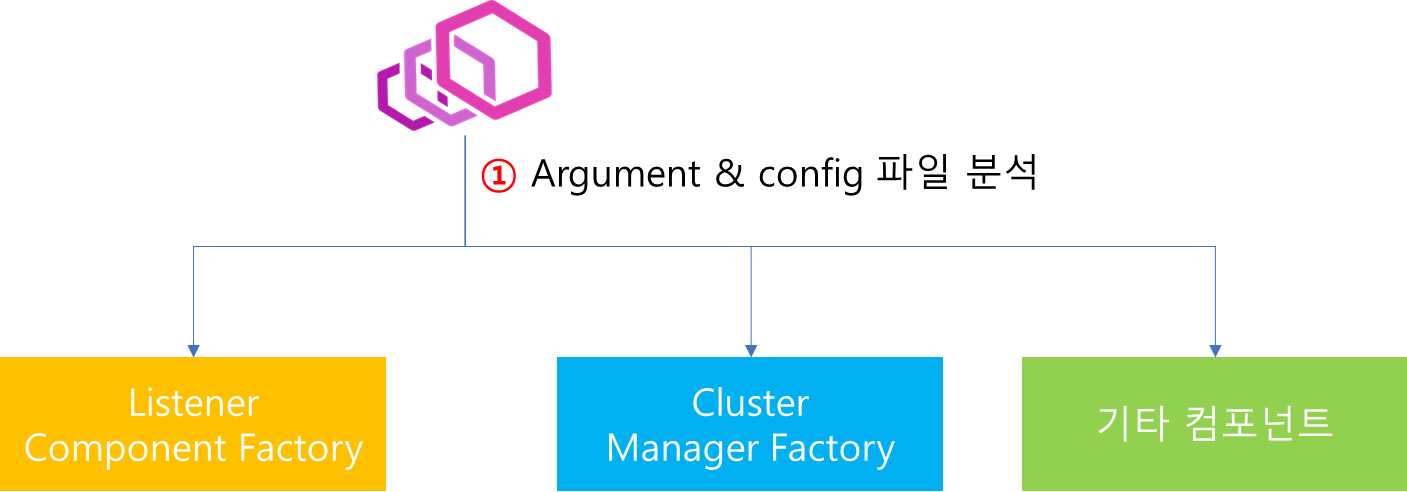
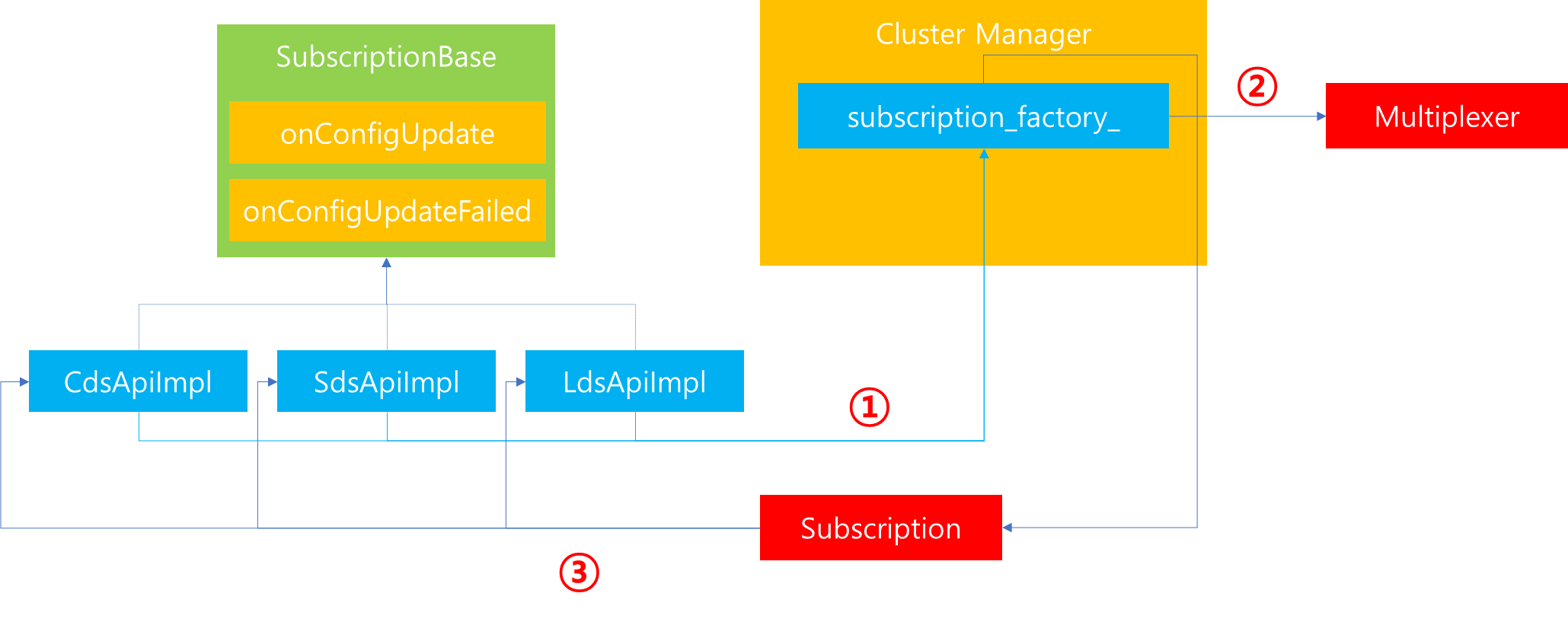
