해당 과정이 정상적으로 완료되면, Health Check에 따른 연결된 Client 및 host 또한 정상적으로 종료되는 것을 이해할 수 있습니다. 그렇다면 Health Check는 어떻게 이루어질까요? Health Check Factory로부터 만들어진 ProdHttpHealthCheckerImpl 인스턴스의 구조와 수행 과정을 살펴보면서 조금 더 자세하게 알아보겠습니다.
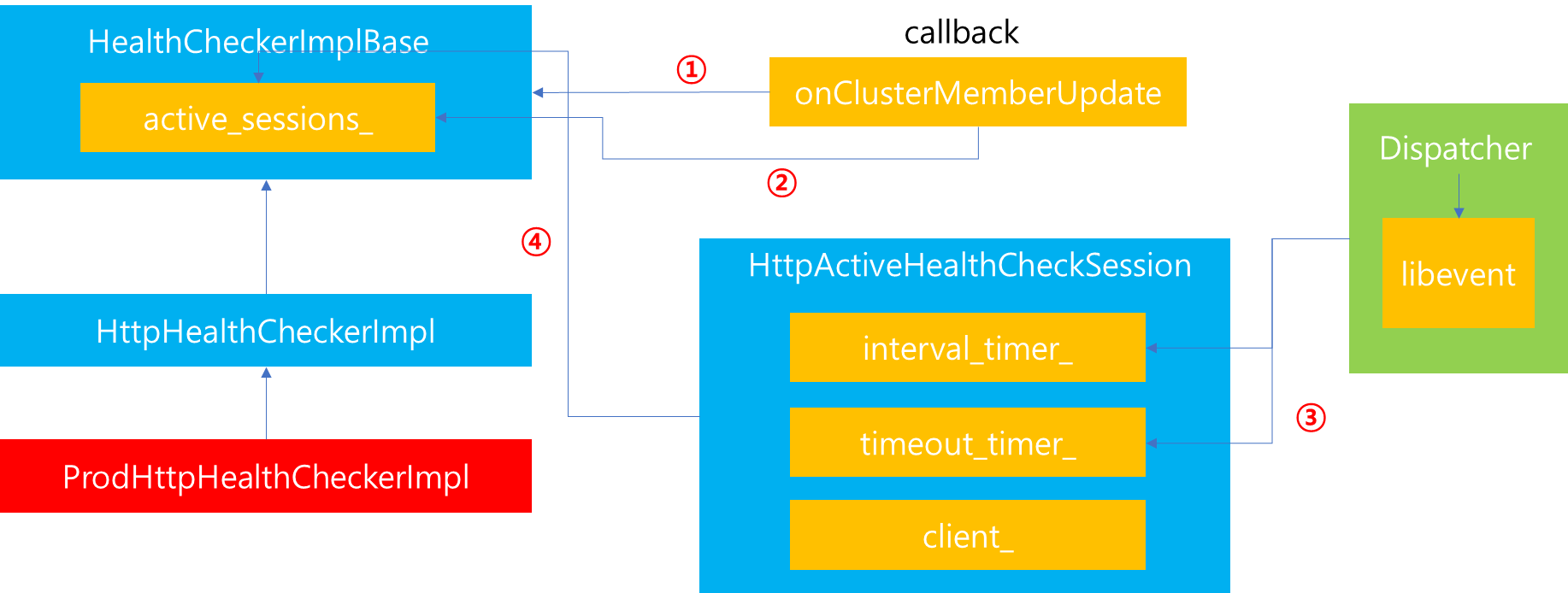
1. ProdHttpHealthCheckerImpl 생성자 내부에서 Cluster 데이터변경이 발생했을 때 처리를 위한 Callback을 등록합니다.
2. 해당 Callback은 호출될 때 추가되는 host 정보와 삭제되는 host 정보를 같이 전달받는데, 이를 토대로 추가되는 host 정보를 active_sessions_ 에 Session을 만들어 추가합니다. 반대로 삭제되는 host 정보 또한 active_sessions_ 에서 삭제합니다.
3. 이때 추가되는 Session에는 Health Check를 정기적으로 수행하기 위해서 Dispatcher에 존재하는 libevent로 부터 Timer를 할당받습니다. 이때 생성되는 timer는 총 2개로 Health Check를 주기적으로 수행하기 위한 interval_timer_와 timeout을 판별하기 위한 timeout_timer_ 를 생성합니다.
