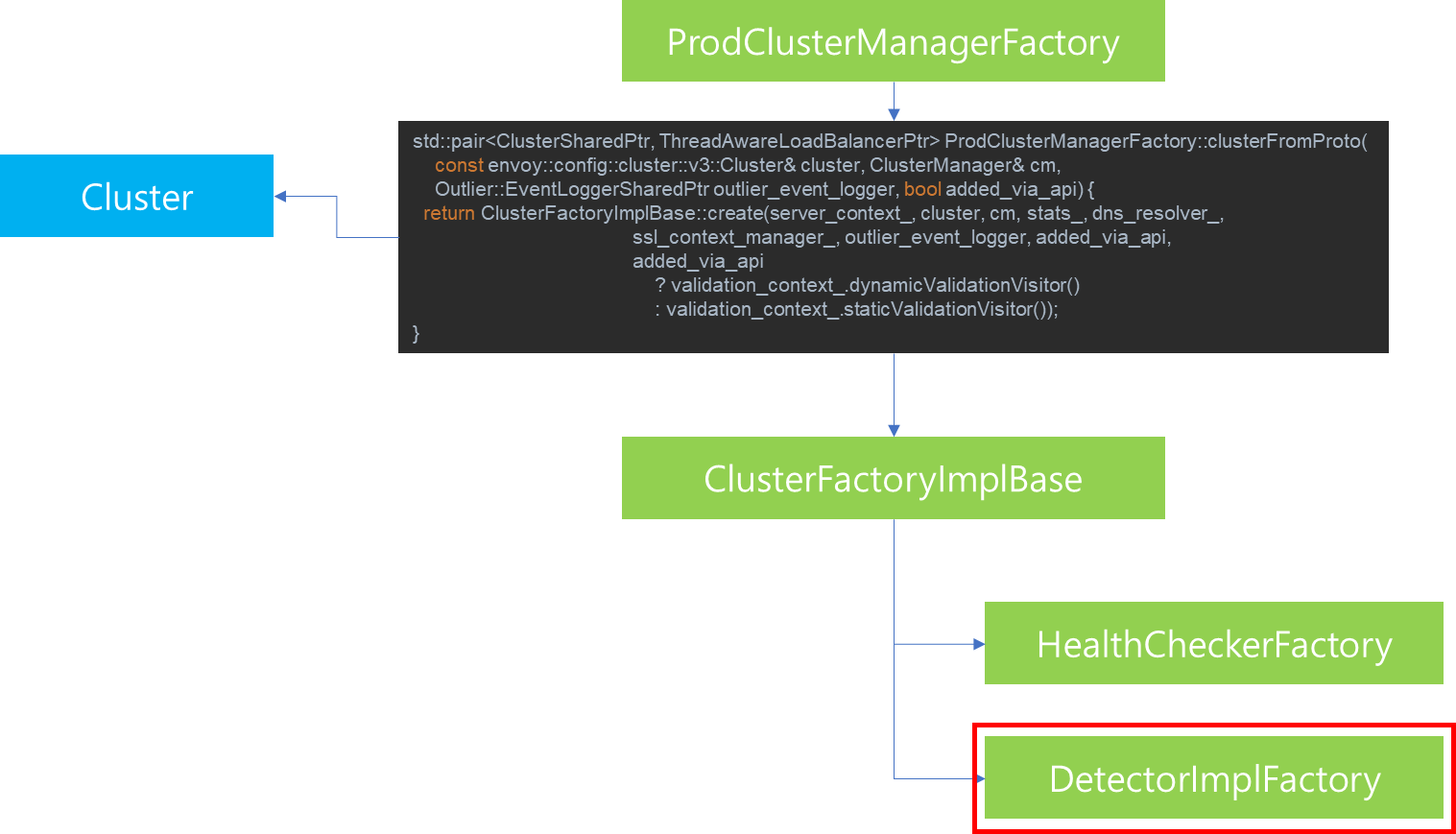
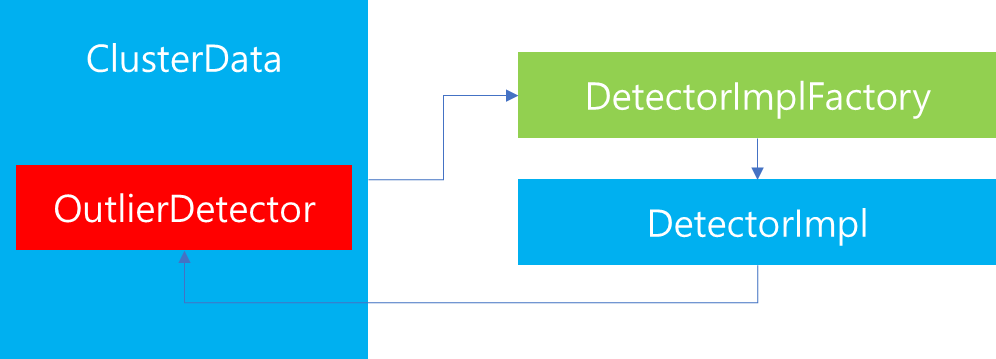
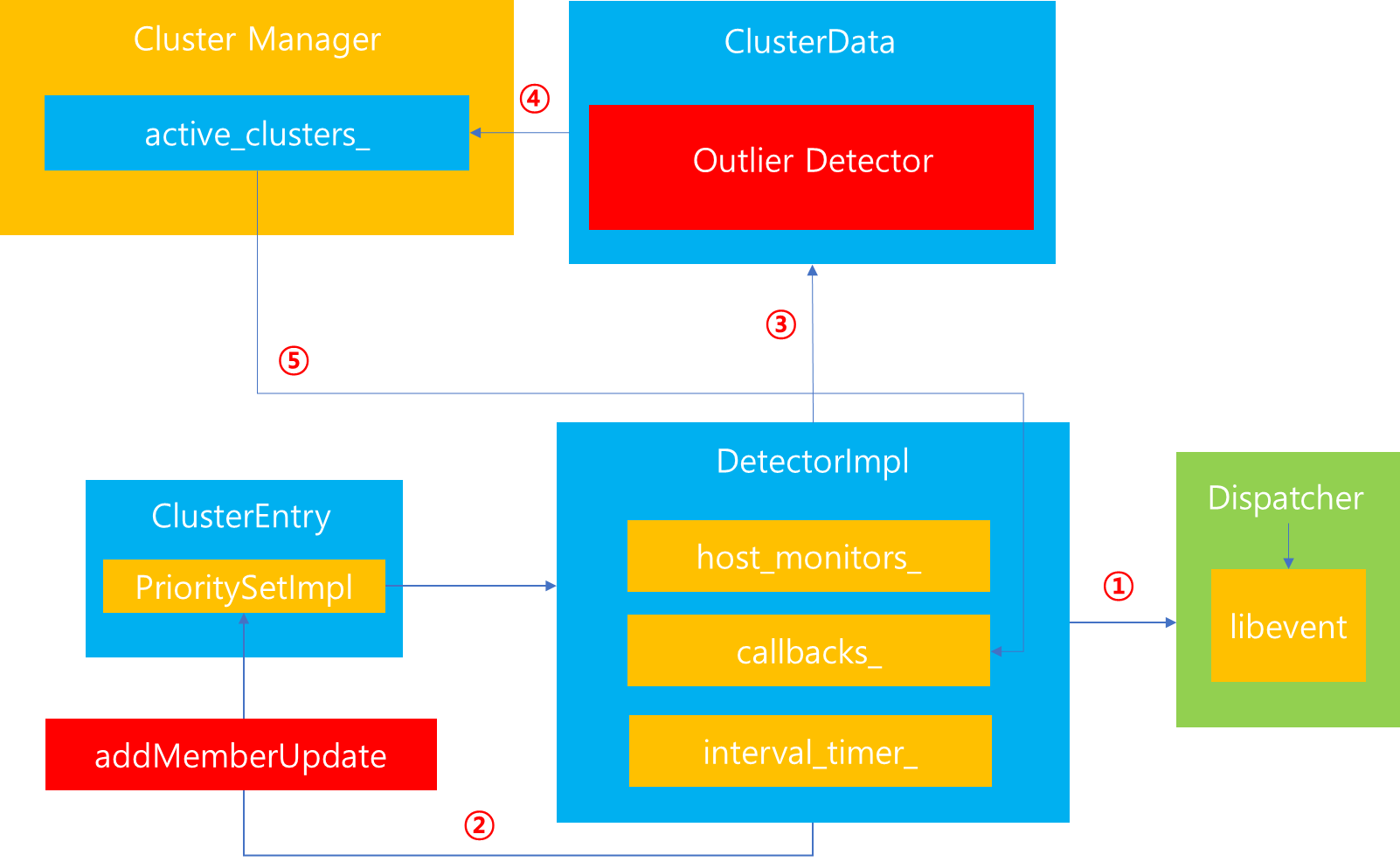
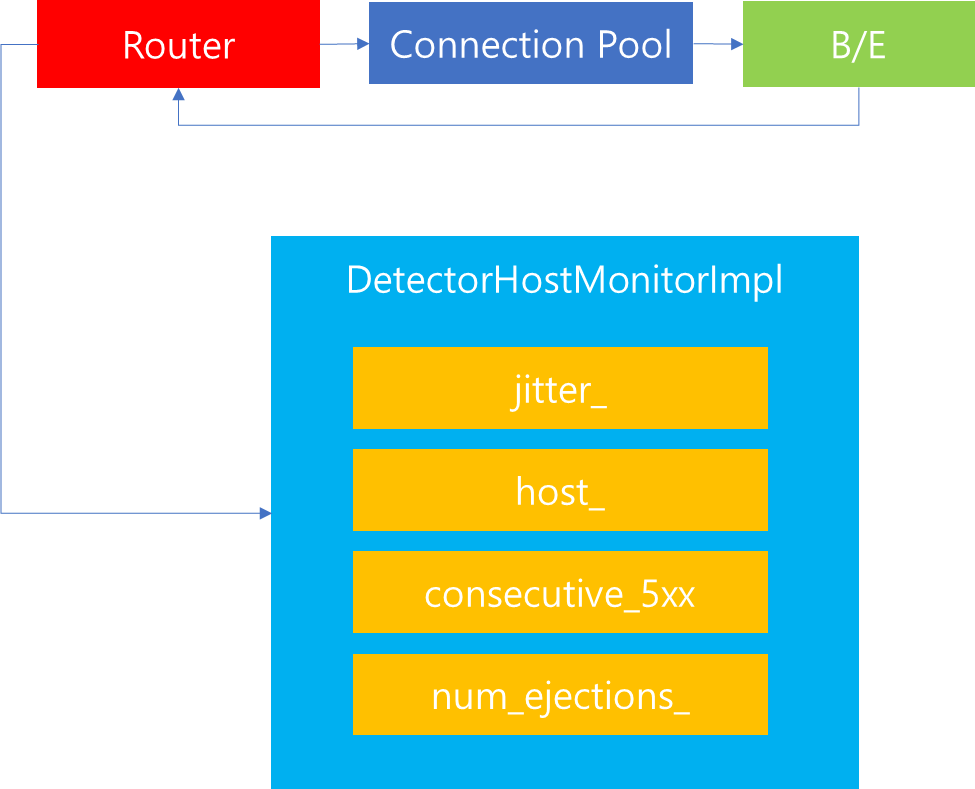
1. 서론
이전 시리즈 내용을 통해서 Envoy에서 가장 중요한 2가지 컴포넌트인 Listener Manager와 Cluster Manager에 대해서 살펴봤습니다.
