서론
이전 포스팅에서 Redis의 기본적인 구조와 복제(Replication)에 대해서 살펴봤습니다.
잠시 복기해보자면, 복제는 Master의 데이터를 Replica에 모두 저장하여 가용성과 읽기 작업의 성능을 높일 수 있습니다.
하지만 데이터 양이 폭발적으로 증가한다면 어떻게 될까요?
Replication은 모든 데이터를 복제해야하기 때문에 단일 서버에서 저장 가능한 Memory를 초과하면 이를 복제할 수 없습니다. 따라서 메모리 증설등을 통한 Scale-Up 만으로 데이터 저장 공간을 확보할 수 없다면 다른 방법이 필요합니다.
이번 포스팅에서는 데이터 분산을 통해 고가용성을 확보할 수 있는 파티셔닝 개념과 Redis에서 사용되는 샤딩전략 그리고 Cluster에 대해 다루도록 하겠습니다.
1. 파티셔닝 개념
파티셔닝은 DB의 관리 용이성 및 읽기 최적화를 위해 논리적인 테이블의 물리 구조를 여러개의 파티션(Partition)으로 분할하여 분산 저장하는 기법을 말합니다. 파티셔닝 개념에 대한 이해를 돕기위해 잠시 RDBMS에서의 파티셔닝에 대해서 간략하게 알아보겠습니다.
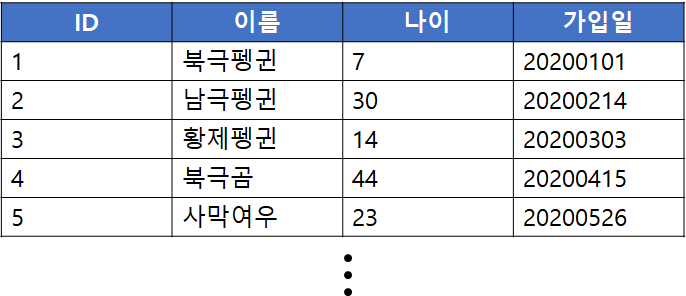
위 그림과 같은 회원 테이블이 존재한다고 가정해봅시다. 이때 가입자가 매일 증가하여 테이블 크기가 점점 커진다면, 해당 테이블에 조회 성능을 높이기 위해 인덱스 추가등의 작업이 쉽지 않을 뿐더러 점차 조회 성능도 떨어지게 됩니다.
가령 수십억건의 데이터가 존재하는 테이블에서 매월마다 가입일이 5년지난 데이터를 삭제해야 한다면 어떻게 해야할까요?
데이터를 지우기 위해서 수십억건의 테이블을 탐색하면서 조건에 해당하는 데이터를 삭제해야합니다. 이렇게 되면 오랜시간동안 Lock으로 인해 동시성 저하가 발생할 수 있으며, 테이블 크기가 점점 더 커질 수록 해당 작업은 어려워질 것입니다.
설령 가입일에 인덱스가 생성되어있다 할지라도 디스크 Random I/O로 인해 좋은 성능이 나오지 않을 뿐더러 데이터 지속 삭제로 인해 인덱스 Sparse 현상이 발생할 수 있습니다.
따라서, 이러한 경우 사용자에게 논리적으로 보여지는 테이블은 하나이지만 기저에 물리적으로는 여러 파티션에 데이터를 나누어 저장한다면, 조회 성능 향상 및 관리가 용이해집니다.