여기서 Health Check는 Session 내에 생성되는 Timer에 의해 이루어지므로 Session 생성 과정을 보다 자세하게 살펴보겠습니다.
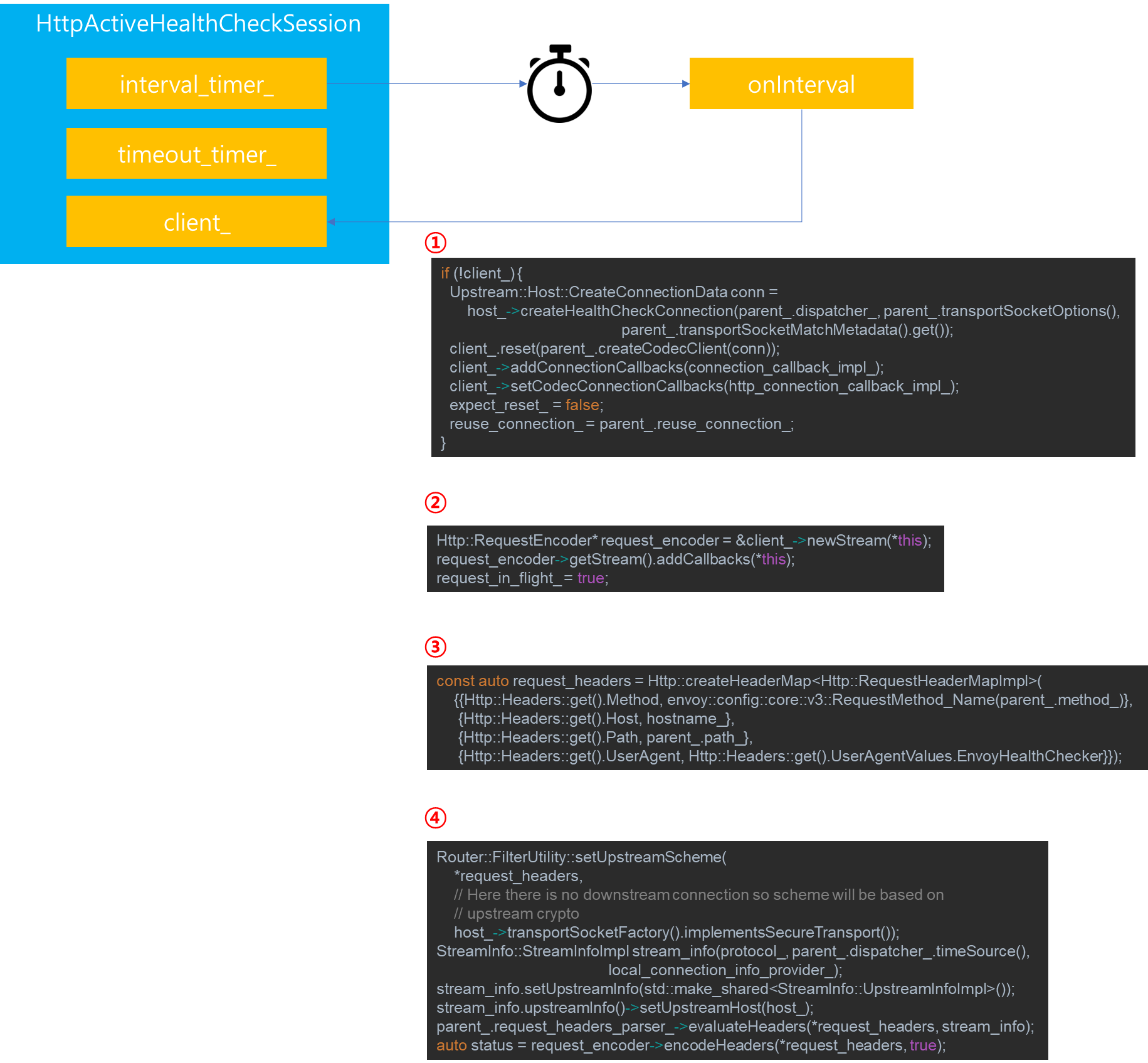
onInterval은 HealthCheck를 위해 주기적으로 호출되는 메소드로써, 아래와 같은 4가지 단계를 거칩니다.