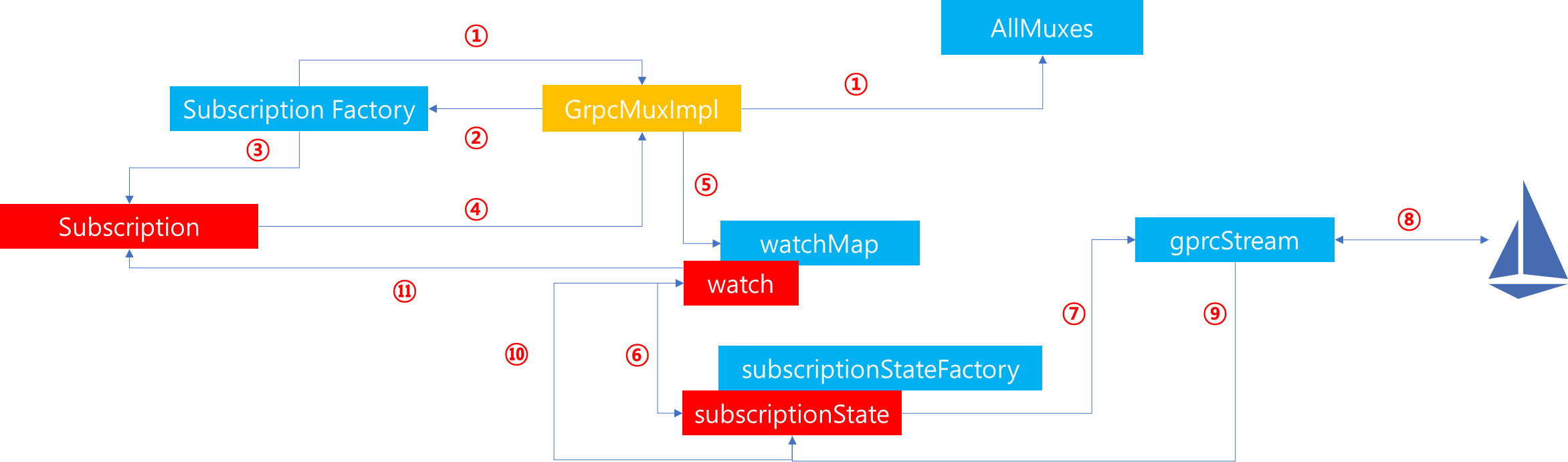