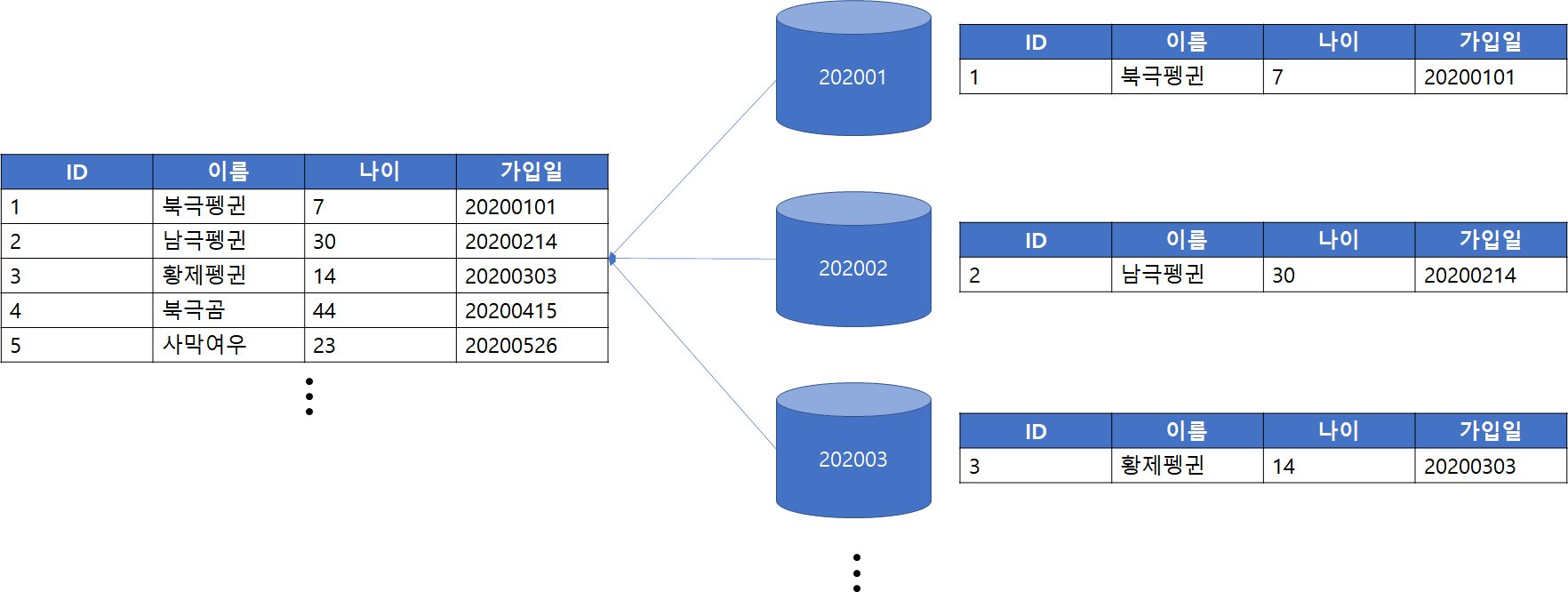
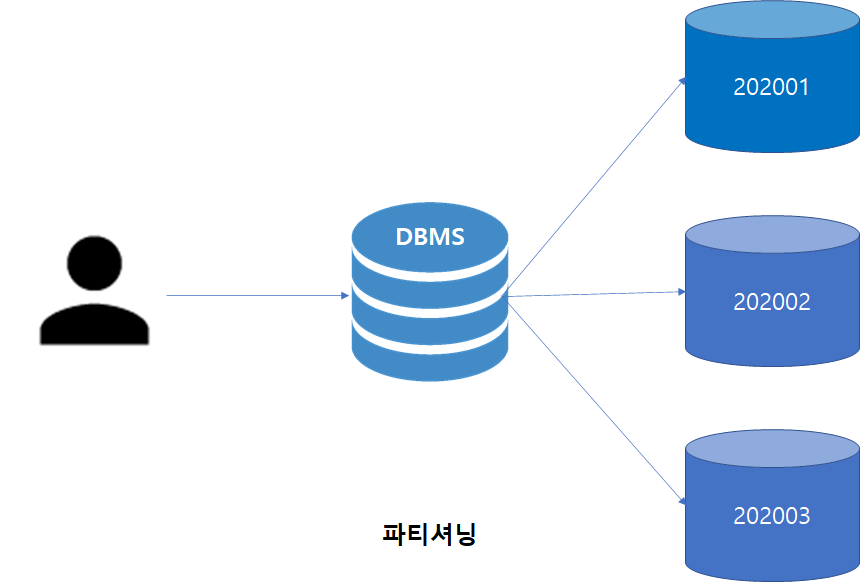
위 그림은 가입일 기준으로 20년 1월에 발생한 데이터는 202001 파티션에 저장하도록 하였고, 2월에 가입한 회원들은 202002 파티션에 저장되도록 파티션을 구성하였습니다.
이와같이 가입일 기준으로 파티션을 구성하면 다음과 같은 이점이 있습니다.
만약 매월 가입일 기준으로 사용자를 삭제한다면, 기존에는 테이블내 모든 데이터를 탐색해야했지만 지금은 특정 월에 해당하는 파티션만 Drop(DDL 작업) 하면 되므로 작업 부담이 줄어듭니다.