1. client_가 존재하는지를 살펴보고 client_가 존재하지 않는다면 최초 실행임을 의미하므로 Connection을 생성합니다. 이때 생성된 Connection은 CodecClient를 통해 Wrapping 되는데, CodecClient는 HTTP Codec 타입에 따라서 생성되는 ClientConnectionImpl 인스턴스 타입입니다.
2. Stream을 생성합니다.
3. Health Check 관련 Header 설정을 진행합니다. 이때 method 및 path 등은 Health Check 설정으로 입력된 값을 따릅니다.
4. Upstream 설정 및 Health Check 처리를 위한 encoding 처리를 담당합니다.
위 과정이 마무리되면, 주기에 맞추어 Health Check 요청을 HTTP로 전달할 것입니다. 그렇다면 HTTP 요청에 대한 응답은 어떻게 처리될까요?

HttpActiveHealthCheckSession의 구조를 보면, 위와 같이 여러 Class가 상속되어있음을 확인할 수 있습니다. 그 중 요청 응답 처리는 ResponseDecoder 내부 정의된 I/F에 의해서 호출됩니다. 참고로 해당 과정에서 호출되는 메소드는 decodeHeaders와 decodeData 입니다. 따라서 HttpActiveHealthCheckSession 내부에 정의된 하기 2개의 메소드가 호출됩니다.
health_checker_impl.cc
void HttpHealthCheckerImpl::HttpActiveHealthCheckSession::decodeHeaders(
Http::ResponseHeaderMapPtr&& headers, bool end_stream) {
ASSERT(!response_headers_);
response_headers_ = std::move(headers);
if (end_stream) {
onResponseComplete();
}
}
void HttpHealthCheckerImpl::HttpActiveHealthCheckSession::decodeData(Buffer::Instance& data,
bool end_stream) {
if (parent_.response_buffer_size_ != 0) {
if (!parent_.receive_bytes_.empty() &&
response_body_->length() < parent_.response_buffer_size_) {
response_body_->move(data, parent_.response_buffer_size_ - response_body_->length());
}
} else {
if (!parent_.receive_bytes_.empty()) {
response_body_->move(data, data.length());
}
}
if (end_stream) {
onResponseComplete();
}
}
위 메소드에서 살펴볼 것은 data가 전달이 완료되지 않았을 경우에는 response_body 데이터를 지속 수신받는 것을 알 수 있고 stream이 종료되었을 경우에는 onResponseComplete() 메소드가 호출됨을 알 수 있습니다. 즉 Health Check를 결정하는 요인은 onResponseComplete() 메소드 내부에서 이루어짐을 짐작할 수 있습니다.
health_checker_impl.cc
void HttpHealthCheckerImpl::HttpActiveHealthCheckSession::onResponseComplete() {
request_in_flight_ = false;
switch (healthCheckResult()) {
case HealthCheckResult::Succeeded:
handleSuccess(false);
break;
case HealthCheckResult::Degraded:
handleSuccess(true);
break;
case HealthCheckResult::Failed:
handleFailure(envoy::data::core::v3::ACTIVE, /*retriable=*/false);
break;
case HealthCheckResult::Retriable:
handleFailure(envoy::data::core::v3::ACTIVE, /*retriable=*/true);
break;
}
if (shouldClose()) {
client_->close();
}
response_headers_.reset();
response_body_->drain(response_body_->length());
}
onResponseComplete() 메소드 내부를 살펴보면, healthCheck에 대한 결과를 기점으로 Switch로 분기하여 각기 다른 결과를 호출하는 것을 볼 수 있습니다. 만약 Failure가 발생한다면, 해당 timer를 disabled 시키고 종료처리할 것이며, shouldClose() 호출로 인해 client 연결 또한 종료됩니다.
만약 정상적으로 처리되었다면, 지속적으로 Health Check를 주기적으로 반복하여 정상여부 확인을 반복합니다.