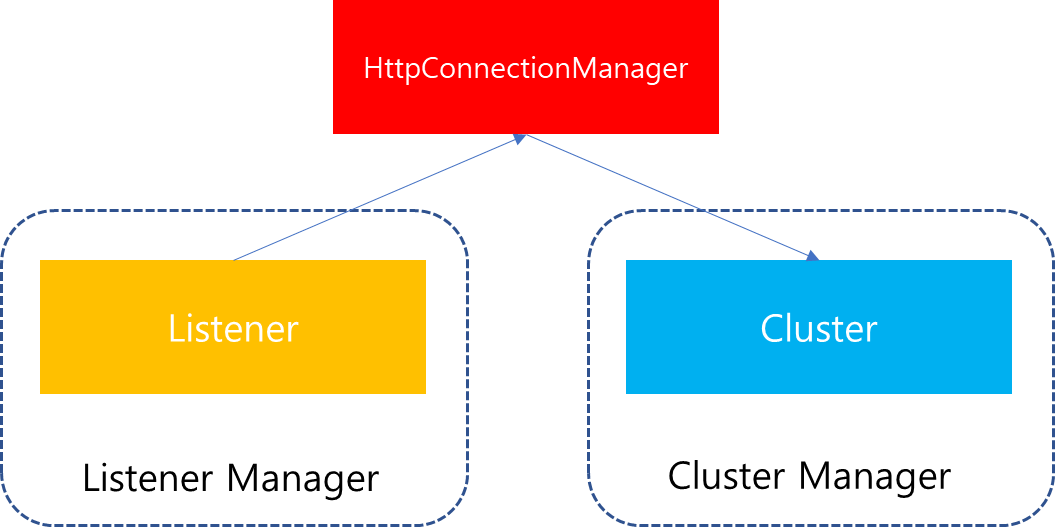
다시 한번 전체 과정을 간략하게 표현해보면 다음과 같습니다.사용자의 접속 요청이 전달되면, Listener에서 요청을 전달받고 이에 부합하는 Cluster를 찾아 Downstream과 Upstream을 연결합니다. 이때 만약 사용자 요청이 Http 연결일 경우에는 Listener에서 Cluster Manager로 Cluster를 요청하는 주체가 Listener가 보유하고 있는 Network Filter 중 하나인 HttpConnectionManager입니다. 해당 컴포넌트는 Listener 내부에 존재하는 Filter이지만, 사용자 요청처리를 수행하는데 있어 중요한 역할을 수행하기 때문에. 이번 포스팅에서는 HttpConnectionManager의 기능에 대해서 살펴보겠습니다.
2. HttpConnectionManager
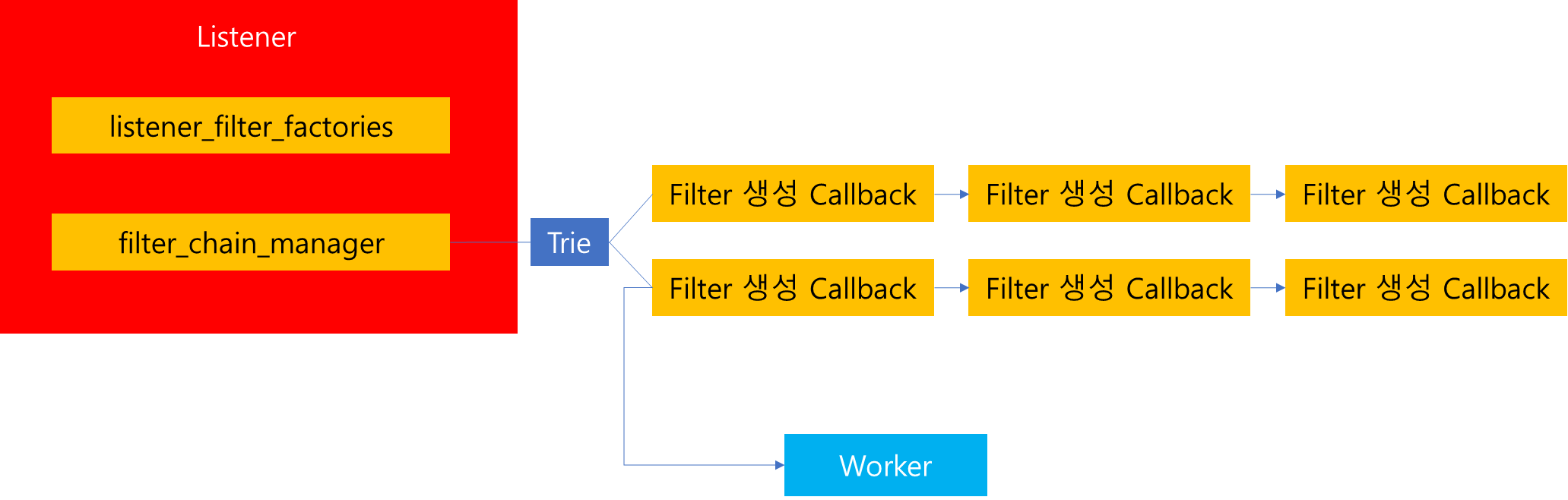
이전 포스팅을 통해 Listener 하위에는 위 그림과 같이 Filter Chains를 관리하는 filter_chain_manager가 존재함을 확인했습니다.
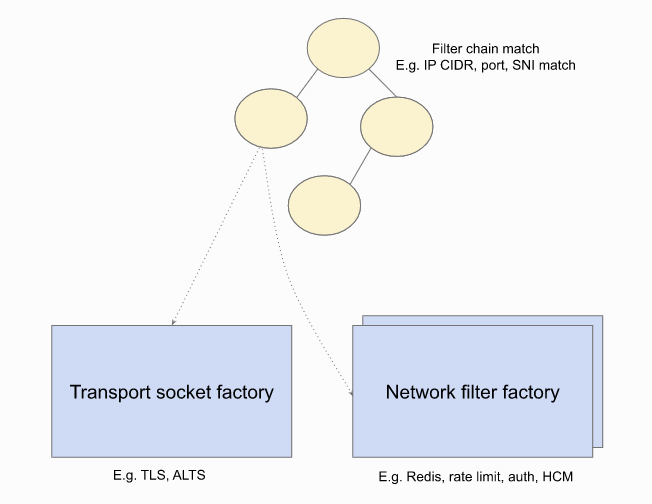
해당 구조 내부에는 위 그림과 같이 Trie 구조가 존재하는데, 이는 사용자가 Listener를 통해서 연결을 원하는 domain을 전달했을 때, 해당 요청에 부합되는 Filter Chain을 찾기 위한 용도로 사용됩니다. 따라서 각각의 Trie 별로 매칭되는 노드에는 Filter들이 Chain 형식으로 매핑되어있습니다.
