1. 서론
Query App 관련 포스팅을 진행하기 앞서 Event가 저장되는 EventStore에 대하여 알아보고자 합니다. 이번 포스팅에서 다룰 내용은 EventStore를 위한 필요조건, DB 종류에 따른 EventStore 역할 장·단점 그리고 AxonServer EventStore 저장 구조입니다.
2. EventStore 필요 조건
Event를 읽고 쓰는데 있어 EventStore가 기본적으로 갖춰야할 조건을 알아보겠습니다.
1. 이벤트는 추가만 가능하고 입력,삭제,수정이 불가능하다.
2. 여러 이벤트가 하나의 트랜잭션 처리가 되어야 한다면, 트랜잭션 단위로 Commit 혹은 Rollback 되어야한다.
3. Commit된 이벤트는 유실되어서는 안된다
4. 발행된 모든 Event 중 Aggregate 별로 데이터를 읽을 수 있어야한다.
5. 모든 이벤트는 삽입된 순서대로 읽기가 가능해야한다.
위 조건은 대부분의 DBMS라면 충족되는 요건입니다. 그 밖에 EventStore를 구성하는데 있어 요구되는 사항은 무엇이 있을까요?
1. SnapShot 저장소 지원

Command App을 구현하면서 Snapshot 필요성을 인지하였습니다. EventStore에서는 특정 시점에 Aggregate별 Sequence 번호에 해당하는 Snapshot을 별도 공간에 적재하며, Event 로드시에 해당 스냅샷 상태와 스냅샷 이후의 Sequence 번호에 해당되는 Event만을 읽을 수 있도록 지원해야 합니다.
2. Event Notification 기능
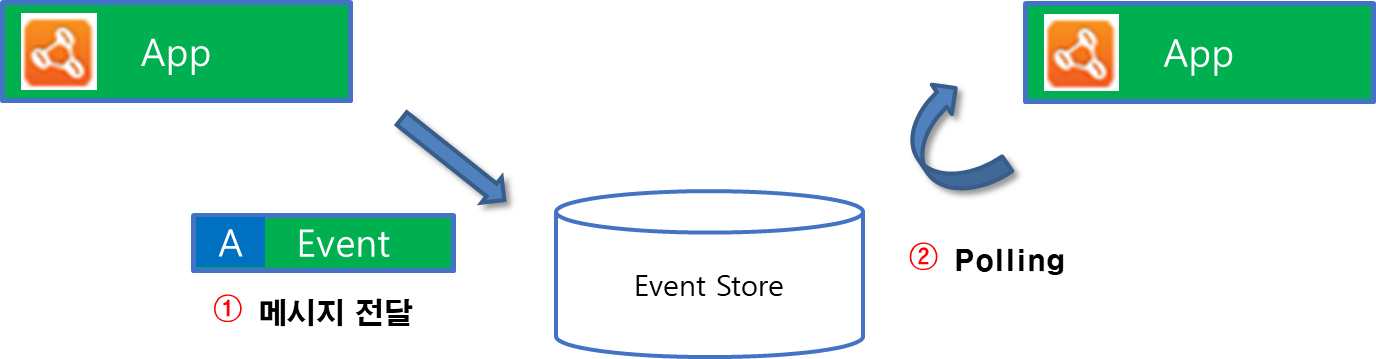
EvenetStore가 신규 추가된 Event를 희망하는 App에게 전파하는 역할을 수행하지 못한다면, Subscriber에서 주기적으로 Polling하여 Event 유입이 있는지 확인하는 작업이 필요합니다. 이는 DB 관점에서 I/O 및 Network 트래픽이 증가하는 요인입니다. 일반적인 RDBMS에서는 이벤트 전파기능이 없기 때문에 위 그림과 같이 메시징 처리를 수행해야합니다.