8. Outlier Detection 동작 원리
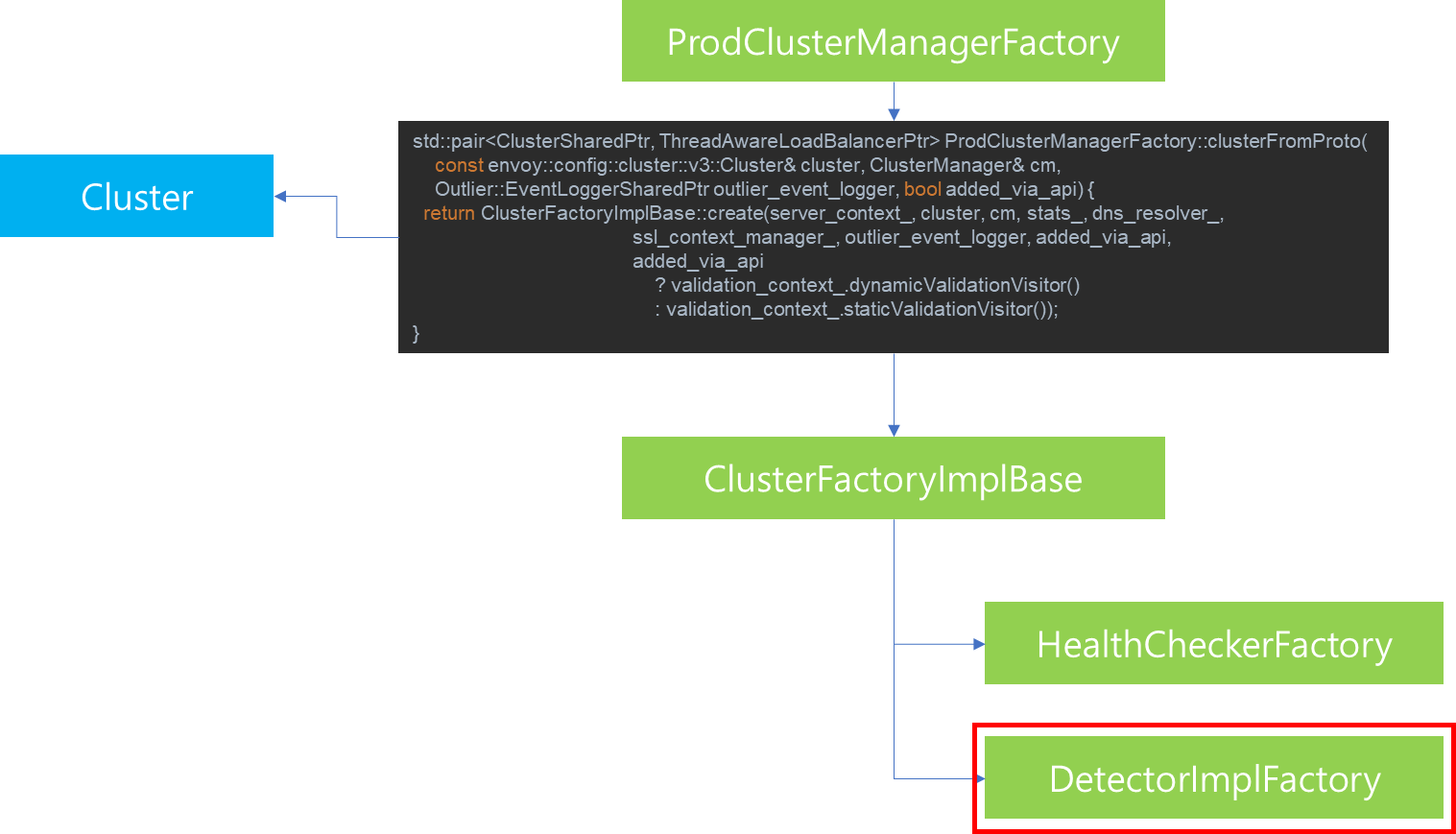
지금까지 Health Checker의 생성 및 동작과정에 대해서 살펴봤다면, 이번에는 Outlier Detector가 생성되는 과정과 동작 방법에 대해 살펴보겠습니다.