그리고 특정 월에 해당하는 데이터를 조회할 때, 해당 파티션에 속한 데이터에 대해서만 Multi block I/O를 실시할 수 있기 때문에 인덱스를 사용하는 방법보다 빠른 조회가 가능할 수 있습니다.
정리하자면 파티셔닝은 위 사례와 같이 대용량의 논리적 구조를 여러 물리적인 파티션으로 분할하여 조회 및 관리 용이성을 위해 사용됩니다.
2. 파티셔닝 종류
이번에는 파티셔닝 종류에 대해서 알아보겠습니다. 파티셔닝은 수직적 파티셔닝과 수평적 파티셔닝 2가지 종류가 있습니다.
수평적 파티셔닝은 이전 파티셔닝 개념에서 살펴보았듯이, 특정 데이터(가입일) 기준으로 데이터를 다른 파티션에 저장하는 방법을 말합니다.
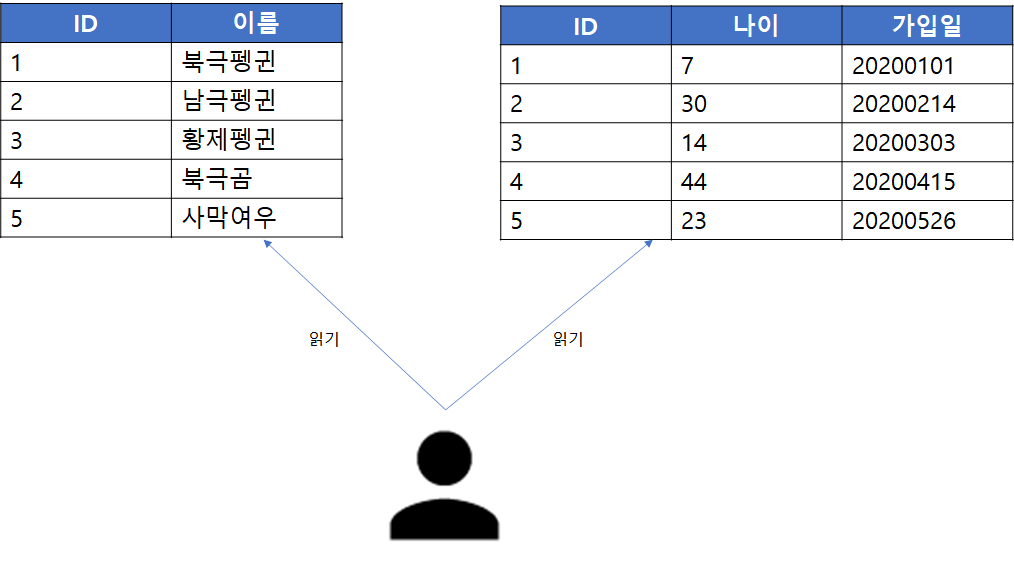
반면, 수직적 파티셔닝은 특정 컬럼을 기준으로 데이터를 분할하는 방법을 말합니다. 위 그림과 같이 기존 회원 테이블을 특정 컬럼을 기준으로 2개의 파티션으로 분할한 경우가 이에 해당됩니다.
수직적 파티셔닝의 이점은 한쪽 세그먼트에서 발생하는 DML이 다른쪽에 영향을 끼치지 않습니다. 반면, 레코드 전체 데이터를 읽어야할 경우에는 데이터가 물리적으로 분산되었으므로 I/O에서 다소 비효율이 발생합니다.
그렇다면, NoSQL 제품군에서 주로 사용되는 샤딩(Sharding)은 무엇일까요?
 |
 |
샤딩이란 수평적 파티셔닝의 한 종류입니다. 수평적 파티셔닝과 비교하여 다른점은 파티셔닝은 단일 DBMS내에서의 데이터 분할 정책이고, 샤딩은 분할된 여러 데이터베이스 서버로 데이터를 분할하는 방법입니다.
따라서, 샤딩을 구성하게되면 샤드의 수만큼 노드가 존재하며, 서버가 여러대 존재하므로 부하를 적절히 분산할 수 있는 장점이 있습니다.
지금까지 파티셔닝 종류에 대해서 알아봤습니다. 용량을 고려하여 데이터 크기를 분할할 때, 수직적 파티션보다는 수평적 파티션이 분배에 용이하므로 이후 내용은 수평적 파티셔닝 전략을 기준으로 작성하였음을 참고바랍니다.