이러한 문제점을 해결하고자 메시지 큐를 사용해서 EventStore에 적재함과 동시에 큐에도 이벤트를 적재하여 전송하는 방법을 생각할 수 있습니다. 하지만 이는 EventStore에 저장과 큐를 통한 Event 전송 시점에 대한 동기화를 보장할 수 없습니다.
또한, 기타 이유로 EventStore에 이벤트 삽입이 실패하는 경우 메시지 큐를 통해 이미 전달된 이벤트와의 일관성이 깨지게 됩니다.
따라서 EventStore의 가장 이상적인 구조는 EventStore 자체가 Message Bus 역할을 담당하는 것입니다.
3. EventStore 적합성 비교
지금부터 소개드리는 내용은 AxonIQ Webinar를 참고하여 작성하였습니다.
1. RDBMS
RDBMS 사용의 장점으로는 Transaction에 대한 지원 및 기술적 성숙도가 높다는 점입니다. 또한 오랜시간동안 사용되었으므로 사용자들에게 친숙하며, 제공되는 Tool이 다양합니다.
하지만 가장 큰 문제점은 확장성입니다. 대량의 데이터 처리보다는 데이터 공간 효율화 및 관계를 통한 데이터 정합성 보장 등에 초점이 맞춰져 있습니다. AxonIQ에서 RDBMS를 EventStore로 사용했을 때의 벤치마크 테스트 결과는 다음과 같습니다.

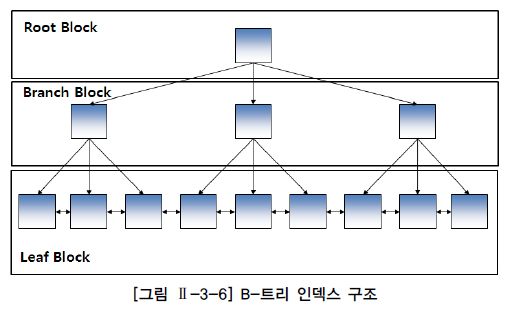
결과를 보면 데이터 양이 증가할 수록 처리량이 떨어지는 것을 확인할 수 있습니다. 다양한 요인이 있을 수 있겠지만, 대표적으로는 대용량 데이터를 기준으로 B-Tree 인덱스를 사용하면, 인덱스 Depth가 깊어지기 때문에 지속 발생하는 인덱스 Split과 더불어 수직적 탐색 비용이 증가합니다. 또한 데이터 특성상 인덱스 우측 Block에 Transaction이 집중적으로 몰리기 때문에 Oracle 기준 핫블록으로 인한 Latch 경합이 발생하여 동시성이 크게 저하될 수 있습니다.(Right Growing Index)
위 테스트 결과는 RDBMS 테이블 구조 변경 없이 일반적인 Heap 테이블과 B-Tree 인덱스를 기준으로 진행했습니다. 만약 DBMS가 Oracle이라면 Hash 파티셔닝, Reverse 인덱스, IOT(Index Organized Table) 등을 적절히 사용한다면 개선의 여지는 있습니다.
RDBMS는 Event Notification 기능이 없기 때문에 이를 고려해야합니다. 이전에 설명한 Polling 방식을 개선하기 위해서는 테이블 단위 Audit을 고려해볼 수 있습니다. 즉 Audit 결과를 File로 떨어트리고 해당 로그 tail 값을 AxonFramework에서 요구하는 포맷으로 변경한 다음 메시지 큐를 통해 보내는 방법이 있습니다. 혹은 Trigger를 이용하는 방법도 생각해볼 수 있으나 이는 추천하지 않습니다.
2. Mongo DB

Mongo DB는 대표적인 NoSQL로써 하나의 이벤트는 하나의 Document에 속하며, 대량의 데이터 처리에 적합합니다. 하지만 Transaction 지원 문제점이 있습니다. 최근에 4.2 버전이 Release되어 Multi Document에 대한 Transaction 기능이 추가되었지만, 단일 Node에서는 Transaction이 불가하는 등의 제약사항이 존재합니다.
참고자료
두 번째 문제점은 MongoDB 3.2 버전부터 Storage Engine으로 Wiredtiger를 기본적으로 사용하고 있습니다. Wiredtiger 저장 방식은 Btree, 컬럼스토어, LSM 방식이 있습니다. 이중 EventStore에 적합한 방식은 Write 작업에 최적화된 LSM 방식이나 MongoDB에는 LSM을 아직 지원하고 있지 않습니다.
세 번째 문제점은 RDBMS와 마찬가지로 Event Notification 기능이 없기 때문에, Commit 로그 결과 등을 AxonFramework에서 요구하는 포맷으로 변경한 다음 메시지 큐를 통해 보내는 방식을 고려해야 합니다.
마지막으로 모든 Document에 대하여 전역적인 Sequence 기능이 기본적으로 제공되지 않는다는 점입니다. 따라서 이를 해결하기 위해서는 직접 함수를 구현해야 합니다.
참고자료
3. Kafka