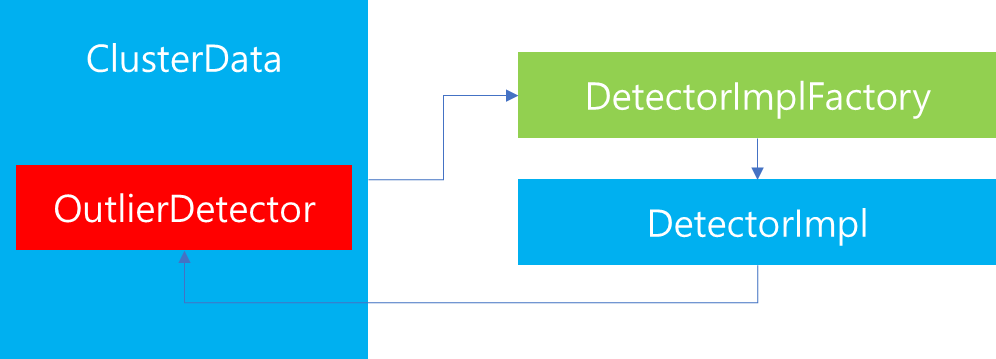
Outlier Detector는 ClusterData 생성 당시에 DetectorImplFactory에 의해서 생성됩니다. 이때 생성되는 Outlier Detector의 인스턴스는 DetectorImpl이며 해당 인스턴스가 ClusterData의 OutlierDetector에 바인딩되어 동작합니다.
해당 내용을 코드를 통해서 살펴보겠습니다.
outlier_detection_impl.cc
DetectorSharedPtr DetectorImplFactory::createForCluster(
Cluster& cluster, const envoy::config::cluster::v3::Cluster& cluster_config,
Event::Dispatcher& dispatcher, Runtime::Loader& runtime, EventLoggerSharedPtr event_logger,
Random::RandomGenerator& random) {
if (cluster_config.has_outlier_detection()) {
return DetectorImpl::create(cluster, cluster_config.outlier_detection(), dispatcher, runtime,
dispatcher.timeSource(), std::move(event_logger), random);
} else {
return nullptr;
}
}
다만 위 코드와 같이 모든 ClusterData에서 OutlierDetector를 생성하는 것은 아니며, Static 혹은 Dynamic Resource 내에 outlier_detection 설정이 활성화되어있는 경우에만 생성됩니다. 만약 해당 설정이 비활성화 되어있다면, OutlierDetector는 nullptr이 매핑됩니다.

cluster_manager_impl.cc
if (new_cluster->outlierDetector() != nullptr) {
new_cluster->outlierDetector()->addChangedStateCb([this](HostSharedPtr host) {
if (host->healthFlagGet(Host::HealthFlag::FAILED_OUTLIER_CHECK)) {
ENVOY_LOG_EVENT(debug, "outlier_detection_ejection",
"host {} in cluster {} was ejected by the outlier detector",
host->address()->asStringView(), host->cluster().name());
postThreadLocalHealthFailure(host);
}
});
}
OutlierDetector가 매핑되고 나면 Cluster Manager에서는 Outlier Detector가 정상적으로 매핑되어있는지를 확인합니다. 그리고 인스턴스가 존재할 경우에는 Outlier Detector에서 Ejection 대상으로 판단한 host에 대해서 ejection 수행을 위한 Callback을 등록합니다.
이때 postThreadLocalHealthFailure는 TLS를 통해서 Health가 실패했음을 전달하며, 이를 수신받은 Cluster Manager에서는 해당 host에 연결된 Connection Pool을 해제하는 작업을 수행합니다. 해당 작업은 Health Check를 수행하면서 실패했을 때 Connection 해제하는 과정과 완벽하게 동일합니다.
지금까지 Outlier Detector 설정 관련해서 살펴봤습니다. 이번에는 실제 Outlier Detector가 수행하는 기능에 대해서 조금 더 자세하게 살펴보기 위해 Outlier로 등록되는 DetectorImpl 구조 및 동작 원리에 대해서 살펴보겠습니다.