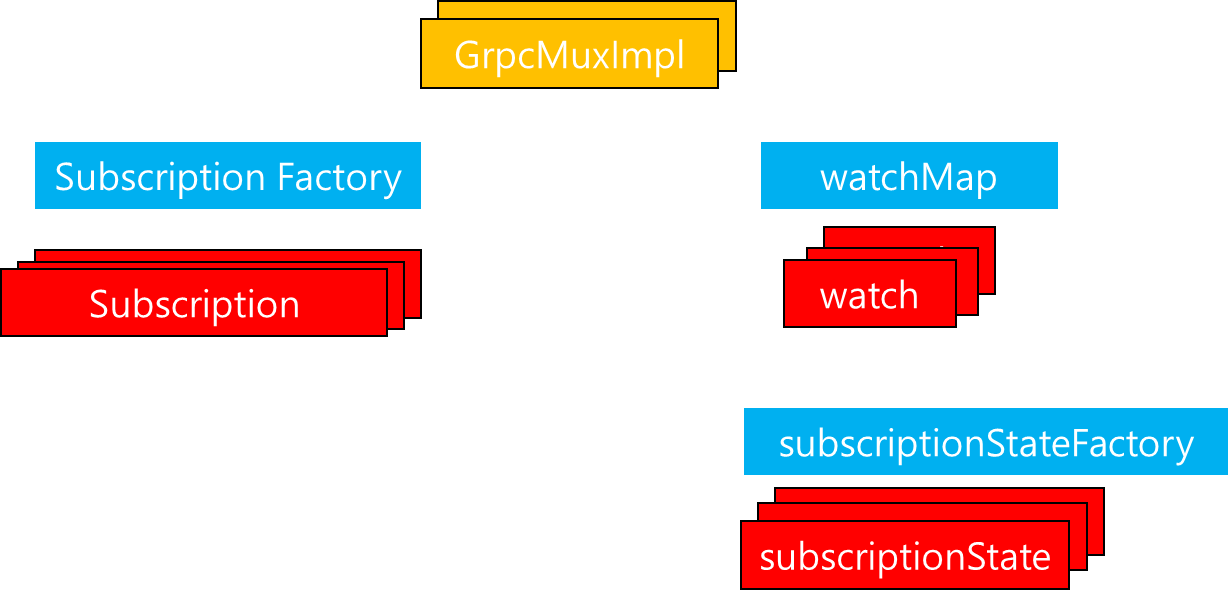
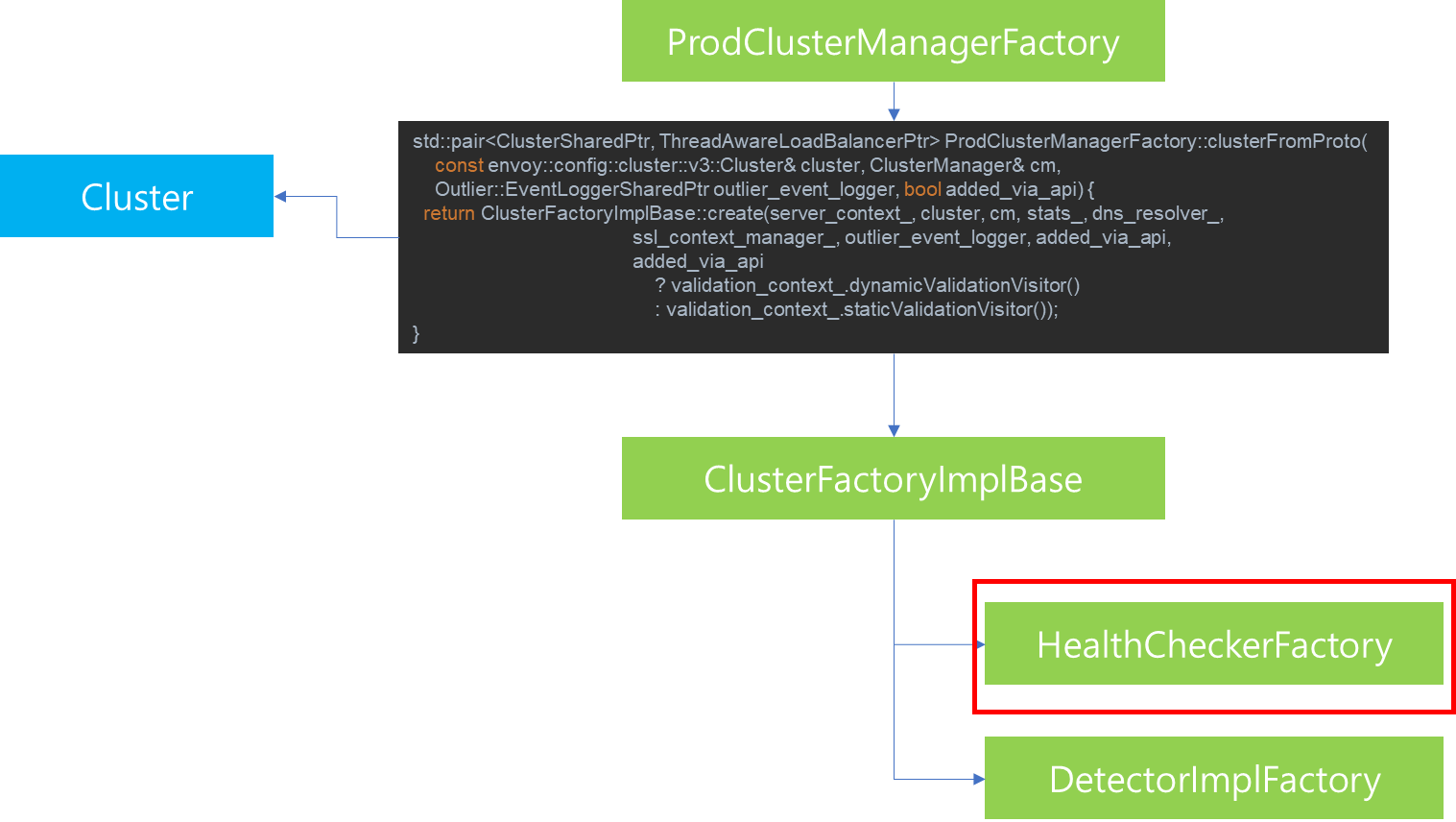