3. 파티셔닝 전략
이전에 살펴본 예제는 가입일 컬럼 대상 특정 월을 기준으로 데이터 파티션을 나누었습니다. 이때 특정 범위를 기준으로 데이터를 분할한 파티션을 Range 파티션이라고 합니다.
Range 파티셔닝의 장점은 논리적인 범위의 분산에 효율적입니다. 또한, 원하는 데이터가 특정 파티션에 모여있어 관리하기가 용이합니다.
이렇듯 사용자가 원하는대로 데이터를 분산시킬 수 있는 장점이 있지만 다음과 같은 문제점을 지니고 있습니다. 사례를 통해 Range 파티션의 문제점을 알아보겠습니다.
만약 대한민국 전체 국민의 개인정보를 관리하는 시스템 테이블에서 사람들의 나이 10살 범위 기준으로 Range 파티셔닝 했다고 가정해보겠습니다.

차트를 통해 알 수 있듯이 50대 파티션에 가장 많은 데이터가 적재되며 파티션별로 데이터 편차가 크게 나는 것을 확인할 수 있습니다.
이를 통해 알 수 있는 사실은 Range 파티셔닝의 가장 큰 문제점은 데이터 분포도가 고르지 못할 경우 데이터 배분을 균등하게 할 수 없습니다.
지금까지 RDBMS 테이블 구조로 Range 파티션 구조를 살펴보았습니다. 만약 Redis로 회원 데이터를 샤딩하면 어떤 모습일까요?

대략 위 그림과 같이 전체 데이터를 특정 범위로 나뉘어 각각의 Master 서버에게 할당할 것입니다. 그리고 범위에 따른 파티션 지정의 책임은 Client에게 있는 것을 확인할 수 있습니다.
이처럼 Redis에서의 샤딩 전략은 RDMBS 파티셔닝과 차이가 존재합니다.
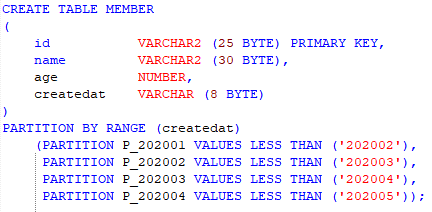
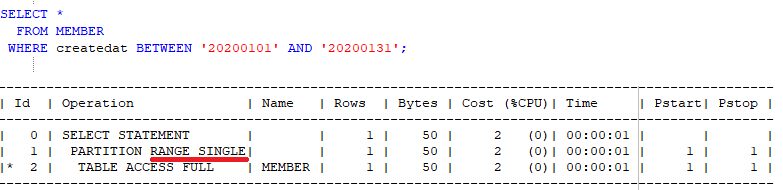
RDBMS의 경우에는 테이블 생성시, 파티션 전략을 지정하면, 이후 데이터 입력이나 조회가 필요할 경우에는 테이블을 대상으로 입력/조회 작업을 수행합니다. 그러면 옵티마이저가 적당한 파티션으로 분배할 것입니다.
하지만 Redis에서 파티셔닝 전략을 사용하려면 데이터 분배 책임은 Client에게 있습니다. 다시말해 이는 Client에서 데이터를 어디에 저장할지 혹은 데이터를 어디서 찾아야할지를 정해야함을 의미합니다.
Range 파티셔닝의 경우에는 특정 범위와 이에 해당하는 Master 노드를 매핑시키는 Mapping 테이블이나 Client 로직에 범위를 지정하여 분배하는 로직이 들어가야 합니다. 또한 데이터를 균등하게 분배하기 위해서는 철저한 전략 수립이 필요합니다.
결론적으로 Range 파티셔닝을 구현하는 것은 꽤 번거로운 일입니다. 공식 홈페이지에서 해당 내용에 대해서 다루고 있으며, 데이터 균등 분배를 위해 다음에 설명할 해시 파티셔닝 전략을 사용하는 것을 권하고 있습니다.
해시 파티셔닝
Redis에서 샤딩을 구현하기 위해서는 데이터를 서버별로 균등하게 분포해야 부하를 고르게 분산할 수 있습니다. 따라서 Range 파티셔닝은 데이터가 고르게 분포되지 못하므로 적절하지 못합니다. 이번에는 해시 파티셔닝을 통해서 데이터를 균등분배 하는 방법에 대해서 알아보겠습니다.