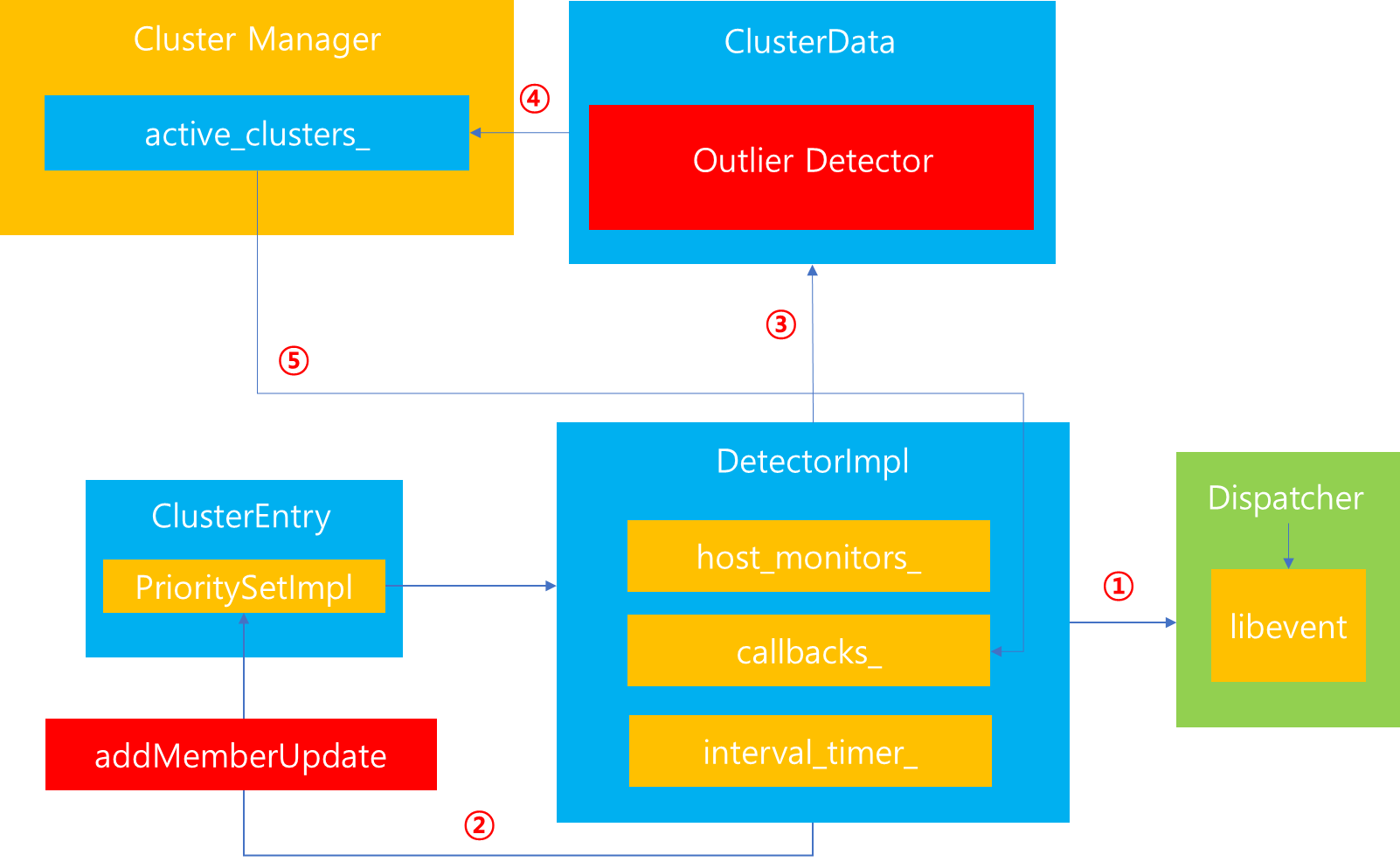
이를 위해 DetectorImpl을 생성 과정에 대해서 상세하게 짚어보겠습니다.
1. DetectorImpl 내부에서도 정기적으로 Cluster 내부에 존재하는 host들의 상태를 살펴보고 Outlier Detection을 지정한 임계치를 넘어가는 host를 점검하기 위해 Dispatcher로 부터 Timer를 할당받아 interval_timer_에 지정하는 작업을 합니다.
2. 그 다음은 외부에서 Cluster 내부 host가 추가되거나 삭제되는 등의 작업이 발생했을 때 Outlier Detector에서도 이를 감지하고 설정을 변경해야되기 때문에 ClusterEntry 내부에 존재하는 PriortySet에 Callback을 추가합니다. 해당 Callback 등록을 통해 실질적으로 Cluster 내부 host 변경이 발생했을 경우 이를 Detector가 통지받아 후속 작업을 수행할 수 있습니다. Callback을 전달받으면, 내부에서는 hosts를 관리하는 host_monitors_ Map 자료구조에 해당 hosts의 변경사항을 기록합니다. 이때 host 별로 DetectorHostMonitorImpl 인스턴스를 생성하여 Outlier Detection을 위한 기본 속성을 저장하는데, 이는 잠시 후 다시 살펴보겠습니다.