따라서 사용자가 접속을 요청하면, 내부적으로는 해당 Trie를 검색해서 사용자의 요청에 부합되는 항목의 Filter Chain 목록을 반환합니다. 그리고 해당 Chain 목록을 전달받으면, Chain을 탐색하면서 매핑된 Factory Callback을 실행하여 Filter Chain을 구성합니다.
Envoy가 제공하는 Network Filter는 굉장히 많은 종류가 있는데요. 그 중 HttpConnectionManager는 Http 요청을 처리하는 Filter로써 이에 대해서 다루어보고자 합니다.

HttpConnectionManager는 Network Filter이므로 앞서 설명한 것과 같이 사용자가 명시한 도메인에 해당되는 Network Filter 목록에 Http 처리가 매핑되어있을 경우 Filter Chain에 포함되어있을 것입니다.
이때 사용자가 Listener에 접속을 요청할 때마다 위 그림과 같이 내부적으로 Upstream Connection을 만듭니다. 위 그림은 현재 2개의 Connection이 생성되었음을 가정했습니다. 이때 각각의 ServerConnection은 별개의 Network Filter Chain을 가지고 있게되고 만약 2개의 Connection이 모두 Http 처리를 담당해야한다면 위 그림과 같이 2개의 별개 HttpConnectionManager가 생성될 것입니다.
그렇다면 HttpConnectionManager는 어떻게 구성되어있을까요?

생성된 HttpConnectionManager는 대략 위와 같은 모습을 구성하고 있습니다. 물론 그림으로 표현한 속성 이외에 다양한 프로퍼티가 존재하지만, 핵심이라고 생각하는 몇 개만 표현했습니다. 그렇다면 각각의 속성은 무엇이며 어떤 과정을 거쳐 생성될까요? 핵심적인 요소에 대해서 하나씩 살펴보겠습니다.
3. RDS
먼저 살펴볼 것은 RDS입니다. 해당 컴포넌트는 이전에 살펴본 HttpConnectionManager의 속성 중 config_와 관련이 있습니다. 해당 config안에는 HttpConnectionManager를 구성하는데 있어 필요한 속성이 지정되어있는데요. 그중 Route 관련 속성은 route_config_provider입니다.
이전에 살펴본 그림에서 HttpConnectionManager와 SingletonManager가 연관관계를 맺고 있는 것을 확인했는데요. SingletonManager가 가진 속성 중에서 RouteConfigProviderManager가 RDS 처리를 담당하고 있습니다.
그렇다면 왜 SingletonManager에 의해서 해당 속성이 관리될까요? 위 그림을 살펴보면 HttpConnectionManager는 사용자의 Connection 별로 여러개가 생성됨을 볼 수 있습니다. 하지만 RDS 처리 또한 각각의 HttpConnectionManager를 통해 관리되어야한다면, RDS 처리를 위한 overhead 또한 증가하게되고 무엇보다 동일한 정보가 중복 관리되기 때문에 관리 용이성 또한 증가합니다. 따라서 전역적으로 하나의 인스턴스만을 생성함으로써 데이터를 한 곳에서 관리하고 모든 HttpConnectionManager가 이를 공유하도록 싱글톤 패턴이 적용되어있습니다.
해당 내용을 코드로 살펴보면 다음과 같습니다.
config.cc
Utility::Singletons Utility::createSingletons(Server::Configuration::FactoryContext& context) {
std::shared_ptr<Http::TlsCachingDateProviderImpl> date_provider =
context.singletonManager().getTyped<Http::TlsCachingDateProviderImpl>(
SINGLETON_MANAGER_REGISTERED_NAME(date_provider), [&context] {
return std::make_shared<Http::TlsCachingDateProviderImpl>(
context.mainThreadDispatcher(), context.threadLocal());
});
Router::RouteConfigProviderManagerSharedPtr route_config_provider_manager =
context.singletonManager().getTyped<Router::RouteConfigProviderManager>(
SINGLETON_MANAGER_REGISTERED_NAME(route_config_provider_manager), [&context] {
return std::make_shared<Router::RouteConfigProviderManagerImpl>(context.admin());
});
Router::ScopedRoutesConfigProviderManagerSharedPtr scoped_routes_config_provider_manager =
context.singletonManager().getTyped<Router::ScopedRoutesConfigProviderManager>(
SINGLETON_MANAGER_REGISTERED_NAME(scoped_routes_config_provider_manager),
[&context, route_config_provider_manager] {
return std::make_shared<Router::ScopedRoutesConfigProviderManager>(
context.admin(), *route_config_provider_manager);
});
auto http_tracer_manager = context.singletonManager().getTyped<Tracing::HttpTracerManagerImpl>(
SINGLETON_MANAGER_REGISTERED_NAME(http_tracer_manager), [&context] {
return std::make_shared<Tracing::HttpTracerManagerImpl>(
std::make_unique<Tracing::TracerFactoryContextImpl>(
context.getServerFactoryContext(), context.messageValidationVisitor()));
});
std::shared_ptr<Http::DownstreamFilterConfigProviderManager> filter_config_provider_manager =
Http::FilterChainUtility::createSingletonDownstreamFilterConfigProviderManager(
context.getServerFactoryContext());
return {date_provider, route_config_provider_manager, scoped_routes_config_provider_manager,
http_tracer_manager, filter_config_provider_manager};
}
코드를 살펴보면 위와 같이 가장 먼저 하는 것은 SingletonManager에 등록된 인스턴스 중에서 RouteConfigProviderManager, ScopedRoutesConfigProviderManager 와 더불어 다양한 Manager 등 다양한 Manager를 가져오는 작업을 선행합니다.
이때 중요한 것은 앞서 언급한 2가지 Manager이며, RouteConfigProviderManager는 route_config 정보를 기반으로 RDS 혹은 StaticRouteConfig를 처리하는 인스턴스를 생성하는 역할을 수행합니다. 반면 ScopedRoutesConfigProviderManager는 Listener 설정에 scoped_routes 설정이 존재할 때 해당 scoped_routes를 처리하는 인스턴스를 생성하는 역할을 수행합니다.
config.cc
switch (config.route_specifier_case()) {
case envoy::extensions::filters::network::http_connection_manager::v3::HttpConnectionManager::
RouteSpecifierCase::kRds:
case envoy::extensions::filters::network::http_connection_manager::v3::HttpConnectionManager::
RouteSpecifierCase::kRouteConfig:
route_config_provider_ = Router::RouteConfigProviderUtil::create(
config, context_.getServerFactoryContext(), context_.messageValidationVisitor(),
context_.initManager(), stats_prefix_, route_config_provider_manager_);
break;
case envoy::extensions::filters::network::http_connection_manager::v3::HttpConnectionManager::
RouteSpecifierCase::kScopedRoutes:
scoped_routes_config_provider_ = Router::ScopedRoutesConfigProviderUtil::create(
config, context_.getServerFactoryContext(), context_.initManager(), stats_prefix_,
scoped_routes_config_provider_manager_);
break;
case envoy::extensions::filters::network::http_connection_manager::v3::HttpConnectionManager::
RouteSpecifierCase::ROUTE_SPECIFIER_NOT_SET:
PANIC_DUE_TO_CORRUPT_ENUM;
}
HttpConnectionManager를 구성하는 단계에서 전달받은 두 속성은 이후 route 관련 정보를 생성하는데 사용됩니다. 다만 두 속성 모두가 생성되지는 않으며, 기존에 지정된 설정내역을 살펴보고 하나를 생성합니다.
즉 위 코드와 같이 config에 지정된 route_specifier에 의해서 결정됩니다. 만약 route_config 설정이 지정되어있다면, 기존에 SingletonManager로부터 부여받은 route_config_provider_manager를 전달하여 route 처리를 수행할 수 있는 route_config_provider를 전달받습니다. 반면 scoped_route라면 scoped_route_config_provider_manager를 전달하여 scoped_route_config_provider를 전달받습니다.
본포스팅에서는 route_config만 지정되어있음을 가정하며, 따라서 위 코드에서는 route_config_provider_ 만이 생성되었음을 전제로 진행하겠습니다. 또한 route를 처리하는 방식이 static이 아닌 dynamic xDS를 활용한 동적 변경을 가정하겠습니다.