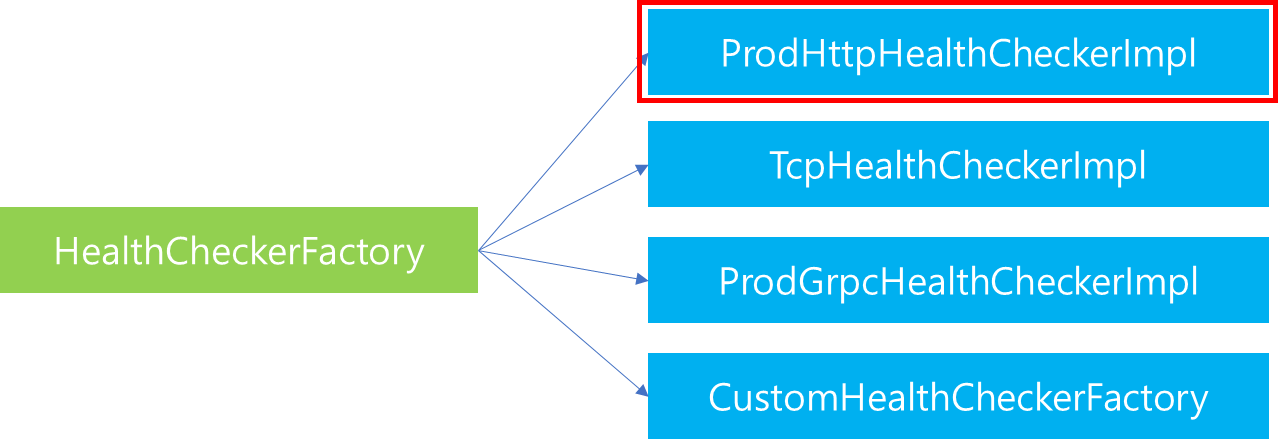