해시 파티셔닝은 Redis의 Key 값에 대하여 해시함수를 적용한 결과를 Redis Master의 개수만큼 나머지 연산을 토대로 데이터를 저장할 Master 서버를 지정하는 방법입니다.
다음과 같이 hash 함수를 적용한 다음 Modulo 연산을 통해서 데이터를 저장하거나 찾아야할 Redis 노드를 지정할 수 있습니다.
var hosts = {Master1, Master2, Master3, ... }
var index = hash(key) % hosts.length;
예를들어 Master 서버가 3대가 있고, 이를 배열로써 담았다고 가정합시다.
그러면 master1번은 0번 인덱스, master2는 1번 인덱스, master3은 2번 인덱스가 될 것입니다.
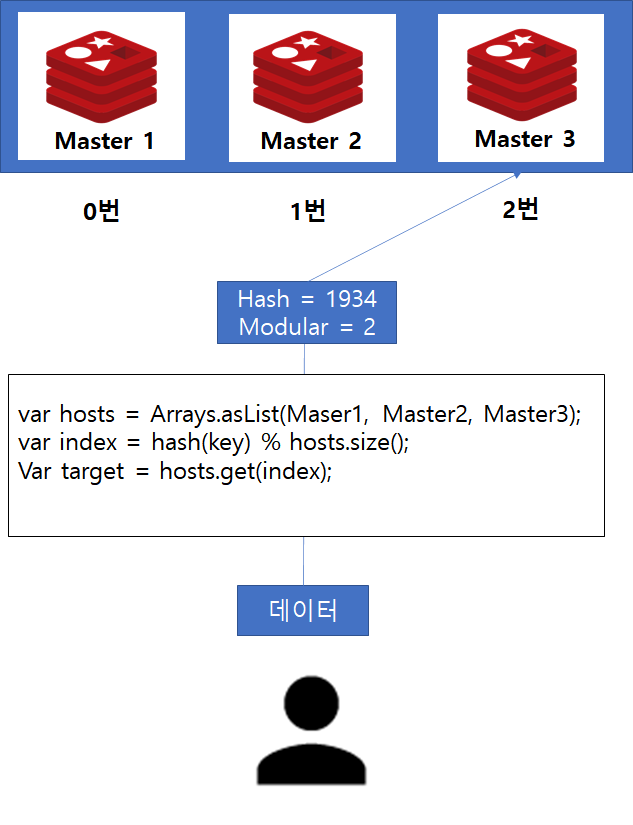
이때, Redis Key에 대하여 hash 함수를 적용한 결과가 1934라면 1934 % 3(서버 개수) 의 결과인 2에 해당하는 Master 3노드가 해당 Key의 저장소가 되며, 데이터를 조회할 때도 Client는 해당 저장소에서 데이터를 찾으려고 할 것입니다.
해시파티셔닝의 경우에는 Modulo 연산을 통해 데이터의 분포여부와 상관없이 고르게 분포시킬 수 있는 장점이 있어 주로 사용되는 전략입니다.
Rebalancing 문제
지금까지 Redis의 샤딩, Range 파티셔닝의 문제점 및 해시 파티셔닝을 통한 데이터 균등 분배 방법에 대해서 살펴봤습니다.
만약 해시 파티셔닝이 적용된 상황에서 데이터 용량이 더욱 커져 Master 서버 추가를 해야한다면, 어떤 이슈가 존재할까요? 사례를 통해서 알아보겠습니다.

위 그림과 같이 현재 총 12개의 데이터가 3개의 Master 서버에 고르게 분배되어있다고 가정해봅시다. 위와 같은 상황에서 Hash 함수 결과가 9를 저장하고 있는 Master는 9 % 3(서버 대수)에 의하여 Master 1번이 선택될 것이고 Client는 해당 연산을 통해서 Master1번에게 질의할 것입니다.
이러한 상황에서 Master4를 새롭게 추가한다고 가정해봅시다.