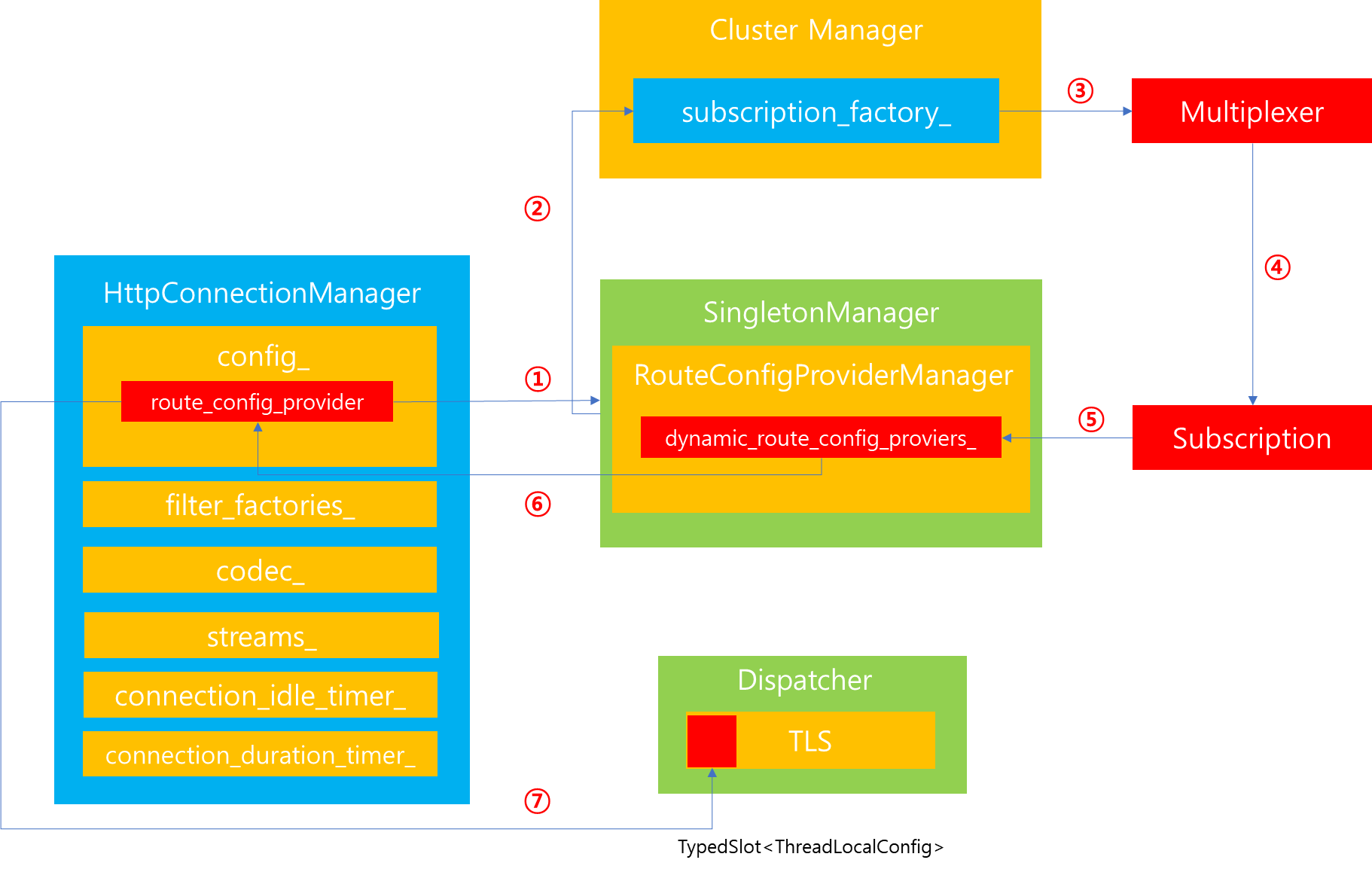
route_config_provider가 생성된 이후 RDS를 매핑하는 과정을 살펴보면 위그림과 같습니다.
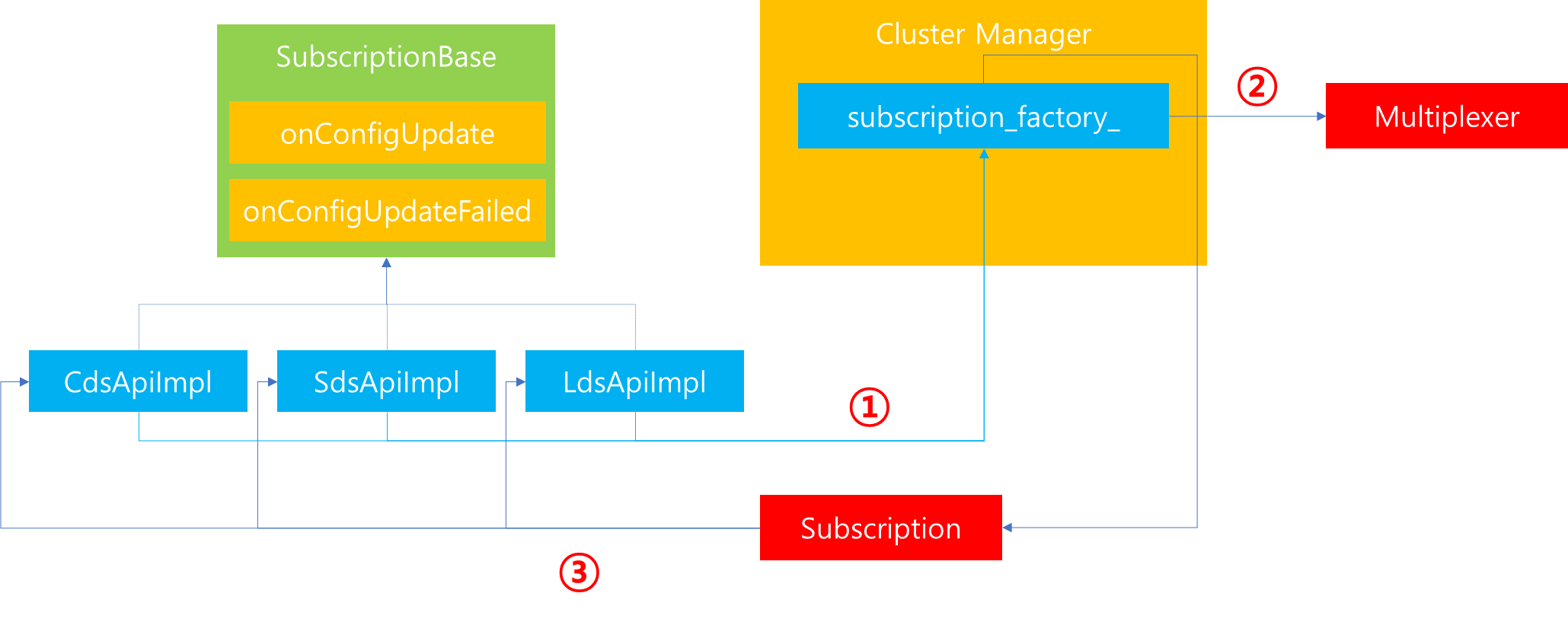
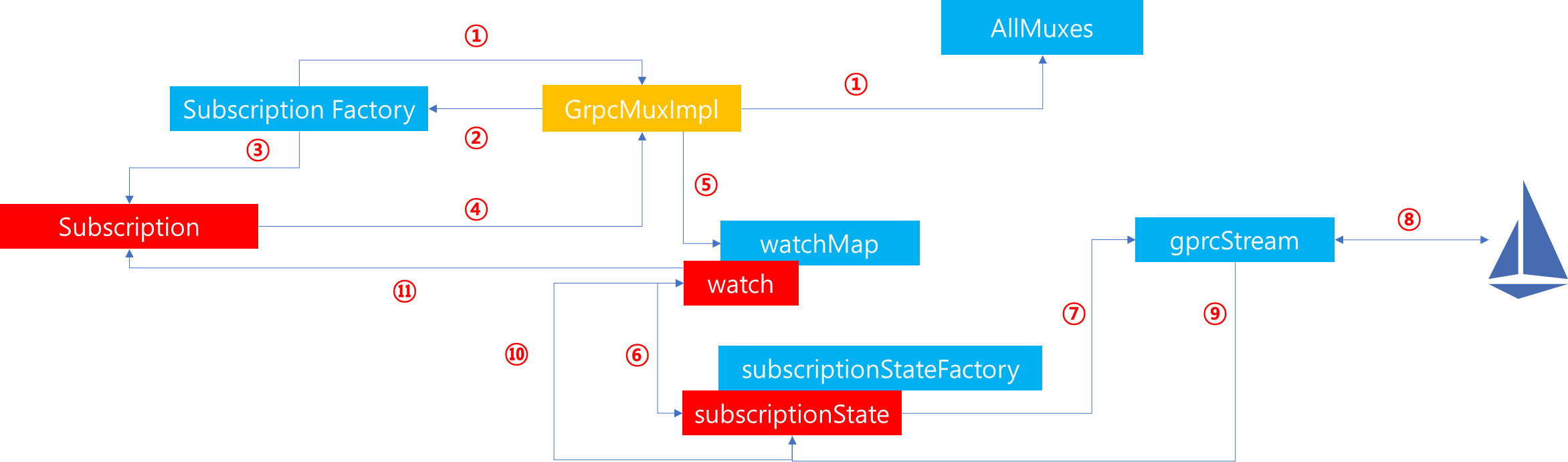
1. HttpConnectionManager에 매핑되어있는 route_config_provider를 기반으로 route config를 분석할 수 있는 인스턴스를 생성합니다. 이후 RouteConfigProviderManager에 존재하는 dynamic_route_config_providers_ 로부터 rds 메시지 값을 해시한 결과를 기반으로 dynamic_route_config_providers_ Map에 존재하는지 살펴보고 만약 존재한다면, 해당 provider를 반환합니다.
2. dynamic_route_config_providers_에 존재하지 않는다면, RDS 생성을 위해 Cluster Manager로부터 Subscription factory를 요청합니다.