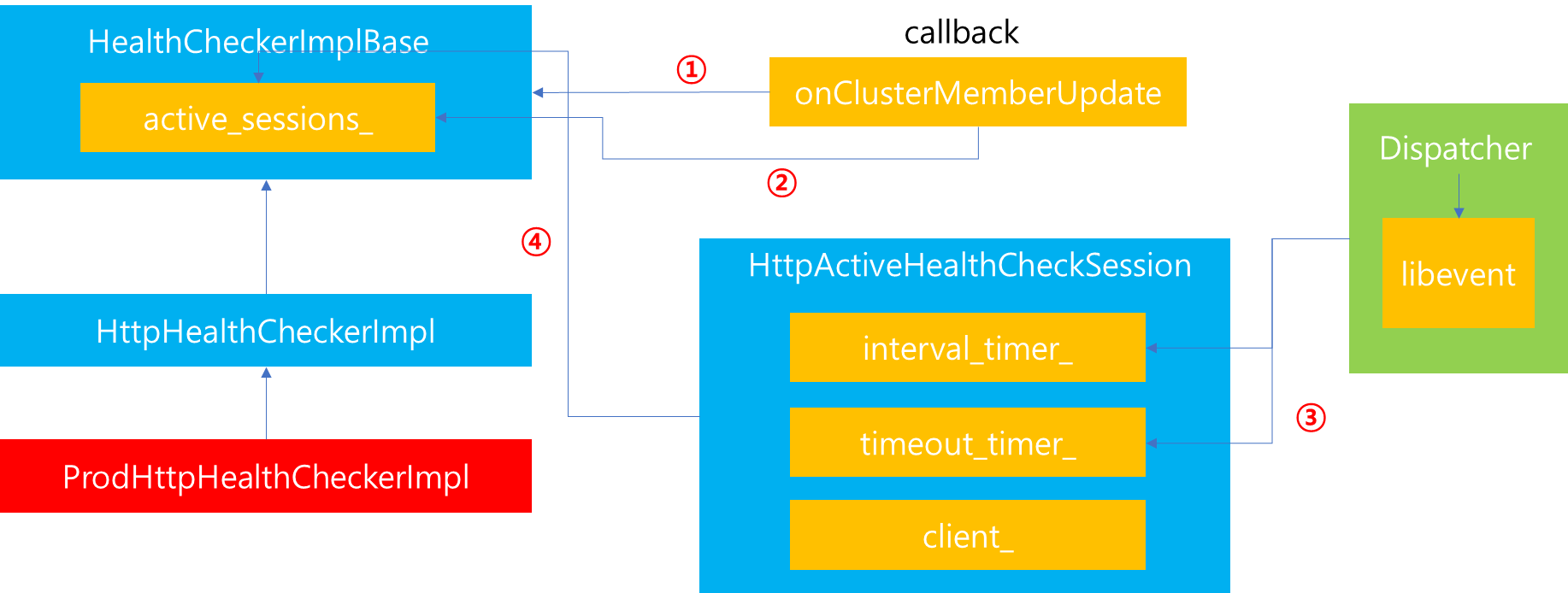
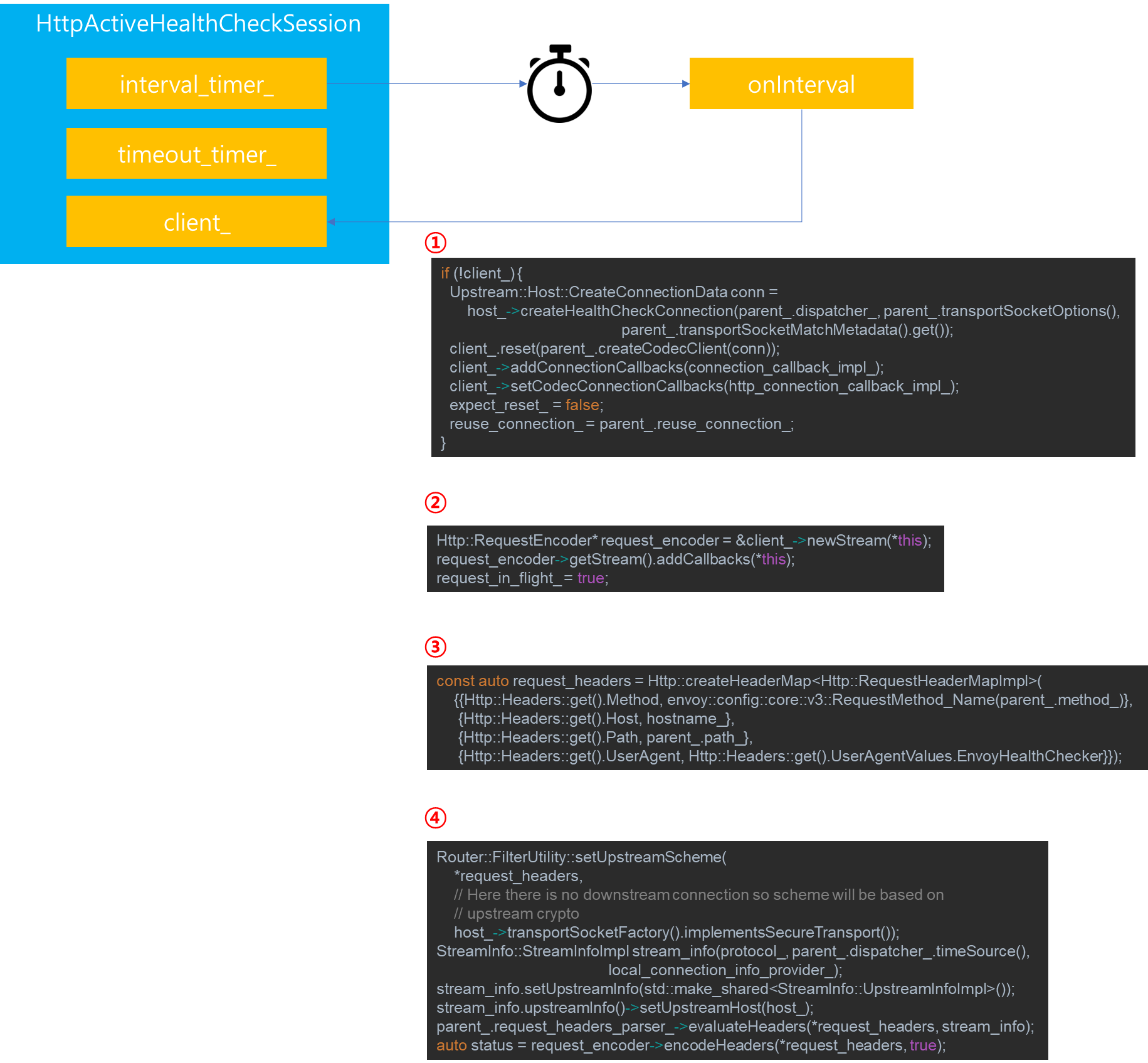