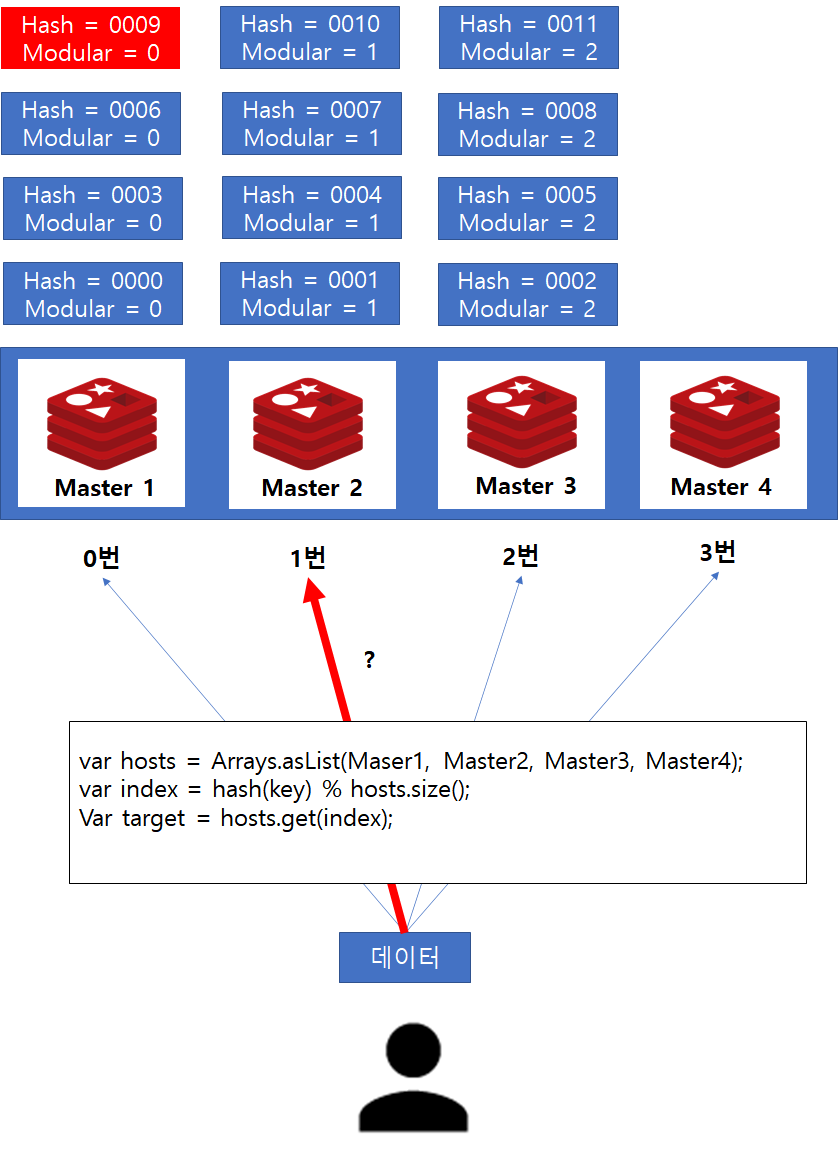
위와 같은 상황에서 기존과 같이 Hash 함수 9의 결과를 가지고 있는 Redis 서버를 찾고자하면 어떤일이 발생할까요?
서버의 개수가 증가하였으므로 9 % 4 = 1이되어 엉뚱한 서버에 질의 하는 결과를 낳게 됩니다.
따라서, 서버를 추가할 경우에는 그에 맞게 데이터의 재분배(Rebalancing) 작업이 필요합니다.
그럼 데이터 재분배를 진행한 결과를 살펴보겠습니다.

위 그림에서 초록색으로 표기된 데이터는 원래 노드에서 새로운 노드로 재분배된 데이터를 의미합니다.
이를 통해서 알 수 있는 사실은 Master 노드 추가 이후 75%의 데이터가 재분배 작업을 통해 다른 노드로 이전하였음을 확인할 수 있습니다. 이는 데이터를 재분배하는 과정에서 굉장히 많은 부하가 발생할 수 있으며, 운영중에 노드 추가 작업이 자유롭지 못함을 의미합니다.
따라서 단순 Modulo를 적용한 해시파티셔닝 전략으로는 신규 노드 추가/삭제 작업으로부터 자유롭지 못합니다.
그렇다면 어떻게 하면 데이터 재분배 작업을 최소화할 수 있을까요?
Consistent Hashing
이전에 살펴보았듯이, 노드 추가에 따른 Rebalancing 부하를 줄이기 위해서는 재분배되는 데이터 양이 적어야 합니다.
Consistent Hashing 기법은 데이터와 더불어 Master 서버에 대하여 동일한 해시 함수를 적용하고, Master 서버 해시값 구간에 해당되는 데이터를 저장하는 방법입니다.