3. xDS에 전달받기 원하는 타입 및 수신 callback을 Multiplexer에 등록합니다.
4. 등록이 완료된 이후 Subscription을 반환합니다.
5. RdsRouteConfigProviderImpl 인스턴스를 생성하고 그 안에 subscription을 바인딩합니다. 또한 dynamic_route_config_providers_ Map에 해당 인스턴스를 삽입함으로써 이후 동일한 요청이 전달되면, 새로운 provider를 생성하지 않고 매핑된 값을 반환합니다.
route_config_provider_manager_impl.h
auto subscription = std::make_shared<RdsRouteConfigSubscription>(
std::move(config_update), std::move(resource_decoder), rds.config_source(),
rds.route_config_name(), manager_identifier, factory_context,
stat_prefix + absl::AsciiStrToLower(getRdsName()) + ".",
absl::AsciiStrToUpper(getRdsName()), manager_);
auto provider = std::make_shared<RdsRouteConfigProviderImpl>(std::move(subscription),
factory_context);6. 해당 provider와 subscription 정보를 반환합니다.
7. RdsRouteConfigProviderImpl 내부에서는 xDS API가 변경이 생겼을 때, 내부에서 ThreadLocalStorage에 존재하는 ThreadLocalConfig의 내용을 변경함으로써, 쓰레드 전체에 동일한 데이터를 공유할 수 있도록 유지합니다.
위와 같은 7가지 단계를 통해서 HttpConnectionManager가 생성될 때 Singleton Manager를 통해 전역적으로 RDS를 관리하는 하나의 provider를 공급받고, ThreadLocalStorage를 활용해서 모든 쓰레드에서 동일한 데이터에 대한 접근이 가능하도록 공유합니다.
4. Http filter
HttpConnectionManager는 Http 처리를 담당합니다. 이때 해당 컴포넌트 내부에는 http 처리를 위한 무수한 filter가 존재합니다. 참고로 envoy 공식 문서를 살펴보면 지정할 수 있는 filter가 여러가지 있음을 확인할 수 있습니다. 그리고 그 중에는 Routing을 담당하는 Router Filter 또한 존재합니다.
따라서 사용자의 요청이 전달되면 Network Filter Chain이 수행되면서 HttpConnectionManager가 실행되고 그리고 그 안에서 다시 HttpConnectionManager가 보유한 Http Filter들이 수행되면서 사용자의 요청이 처리됩니다.
이를 조금 더 살펴보겠습니다.
config.cc
Http::FilterChainHelper<Server::Configuration::FactoryContext,
Server::Configuration::NamedHttpFilterConfigFactory>
helper(filter_config_provider_manager_, context_.getServerFactoryContext(), context_,
stats_prefix_);
helper.processFilters(config.http_filters(), "http", "http", filter_factories_);
HttpConnectionManager를 구성하는 config 속성을 살펴보면, 해당 Config를 생성할 때 http_filters를 위한 factory를 생성하는 것을 볼 수 있습니다. 이때 이미 사용자가 지정하거나 LDS에 의해서 갱신된 Listener의 Config 정보를 살펴보면, 지정된 http filter 목록을 확인할 수 있습니다.
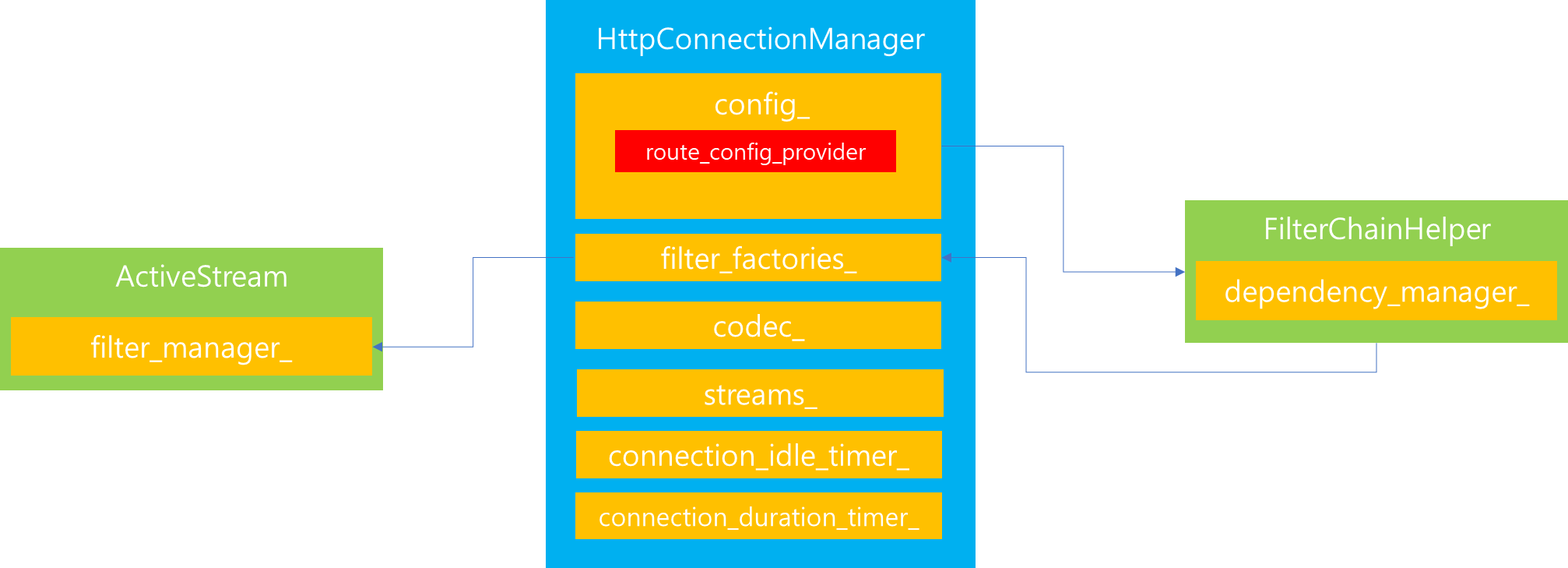
따라서 FilterChainHelper를 통해서 Config 정보를 토대로 filter_factories라는 Filter를 생성하는 Factory Callback의 리스트를 채우도록 처리를 위임합니다.
FilterChainHelper는 해당 요청을 전달받으면, DependencyManager를 통해서 전달된 Filter의 우선순위를 고려하여 정상적으로 입력이 되었는지를 검사합니다. 그리고 Filter간의 Dependency에 문제가 없게 Config가 전달되었다면, 이를 HttpConnectionManager가 보유한 filter_factories에 Filter 생성을 위한 Callback Factory 메소드를 매핑시킵니다.
위 과정을 거쳐 생성된 filter_factories_는 향후 사용자가 Http 요청을 전달하기 위해 Stream을 생성할 때 내부에 존재하는 filter_manager_로 해당 filter_factories_를 전달시켜 해당 filter_manager_가 http filter chain을 생성하고 수행할 수 있도록 처리를 위임합니다.
5. Codec
이번에 살펴볼 것은 codec입니다. HttpConnectionManager에서 codec은 사용자의 요청 정보를 분석하는 역할을 수행합니다. 사용자가 전달한 raw데이터를 지정된 프로토콜 형태로 파싱하고 분석하여 처리하는 과정에서 사용됩니다.

그림을 살펴보면, codec_은 HttpConnectionManager 내부에 있는 config에 의해서 생성할 수 있습니다. 이때 사용자의 Http 요청은 Http 1.1, Http 2.0 혹은 Http 3.0(Quic) 형태일 수 있습니다. 위 세가지 프로토콜 모두 HttpConnectionManager가 처리하는데요. 각각의 처리방식과 포맷이 다르기 때문에 사용자의 요청이 전달되었을 때, 가정 먼저 수행하는 일은 사용자의 요청이 어떤 프로토콜 형태인지를 파악하는 것입니다.
config.cc
Http::ServerConnectionPtr
HttpConnectionManagerConfig::createCodec(Network::Connection& connection,
const Buffer::Instance& data,
Http::ServerConnectionCallbacks& callbacks) {
switch (codec_type_) {
case CodecType::HTTP1:
return std::make_unique<Http::Http1::ServerConnectionImpl>(
connection, Http::Http1::CodecStats::atomicGet(http1_codec_stats_, context_.scope()),
callbacks, http1_settings_, maxRequestHeadersKb(), maxRequestHeadersCount(),
headersWithUnderscoresAction());
case CodecType::HTTP2:
return std::make_unique<Http::Http2::ServerConnectionImpl>(
connection, callbacks,
Http::Http2::CodecStats::atomicGet(http2_codec_stats_, context_.scope()),
context_.api().randomGenerator(), http2_options_, maxRequestHeadersKb(),
maxRequestHeadersCount(), headersWithUnderscoresAction());
case CodecType::HTTP3:
#ifdef ENVOY_ENABLE_QUIC
return std::make_unique<Quic::QuicHttpServerConnectionImpl>(
dynamic_cast<Quic::EnvoyQuicServerSession&>(connection), callbacks,
Http::Http3::CodecStats::atomicGet(http3_codec_stats_, context_.scope()), http3_options_,
maxRequestHeadersKb(), maxRequestHeadersCount(), headersWithUnderscoresAction());
#else
// Should be blocked by configuration checking at an earlier point.