3. DetectorImpl 생성이 완료되면, ClusterData OutlierDetector에 매핑합니다.
4. ClusterData를 active_clusters_에 추가합니다.
5. ClusterManager에서 해당 OutlierDetector에게 Callback을 등록합니다. 이는 Outlier Detection 판정이 된 host에 대해서 Client 연결 종료 등의 후속작업을 처리하기 위함입니다.
위와 같은 과정을 거치고나면, Outlier Detector는 본격적으로 본인의 역할을 수행할 수 있습니다. 이번에는 초기화가 완료된 이후 후속 작업 진행 절차에 대해서 살펴보겠습니다.
outlier_detection_impl.cc
void DetectorImpl::armIntervalTimer() {
interval_timer_->enableTimer(std::chrono::milliseconds(
runtime_.snapshot().getInteger(IntervalMsRuntime, config_.intervalMs())));
}
먼저 초기화 작업이 끝나고나서 가장 먼저 수행하는 작업은 timer를 활성화 시키는 것입니다. 이는 위 메소드를 호출하여 실행되며, interval_timer_의 수행 주기는 위와 같이 config에 지정된 값을 활용하는 것을 볼 수 있습니다. 그렇다면, interval_timer_를 활성화 시켰을 때 어떤 작업을 수행할까요?
outlier_detection_impl.cc
DetectorImpl::DetectorImpl(const Cluster& cluster,
const envoy::config::cluster::v3::OutlierDetection& config,
Event::Dispatcher& dispatcher, Runtime::Loader& runtime,
TimeSource& time_source, EventLoggerSharedPtr event_logger,
Random::RandomGenerator& random)
: config_(config), dispatcher_(dispatcher), runtime_(runtime), time_source_(time_source),
stats_(generateStats(cluster.info()->statsScope())),
interval_timer_(dispatcher.createTimer([this]() -> void { onIntervalTimer(); })),
event_logger_(event_logger), random_generator_(random) {
// Insert success rate initial numbers for each type of SR detector
external_origin_sr_num_ = {-1, -1};
local_origin_sr_num_ = {-1, -1};
}
이는 위와 같이 해당 DetectorImpl의 생성자 코드를 살펴보면 힌트를 얻을 수 있습니다. 내용을 살펴보면 dispatcher로부터 timer를 생성받고나서 해당 timer가 호출해야되는 callback이 지정된 것을 확인할 수 있습니다. 이는 위와 같이 onIntervalTimer() 메소드가 지정되어있습니다. 따라서 주기적으로 onIntervalTimer() 메소드가 호출됨으로써 Outlier Detection 작업을 수행함을 알 수 있습니다.
outlier_detection_impl.cc
void DetectorImpl::onIntervalTimer() {
MonotonicTime now = time_source_.monotonicTime();
for (auto host : host_monitors_) {
checkHostForUneject(host.first, host.second, now);
// Need to update the writer bucket to keep the data valid.
host.second->updateCurrentSuccessRateBucket();
// Refresh host success rate stat for the /clusters endpoint. If there is a new valid value, it
// will get updated in processSuccessRateEjections().
host.second->successRate(DetectorHostMonitor::SuccessRateMonitorType::LocalOrigin, -1);
host.second->successRate(DetectorHostMonitor::SuccessRateMonitorType::ExternalOrigin, -1);
}
processSuccessRateEjections(DetectorHostMonitor::SuccessRateMonitorType::ExternalOrigin);
processSuccessRateEjections(DetectorHostMonitor::SuccessRateMonitorType::LocalOrigin);
armIntervalTimer();
}
그렇다면, 해당 메소드는 어떻게 구현되어있을까요?
위 코드와 같이 host_monitors_에 매핑된 전체 host들에 대해서 순회하면서 ejection 여부를 판단합니다. 만약 ejection이 결정되었다면, 해당 host_monitors_에 저장된 Monitor 정보를 초기화하고 ejection을 수행합니다. 또한 외부로부터 등록된 callback을 호출시켜, 후속 작업을 진행할 수 있도록 합니다.