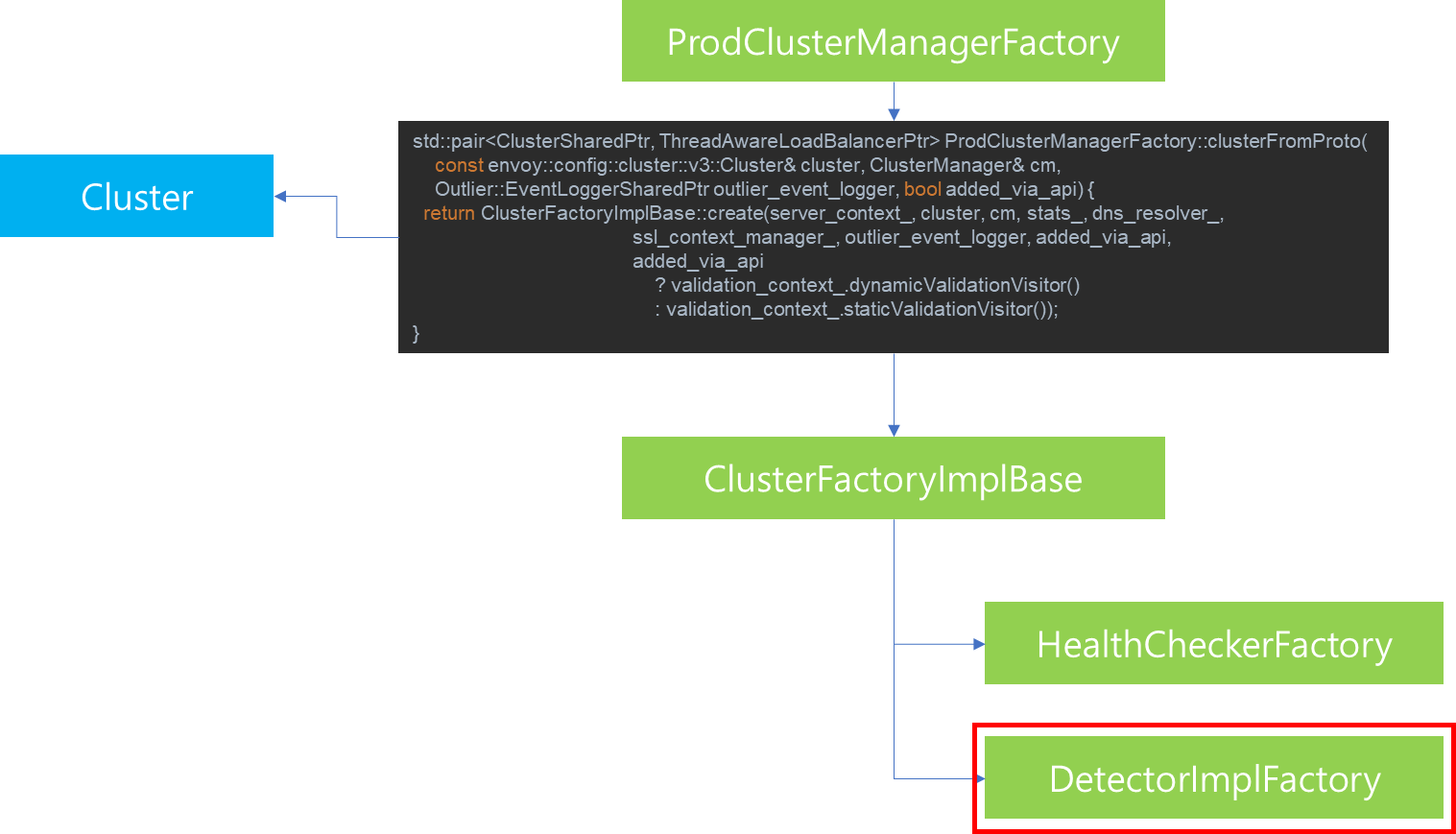