PANIC("unexpected");
#endif
case CodecType::AUTO:
return Http::ConnectionManagerUtility::autoCreateCodec(
connection, data, callbacks, context_.scope(), context_.api().randomGenerator(),
http1_codec_stats_, http2_codec_stats_, http1_settings_, http2_options_,
maxRequestHeadersKb(), maxRequestHeadersCount(), headersWithUnderscoresAction());
}
PANIC_DUE_TO_CORRUPT_ENUM;
}
이를 Config에서 분석한 다음 Http 1.1일 경우에는 Http1::ServerConnectionImpl, Http 2.0일 경우에는 Http2:ServerConnectionImpl Http 3.0일 경우에는 QuicHttpServerConnectionImpl을 반환하여 HttpConnectionManager 내부에 존재하는 codec_에 매핑하는 작업을 수행합니다.
codec.h
class Connection {
public:
virtual ~Connection() = default;
/**
* Dispatch incoming connection data.
* @param data supplies the data to dispatch. The codec will drain as many bytes as it processes.
* @return Status indicating the status of the codec. Holds any errors encountered while
* processing the incoming data.
*/
virtual Status dispatch(Buffer::Instance& data) PURE;
/**
* Indicate "go away" to the remote. No new streams can be created beyond this point.
*/
virtual void goAway() PURE;
/**
* @return the protocol backing the connection. This can change if for example an HTTP/1.1
* connection gets an HTTP/1.0 request on it.
*/
virtual Protocol protocol() PURE;
/**
* Indicate a "shutdown notice" to the remote. This is a hint that the remote should not send
* any new streams, but if streams do arrive that will not be reset.
*/
virtual void shutdownNotice() PURE;
/**
* @return bool whether the codec has data that it wants to write but cannot due to protocol
* reasons (e.g, needing window updates).
*/
virtual bool wantsToWrite() PURE;
/**
* Called when the underlying Network::Connection goes over its high watermark.
*/
virtual void onUnderlyingConnectionAboveWriteBufferHighWatermark() PURE;
/**
* Called when the underlying Network::Connection goes from over its high watermark to under its
* low watermark.
*/
virtual void onUnderlyingConnectionBelowWriteBufferLowWatermark() PURE;
};
프로토콜마다 처리 방법이 다양하지만, 모든 ServerConnectionImpl은 위와 같은 Interface 스펙을 준수합니다. 따라서 HttpConnectionManager에서는 위 interface에 정의된 메소드를 호출하여 처리를 위임할 수 있습니다. 다만 본 포스팅에서는 Http 1.1을 기준으로 처리 과정을 분석하기 때문에 Http1::ServerConnectionImpl이 반환되었다고 가정하겠습니다.
그렇다면 Http 1.1을 처리하기 위한 ServerConnectionImpl은 어떤 역할을 수행할까요? 해당 구조에 대해서 조금 더 자세히 살펴보겠습니다.

ServerConnectionImpl을 살펴보면, 여러 속성이 있지만 그 중 가장 중요한 속성은 위 2가지 입니다. 먼저 Parser_에 대해서 알아보겠습니다.
5-1. Parser
parser_의 역할은 Client로 부터 전달된 요청 내역을 Http 1.1 스펙에 맞게 분석하여 envoy가 원하는 형태로 데이터를 구성하는 작업을 담당합니다. 이때 envoy 내부에는 해당 내역을 처리하는 Parser가 2개가 존재합니다.
codec_impl.cc
ConnectionImpl::ConnectionImpl(Network::Connection& connection, CodecStats& stats,
const Http1Settings& settings, MessageType type,
uint32_t max_headers_kb, const uint32_t max_headers_count)
: connection_(connection), stats_(stats), codec_settings_(settings),
encode_only_header_key_formatter_(encodeOnlyFormatterFromSettings(settings)),
processing_trailers_(false), handling_upgrade_(false), reset_stream_called_(false),
deferred_end_stream_headers_(false), dispatching_(false), max_headers_kb_(max_headers_kb),
max_headers_count_(max_headers_count) {
if (Runtime::runtimeFeatureEnabled("envoy.reloadable_features.http1_use_balsa_parser")) {
parser_ = std::make_unique<BalsaParser>(type, this, max_headers_kb_ * 1024, enableTrailers());
} else {
parser_ = std::make_unique<LegacyHttpParserImpl>(type, this);
}
}
첫 번째는 LegacyHttpParserImpl로써 envoy가 기존부터 제공해온 Parser입니다. 이후 해당 Parser의 성능 개선을 위해 추가로 개발한 것이 BalsaParser입니다. 다만 BalsaParser는 아직 완전하지는 않으며, envoy에서 해당 Parser를 사용하려면
'envoy.reloadable_features.http1_use_balsa_parser' 옵션을 활성화했을 경우 사용할 수 있습니다. 참고로 본 포스팅에서는 기본으로 사용되는 LegacyHttpParserImpl에 대해서 다루어보겠습니다.

parser_가 생성되면, 추후 parser_에게 사용자 요청을 처리하도록 위임할 것입니다. 이때 Parser가 처리 중간 중간마다 특정 event 즉 header 필드명이 무엇인지 하나씩 파악했거나, header 값을 분석했을 때 이를 요청자인 ServerConnection 에게 알려줘야 해당 데이터들을 전달받아 envoy가 원하는 형태로 데이터를 가공하거나 그 이후 처리해야할 비즈니스 로직을 수행할 수 있을 것입니다.
이때 ServerConnectionImpl은 기본적으로 ParserCallbacks Virtual Class를 상속받았으며, 그 안에 정의된 메소드는 해당 메소드가 호출될 때 수행해야할 비즈니스 로직이 구현되어있습니다. 구현해야할 메소드는 위와 같이 총 10개이며, 각각의 의미는 다음과 같습니다.
| 메소드명 | 의미 |
| onMessageBegin | Request/Response가 시작될 때 호출되는 callback으로 반환 값으로 성공/실패 메시지가 반환됨 |
| onUrl | URL data를 Parser가 분석했을 때 호출되는 callback으로 반환 값으로 성공/실패 메시지가 반환됨 |
| onStatus | Status data를 Parser가 분석헀을 때 호출되는 callback으로 반환 값으로 성공/실패 메시지가 반환됨 |
| onHeaderField | header의 field 명을 수신받았을 때 호출되는 callback으로 반환 값으로 성공/실패 메시지가 반환됨 |
| onHeaderValue | header의 value 값을 수신받았을 때 호출되는 callback으로 반환 값으로 성공/실패 메시지가 반환됨 |
| onHeaderComplete | header 분석이 완료되었을 때 호출되는 callback으로 반환 값으로 성공/실패 메시지가 반환됨 |
| bufferBody | body data를 분석했을 때 호출되는 callback |
| onMessageComplete | Parser가 HTTP 데이터를 모두 분석 완료했을 때 호출되는 callback으로 반환 값으로 성공/실패 메시지가 반환됨 |
| onChunkHeader | chunk header를 받았을 때 호출되는 callback |
이후 Parser에서는 처리 도중 중간 중간에 ParserCallbacks에 정의된 메소드를 호출함으로써, ServerConnectionImpl에게 Parsing 결과를 중간 중간 callback 하도록 구현되었습니다.
legacy_parser_impl.cc
Impl(http_parser_type type, void* data) : Impl(type) {
parser_.data = data;
settings_ = {
[](http_parser* parser) -> int {
auto* conn_impl = static_cast<ParserCallbacks*>(parser->data);
return static_cast<int>(conn_impl->onMessageBegin());
},
[](http_parser* parser, const char* at, size_t length) -> int {
auto* conn_impl = static_cast<ParserCallbacks*>(parser->data);
return static_cast<int>(conn_impl->onUrl(at, length));
},
[](http_parser* parser, const char* at, size_t length) -> int {
auto* conn_impl = static_cast<ParserCallbacks*>(parser->data);
return static_cast<int>(conn_impl->onStatus(at, length));
},
[](http_parser* parser, const char* at, size_t length) -> int {
auto* conn_impl = static_cast<ParserCallbacks*>(parser->data);
return static_cast<int>(conn_impl->onHeaderField(at, length));
},
[](http_parser* parser, const char* at, size_t length) -> int {
auto* conn_impl = static_cast<ParserCallbacks*>(parser->data);
return static_cast<int>(conn_impl->onHeaderValue(at, length));
},
[](http_parser* parser) -> int {
auto* conn_impl = static_cast<ParserCallbacks*>(parser->data);
return static_cast<int>(conn_impl->onHeadersComplete());
},
[](http_parser* parser, const char* at, size_t length) -> int {
static_cast<ParserCallbacks*>(parser->data)->bufferBody(at, length);
return 0;
},
[](http_parser* parser) -> int {
auto* conn_impl = static_cast<ParserCallbacks*>(parser->data);
return static_cast<int>(conn_impl->onMessageComplete());
},
[](http_parser* parser) -> int {
// A 0-byte chunk header is used to signal the end of the chunked body.