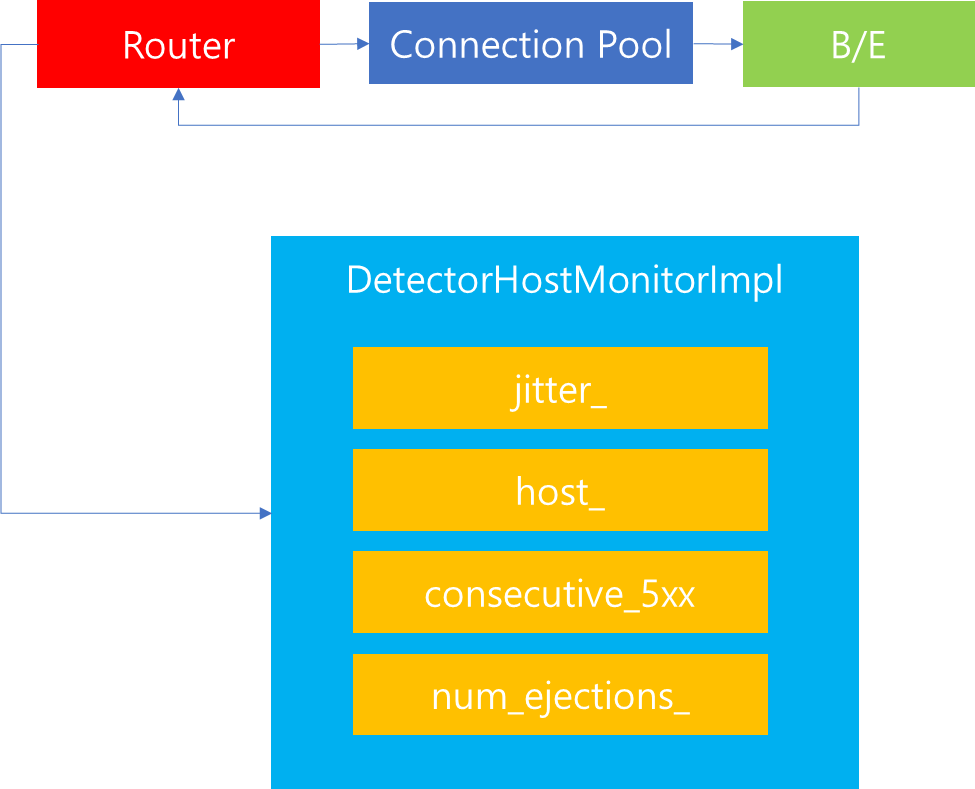
참고로 host_monitors_에 매핑된 인스턴스는 DetectorHostMonitorImpl 인스턴스이며, 해당 인스턴스 내부에는 Outlier Detection을 판별하기 위한 여러가지 내부 속성 프로퍼티 값들이 존재합니다. 해당 프로퍼티 값은 Client가 Cluster Manager로부터 Connection Pool을 받아 Upstream host에 Http 요청을 완료한 이후에 전달받은 응답값을 토대로 Router가 갱신을 수행합니다.
따라서 Outlier Detector 내부에서 onIntervalTimer()가 수행될 때 해당 Monitor 인스턴스 내부 속성 값을 기준으로 ejection 여부를 판별할 수 있습니다.
outlier_detection_impl.cc
void DetectorImpl::armIntervalTimer() {
interval_timer_->enableTimer(std::chrono::milliseconds(
runtime_.snapshot().getInteger(IntervalMsRuntime, config_.intervalMs())));
}모든 host_monitors_ 순회가 모두 끝나고 나면 다시 timer를 활성화 시켜 다음 outlier detection 처리를 반복 수행함으로써 지속적인 Outlier Detection 확인이 가능합니다.
9. 마치며
이번 포스팅에서는 Cluster Manager의 기능에 대해 일부 살펴봤습니다. Cluster Manager의 가장 중요한 것은 Cluster 관리입니다. 다만 그 외에도 ads 관리 및 subscription factory 등을 담당하는 것을 살펴봤습니다.
다음 포스팅에서는 Cluster에 지정되는 Load Balancer 종류에 대해 개념적으로 살펴보도록 하겠습니다.