카프카는 대용량 환경에서 Message 전달 역할로 좋은선택입니다. 하지만 EventSourcing에 있어서 좋은 도구는 아닙니다. 그 이유는 위 그림과 같이 Event Stream에서 특정 Aggregate를 추출하기 위해서는 해당 Stream 전체를 읽으면서 그 중 내가 원하는 Aggregate만 필터링하는 작업이 수반되어야 하기 때문입니다.
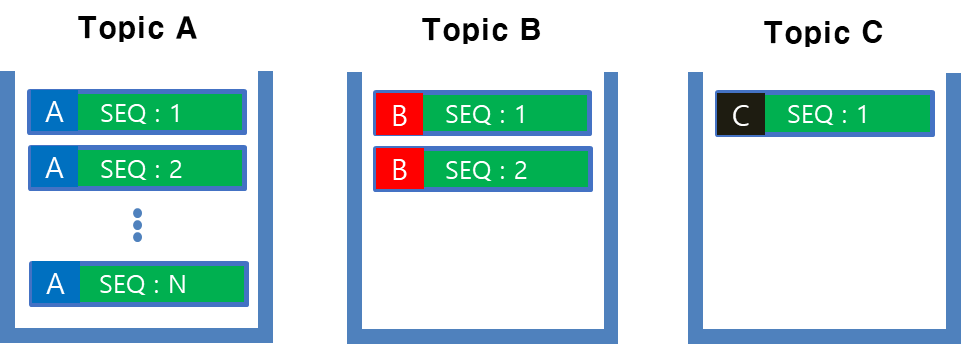
물론 Aggregate 별로 Topic을 생성하는 방법등도 고려할 수 있으나 이는 Aggregate 별로 디스크에 적재되는 용량과 I/O 밸런스 등을 고려해야하는 등의 관리 포인트가 급격하게 상승합니다.
참고자료
4. Axon Server(Event Store)
AxonServer 내부에는 Event 저장을위한 별도 DB가 없으며, File을 직접 다룹니다. 외부와의 연결은 Rest API 혹은 gRPC 방법을 통해 가능합니다.
EventStore는 오직 데이터 추가만이 가능하도록 설계되었습니다. 따라서 수정, 삭제와 관련된 그 어떠한 API도 제공되지 않습니다.

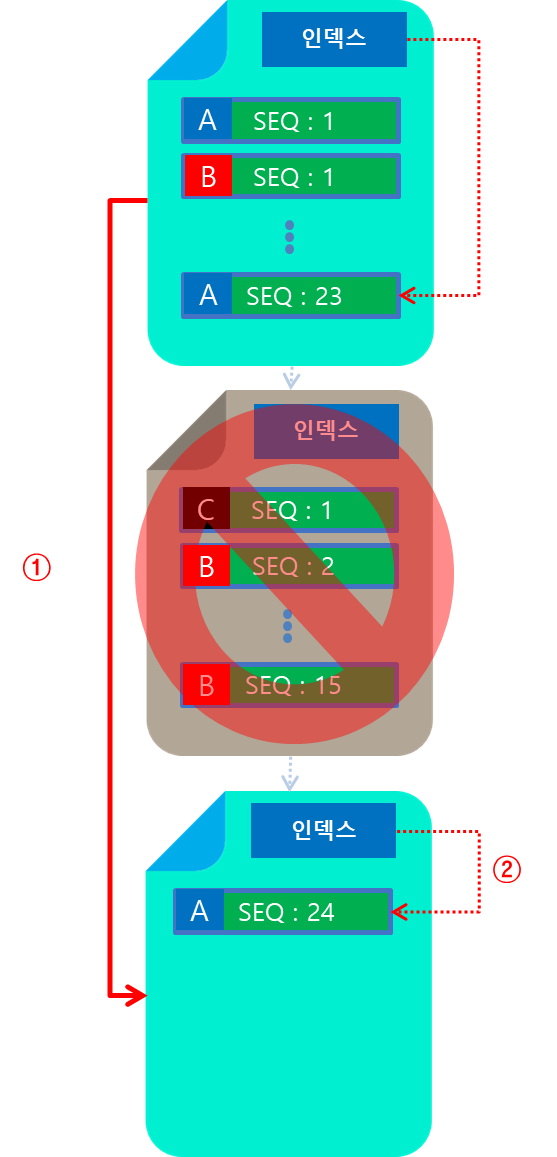
AxonServer에서는 EventStream을 일정 크기별로 잘라서 Segment로 매핑합니다. 각 Segment는 하나의 파일이며, 내부에는 Event가 연속적으로 할당되어 있습니다. 생성된 파일은 데이터 Corruption 확인을 위해 CRC 체크하여 파일 손상을 확인합니다.
만약 Segment에 Event Entry가 가득차게되면, 새로운 파일을 생성하고 이를 가르키도록 Index 정보를 추가합니다.