// When this function is called, http-parser holds the size of the chunk in
// parser->content_length. See
// https://github.com/nodejs/http-parser/blob/v2.9.3/http_parser.h#L336
const bool is_final_chunk = (parser->content_length == 0);
static_cast<ParserCallbacks*>(parser->data)->onChunkHeader(is_final_chunk);
return 0;
},
nullptr // on_chunk_complete
};
}
즉 위 코드와 같이 LegacyHttpParserImpl 내부에는 Parsing 중간 중간 처리 결과를 반환할 수 있도록, settings_에 함수를 매핑했는데, 이때 ParserCallbacks에 정의된 규약에 따른 메소드를 호출하여 결과를 전달하는 것을 볼 수 있습니다.
5-2. Active Request
이번에는 Http1::ServerConnectionImpl이 보유하고 있는 속성 중 두번째인 active_request_ 에 대해서 알아보겠습니다.
codec_impl.h
struct ActiveRequest : public Event::DeferredDeletable {
ActiveRequest(ServerConnectionImpl& connection, StreamInfo::BytesMeterSharedPtr&& bytes_meter)
: response_encoder_(connection, std::move(bytes_meter),
connection.codec_settings_.stream_error_on_invalid_http_message_) {}
~ActiveRequest() override = default;
void dumpState(std::ostream& os, int indent_level) const;
HeaderString request_url_;
RequestDecoder* request_decoder_{};
ResponseEncoderImpl response_encoder_;
bool remote_complete_{};
};
ActiveRequest는 위와 같이 Parser에 의해서 데이터를 Parsing 하는 과정에서 RequestDecoder, url, ResponseEncoder 등을 가지고 있는 구조체입니다. 해당 구조체를 통해서 Parsing 단계에서 connection 객체에 대한 작업 요청 및 url, encoder 지정 및 수행등을 담당합니다.
해당 자료구조가 사용되는 흐름을 보려면 사용자 요청을 처리하는 전단계를 살펴봐야하는데요. 이번 포스팅은 HttpConnectionManager의 특징에 대해서 살펴보기 때문에 ActiveRequest의 존재에 대해서만 이번 포스팅에서는 언급하고 해당 자료구조의 쓰임새는 다음 포스팅에서 보다 자세히 다루어보겠습니다.
6. Stream
이번에는 HttpConnectionManager가 관리하는 Stream 목록에 대해서 살펴보겠습니다. Stream은 Http 요청을 전달하는 하나의 흐름으로써, 하나의 Connection을 맺은 상태로 Http 요청을 전달하기 위해 여러 Stream을 생성할 수 있습니다. 따라서 이러한 개별 Stream들의 그룹을 관리하기 위해서 HttpConnectionManager 내부에는 streams_라는 List를 보유하고 있습니다.
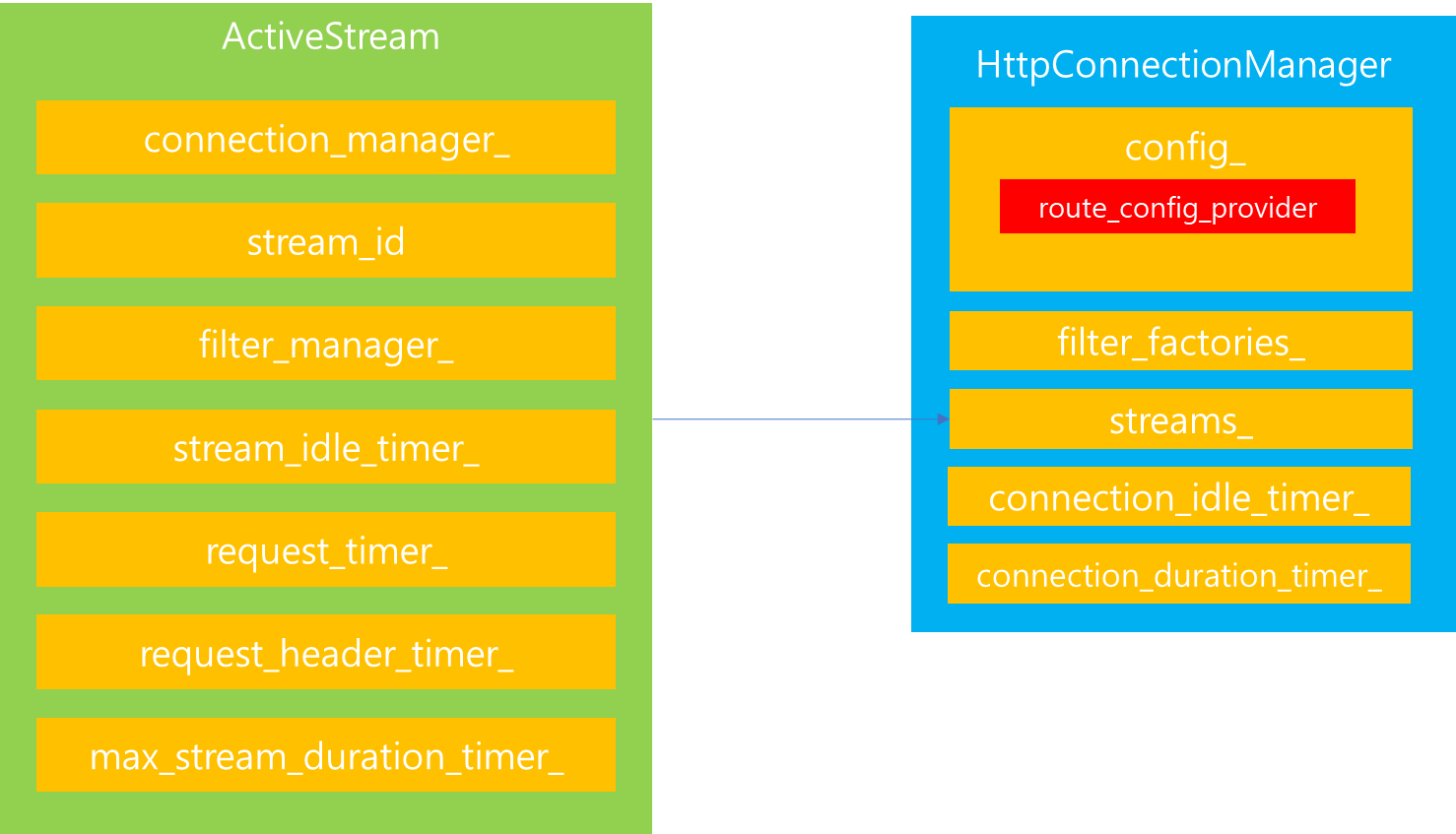
streams_ List는 ActiveStream을 포함하고 있는데, 해당 Stream 내부에는 Http 요청에 필요한 필수적인 항목들이 포함되어있습니다. 그렇다면 ActiveStream은 언제 생성될까요?

codec_impl.cc
Status ServerConnectionImpl::onMessageBeginBase() {
if (!resetStreamCalled()) {
ASSERT(active_request_ == nullptr);
active_request_ = std::make_unique<ActiveRequest>(*this, std::move(bytes_meter_before_stream_));
if (resetStreamCalled()) {
return codecClientError("cannot create new streams after calling reset");
}
active_request_->request_decoder_ = &callbacks_.newStream(active_request_->response_encoder_);
// Check for pipelined request flood as we prepare to accept a new request.
// Parse errors that happen prior to onMessageBegin result in stream termination, it is not
// possible to overflow output buffers with early parse errors.
RETURN_IF_ERROR(doFloodProtectionChecks());
}
return okStatus();
}
과정을 간략하게 살펴보면, 이전에 Parser에 대해서 살펴봤을 때, Client가 데이터 처리를 요청하면 이를 분석해서 특정 Event마다 통지한다고 설명했습니다. 이때 onMessageBegin 이벤트가 발생하면 ServerConnection 에서는 ActiveRequest를 먼저 생성하고 ActiveRequest 하위에 request_decoder_ 속성에 새로운 Stream을 만듭니다. 이때 만들어지는 Stream이 ActiveStream입니다.
이후 생성된 ActiveStream은 위 과정에서 표현되지는 않았지만 Parsing 과정이 진행되면서 지속적으로 참조되고 Parsing이 완료되는 시점에서 Stream 내부에 매핑된 정보에 의하여 Http 전송이 이루어지게됩니다.