예를 들어 설명하겠습니다.

위 그림과 같이 Redis Master 노드에 대하여 해시함수를 적용합니다.
그리고 해시함수 결과를 기준으로 데이터를 처리할 Master 노드를 결정합니다.
| 노드 | 데이터 담당 범위 |
| Master1 | 해시값 <= 10724 OR 해시값 > 12345 |
| Master2 | 10725 < 해시값 <= 11224 |
| Master3 | 11224 < 해시값 <= 11965 |
| Master4 | 11965 < 해시값 <= 12345 |
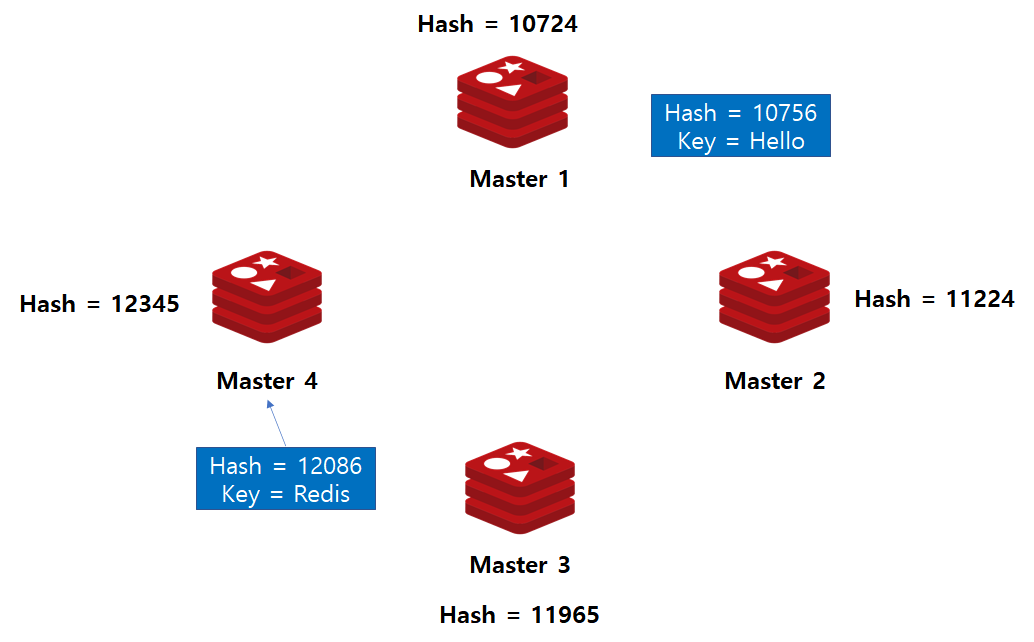
Case 1. 해시값 10756 데이터 입력시

Redis Master 서버에 대하여 해시 함수가 적용된 상황에서 해시 값이 10756인 데이터가 입력되었다고 가정해봅시다.
이는 10724보다는 크고 11224보다는 작으므로 Master2 노드가 해당 데이터의 저장소로 선정됩니다.
Case 2. 12086 해시값 데이터 입력시
12086 해시값 데이터가 입력되면, 12345 보다 작고 11965보다 크므로 Master4 노드가 해당 데이터의 저장소가 됩니다.