EventStore는 Snapshot 저장소를 제공합니다. Snapshot 저장소 또한 Segment 단위로 저장되며, Snapshot Entry는 동일한 Aggregate의 번호가 매핑된 파일을 가르킵니다. 따라서 위 그림에서 A Aggregate를 읽는다고 가정한다면 Snapshot이 가르키는 1번 Segment 이후부터 데이터를 읽기 시작합니다.
하지만 이때 2번 Segment에는 A Aggregate Event가 존재하지 않습니다. 따라서 해당 Segment는 읽는 것이 의미가 없습니다. 따라서 스캔 과정에서 2번은 읽지 않고 Skip할 수 있다면 최소한의 I/O로 성능을 높일 수 있을 것입니다. AxonServer에서는 이를 위해 Bloom Filter를 도입하였습니다.
Bloom Filter
Bloom Filter는 찾고자 하는 데이터가 해당 집합에 포함되는지를 판단하는 확률적 자료구조입니다. 주로 DBMS에서 많이 사용하며, 디스크에서 찾고자하는 값이 존재할 가능성이 있는 경우에만 블록을 읽기 위해 사용됩니다.
예를 들어 설명하겠습니다. Bloom Filter는 N개의 bit 배열에 대해서 찾고자하는 데이터를 대상으로 H개의 해시 함수를 적용한 결과를 1로 표시한다음, 대상 집합에도 동일하게 H개의 해시 함수를 적용해 결과가 동일한지를 판단합니다. 만약 동일하다면 찾고자 하는 존재할 수도 있으므로 해당 집합을 탐색합니다.

예를들어 1개의 Segment에는 1개의 Event만 존재하고, 4개 bit 배열 및 1개의 해 시함수(mod 10)을 적용한다고 가정하겠습니다. 이때 찾고자하는 Aggregate 식별자는 14라면 위 해시 함수를 적용했을 때 결과는 4가 나옵니다. 또한 저장된 값 또한 14라면 Bloom Filter 및 찾고자 하는 값이 동일하므로 해당 집합에는 원하는 결과가 존재합니다.

하지만 만약 집합속에 있는 값이 24라면, 해시 함수 결과 똑같이 4라는 결과가 나옵니다. 이때는 값이 다른데도 불구하고, 값이 있을 수도 있다고 판정하여 해당 집합을 읽습니다. 따라서 이러한 경우는 비효율적인 I/O가 존재하며 이를 false positive라고 합니다. 따라서 Bloom Filter에서는 false positive를 줄이기 위해서 bit 배열의 수를 늘리는 것과 해시 함수 개수를 늘려서 동일한 값이 발생하지 않도록해야 불필요한 I/O를 유발하지 않습니다.
참고자료
Bloom Filter를 통해서 읽어야할 Segment를 알았다면, 해당 Segment에서 시작점을 찾는 것은 Segment 내부에 저장되어있는 인덱스를 통해서 Aggregate의 Sequence 번호를 찾아갑니다. 결론적으로 Axon Server의 EventStore에서 Aggregate 데이터를 검색할 때, 해당 Aggregate의 식별자와 Sequence 번호를 기준으로 Bloom Filter와 인덱스를 활용하여 이를 찾습니다.
5. 마치며
이번 시간에는 EventStore 역할 비교 및 Axon Server 저장소 구조에 대해서 알아보았습니다. 다음 포스팅부터 Query Application 구현에 대하여 다루도록 하겠습니다.
'MSA > AxonFramework' 카테고리의 다른 글
| 12. Query 어플리케이션 구현(Event) - 2 (1) | 2020.01.07 |
|---|---|
| 11. Query 어플리케이션 구현(Event) - 1 (0) | 2020.01.06 |
| 9. Command 어플리케이션 구현 - 4 (0) | 2019.12.31 |
| 8. Command 어플리케이션 구현 - 3 (0) | 2019.12.29 |
| 7. Command 어플리케이션 구현 - 2 (2) | 2019.12.28 |