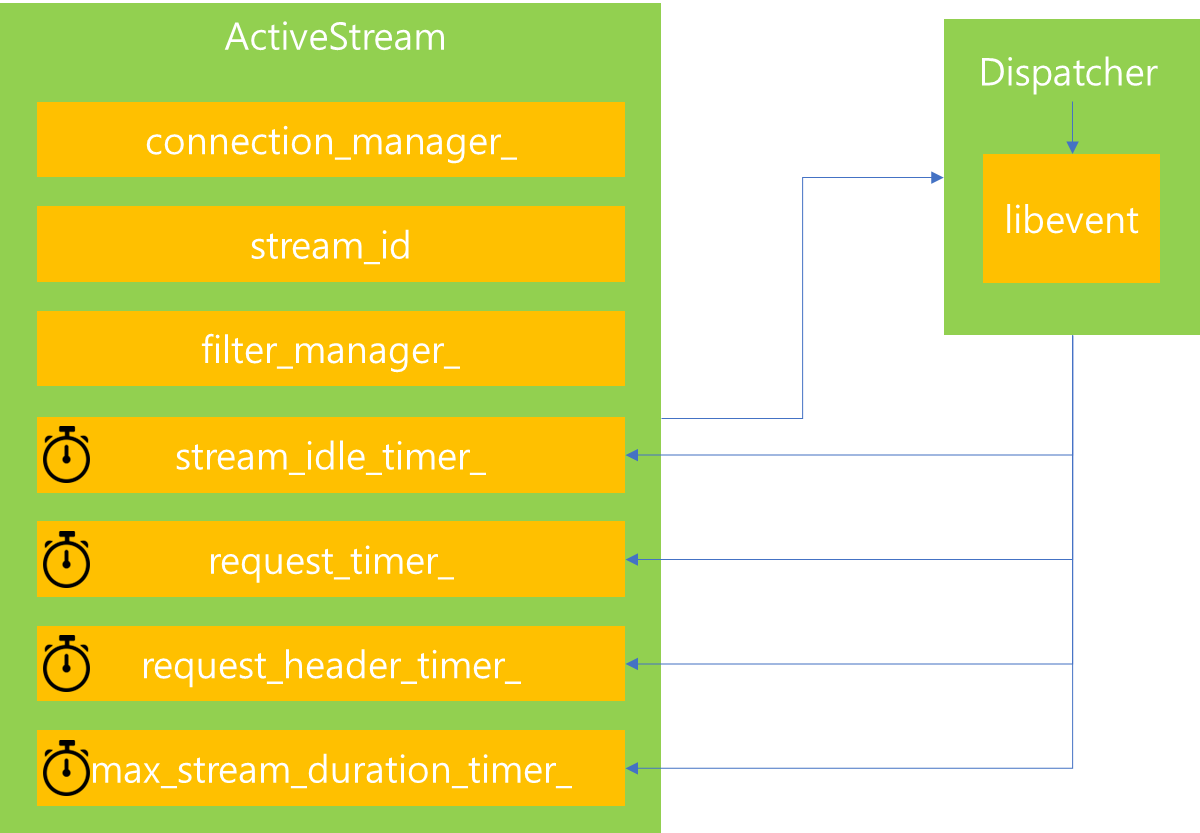
이번에는 ActiveStream의 속성에 대해서 살펴보겠습니다. stream_id는 Stream 마다 생성되는 id로써, ActiveStream이 생성하는 당시에 임의의 값으로 지정됩니다.
filter_manager_ 는 이전에 Http filter에 대해서 잠깐 살펴볼 때 등장한 프로퍼티명으로써, ActiveStream 내에 Http filter 생성 및 처리를 위임하는데 관여하는 프로퍼티입니다. 사용자 요청을 처리하는 과정에서 Http filter 처리가 필요한 순간에 해당 인스턴스가 사용됩니다.
그 다음 살펴볼 것은 timer입니다. ActiveStream 내부에는 다양한 Timer가 존재하는데, 해당 timer의 역할은 timer가 지정된 시간내에 요구하는 조건이 충족되지 않으면, 해당 연결을 해제하는 역할을 수행합니다. 이때 각각의 Timer는 Dispatcher 로부터 Timer를 생성받아 지정된 시간내에 조건이 충족되면 Timer를 Reset 하여 다시 지정된 시간만큼을 대기하며, 시간이 초괴되면 연결을 해제합니다. 개별 Timer의 역할을 살펴보면 다음과 같습니다.
| 타이머 | 기능 |
| stream_idle_timer_ | 해당 Stream이 연결되고 어떠한 활동도 일어나지 않았을 때, 지정된 idle 시간을 초과하면 Stream 해제 |
| request_timer_ | Stream이 생성되고 난 이후 Request를 시작하고 응답이 올 때까지 대기시간을 의미하며, 지정된 시간 초과하면 Stream 해제 |
| request_header_timer_ | Downstream에서 header를 전송하고 나서 이에 대한 응답이 올 때까지의 대기시간을 의미하며, 지정된 시간 초과하면 Stream 해제 |
| max_stream_duration_timer_ | Stream이 생성되고 종료될 때까지 지속할 수 있는 시간을 의미하며, 지정된 시간을 초과하면 Stream 해제 |
상기 Timer와 관련해서는 envoy 공식 문서에서 확인할 수 있으며, 적정한 값 설정을 통해서 Stream이 생성되고 무한정 대기하지 않도록 처리할 수 있습니다.
7. Timer
HttpConnectionManager에서 마지막으로 살펴볼 것은 내부 프로퍼티에 존재하는 Timer입니다. 방금전에 개별 Stream 내부에서 여러 Timer 들을 살펴봤었는데, HttpConnectionManager 또한 Timer를 보유하고 있습니다.
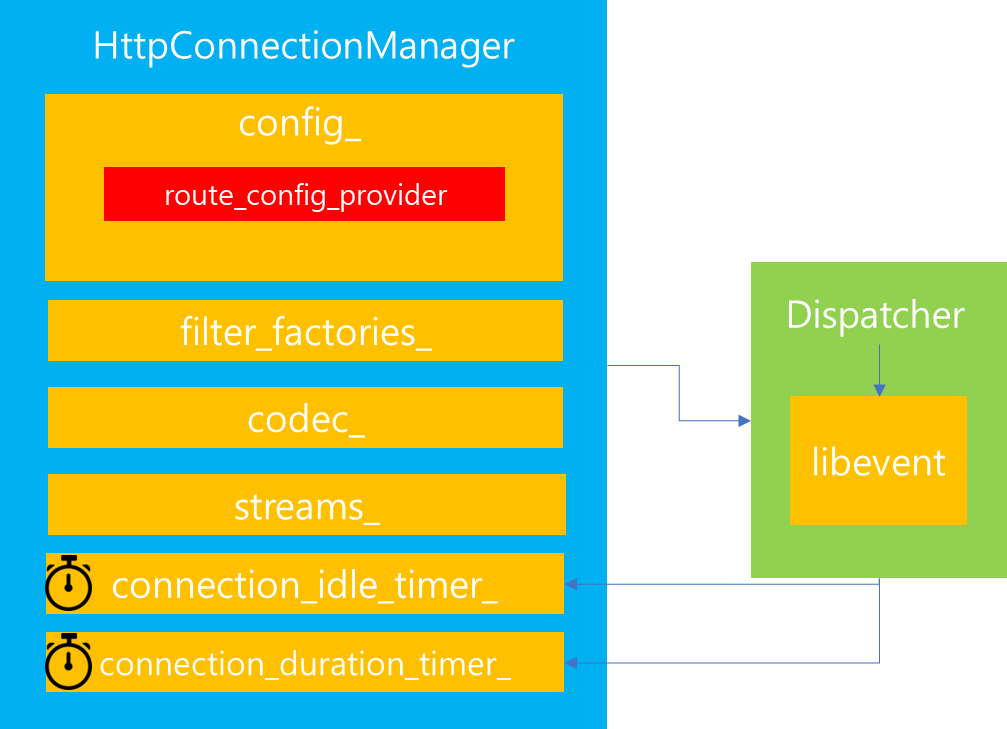
HttpConnectionManager가 보유한 주요 Timer는 위와같이 2개입니다. 이는 HttpConnectionManager가 생성하는 단계에서 Dispatcher에게 요청하여 Timer를 생성합니다.
connection_idle_timer_의 경우는 HttpConnectionManager가 생성된 이후 어떠한 Stream이 생성되지 않았을 때, idle 시간을 얼마나 부여할지를 측정하는 Timer입니다. 따라서 해당 시간 동안 Stream 연결이 이루어지지 않는다면, 연결을 해제합니다.
반면 connection_duration_timer_는 HttpConnectionManager가 생성되고 모든 처리가 완료될 때까지 즉 사용자의 연결 요청을 완수하는데 걸리는 데드라인을 측정하는 Timer입니다. 따라서 해당 시간 동안 모든 요청이 완료되지 않는다면, 연결을 해제합니다.
8. 마치며
이번 포스팅을 통해서 HttpConnectionManager가 보유하고 있는 속성에 대해서 알아봤습니다. 다만 이번 포스팅만으로는 HttpConnectionManager가 보유하고 있는 컴포넌트가 어떻게 상호작용하여 사용자의 요청을 처리하는지 완벽하게 이해하기는 힘듭니다. 이 부분은 이 다음 포스팅에서 진행되는 Envoy 프록시 연결 과정을 관찰하면서 조금 더 자세하게 살펴보겠습니다.
'MSA > Istio' 카테고리의 다른 글
| 7. [envoy-internals] Client 요청 전달 과정 이해하기 - 1 (1) | 2023.05.25 |
|---|---|
| 5. [envoy-internals] Listener Manager (0) | 2023.05.23 |
| 4. [envoy-internals] Cluster Manager - Load Balancer (0) | 2023.05.19 |
| 3. [envoy-internals] Cluster Manager - 역할 (1) | 2023.05.18 |
| 2. [envoy-internals] 쓰레딩 모델과 데이터 공유 (0) | 2023.05.17 |