Case 3. 13567 해시값 데이터 입력시
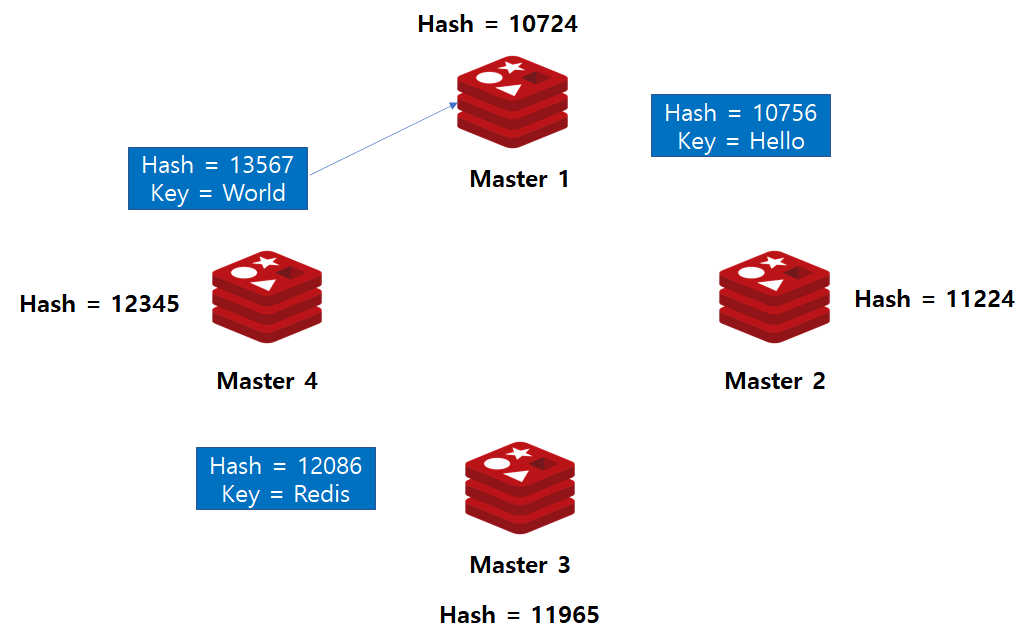
12345보다 큰 값이 입력되었으므로, 해당 데이터의 저장소는 Master 1번이 됩니다.
Case 4. 5576 해시값 데이터 입력시

10724보다 작은 데이터가 입력되었으므로 해당 데이터의 저장소는 Master 1번이 됩니다.
이렇듯 Consistent Hashing 기법에서는 서버를 추가하면 해시 함수를 적용하여 Hash Ring 형태로 만듭니다. 이후 입력되는 데이터는 해시 값 결과에 따라 저장소가 결정됩니다.
그렇다면 위와 같은 상황에서 노드가 삭제되거나 추가될 때 효율적인 Rebalancing이 일어날까요? Master 1 노드를 제거하는 상황을 가정해보겠습니다.

Master1 노드 삭제로 인해 Master1 노드가 가지고 있던 데이터를 재분배 해야하는 상황입니다. 따라서, 지금 상황에서는 Master2 노드가 Master1 노드의 데이터를 전부 이관 받아야하는 상황이며, 이는 효율적으로 데이터 재분배가 일어났다고 보기 힘듭니다.
그렇다면, 어떻게 해야 데이터를 효율적으로 나눌 수 있을까요?
가상 노드 추가
Hash Ring에 단일 노드만 배치하니까 발생한 문제는, 노드를 제거했을 때, 인접해있는 다른 노드 하나에 모든 데이터를 이관해야하는 문제점이 있습니다. 따라서 이를 해소하는 방법은 Hash Ring에 여러 가상 노드를 배치하는 것입니다.

위와 같이 하나의 노드가 아니라 여러개의 가상 노드를 Hash Ring에 배치하면, 노드와 데이터사이 해시 값 범위가 좁아집니다. 따라서 이런 상황에서 Master1 노드를 제거하면, 해당 노드의 데이터가 다른 노드로 적절히 분배될 수 있습니다.

위 사례는 Master1번 노드가 삭제된 이후 Master1번 노드가 가지고 있었던 데이터(빨간색 음영)가 다른 노드로 적절히 분산되었음을 확인할 수 있습니다.
만약, 노드를 추가할 경우에는 특정 노드가 담당하고 있던 적은 범위의 데이터 영역을 재분배합니다.
정리하자면, 해시 파티셔닝을 사용함으로 인하여 데이터를 균등하게 분포하면서, 데이터 재분배에 대한 영향도를 최소화 하기 위해서 Consistent Hashing 알고리즘을 이용할 수 있습니다. Consistent Hashing 알고리즘을 사용시 고려 사항은 Hash Ring에 가상 노드를 촘촘하게 그리고 노드가 간격을 균일하게 배치할 수 있도록 Hash 알고리즘이 적용되야 합니다. 특정 노드간의 범위가 벌어지게된다면, 그만큼 재분배해야할 데이터 양이 많아지므로 이를 유의해야 합니다.
참고
- 강대명님 블로그
마치며
이번 포스팅에서는 Redis 샤딩에 대해서 알아봤습니다. 처음 작성할 때 계획은 Redis Cluster까지 다루려고 했지만, 내용이 길어 여기서 마무리하도록 하겠습니다.
'DB > Redis' 카테고리의 다른 글
| 1. Redis 구조 (0) | 2020.08.09 |
|---|