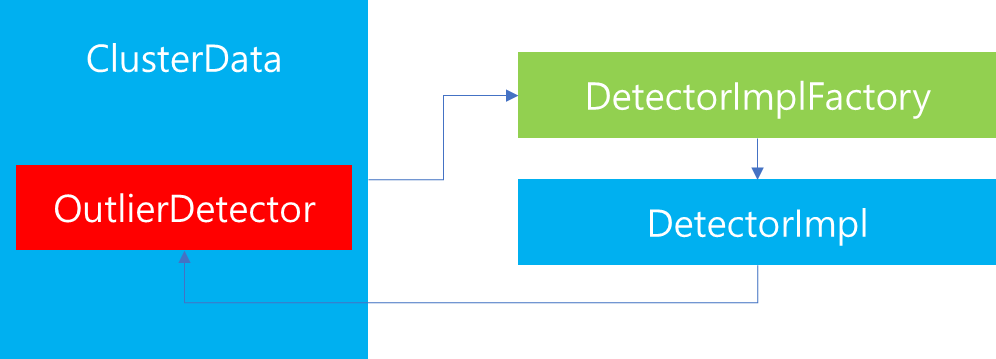
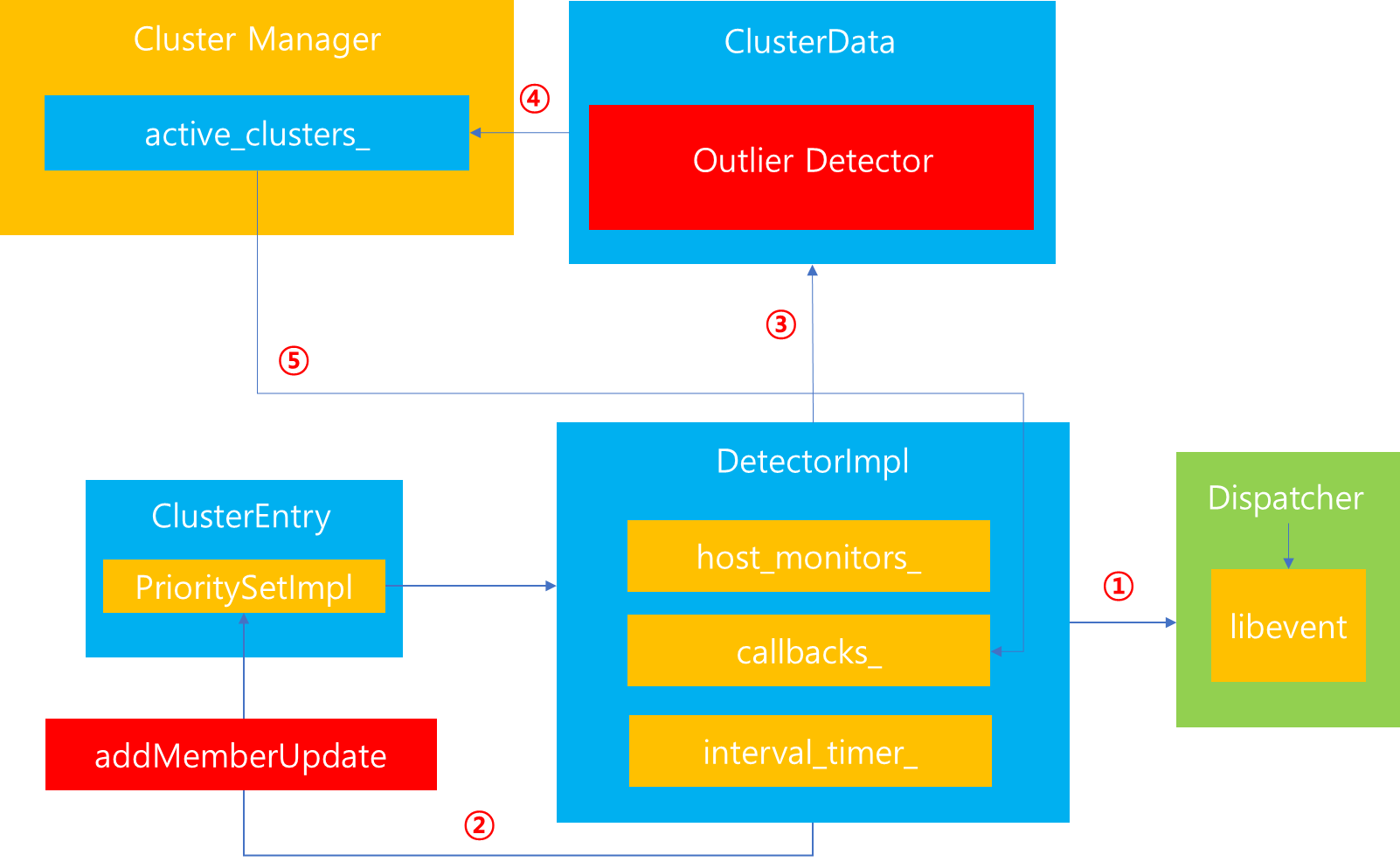
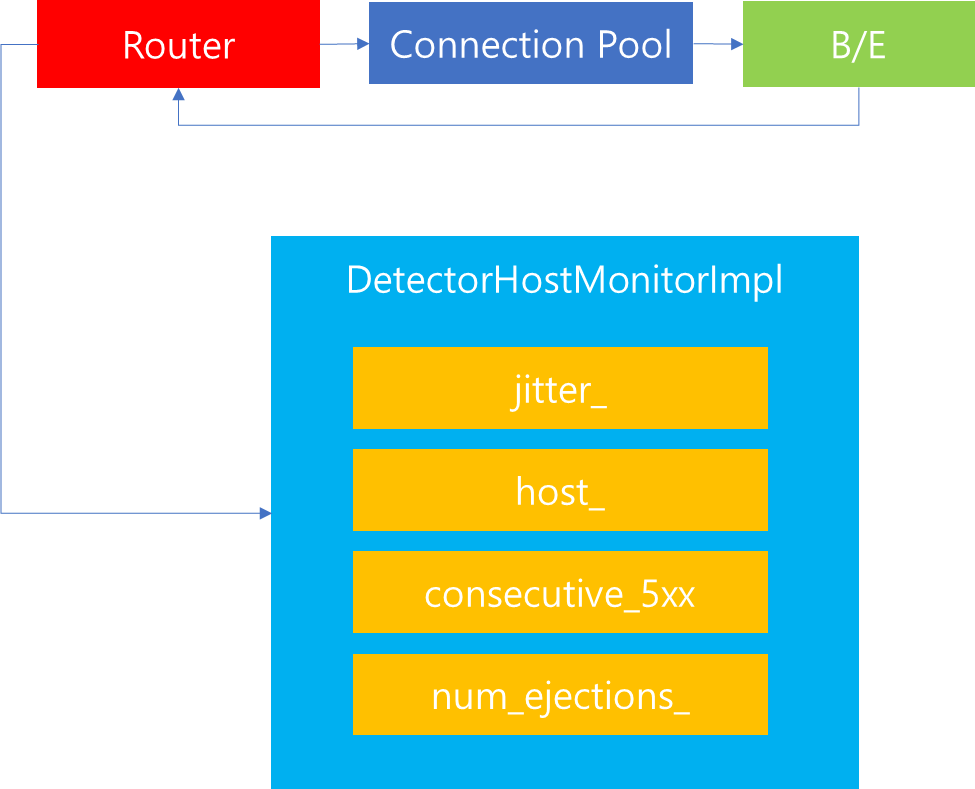
1. 서론
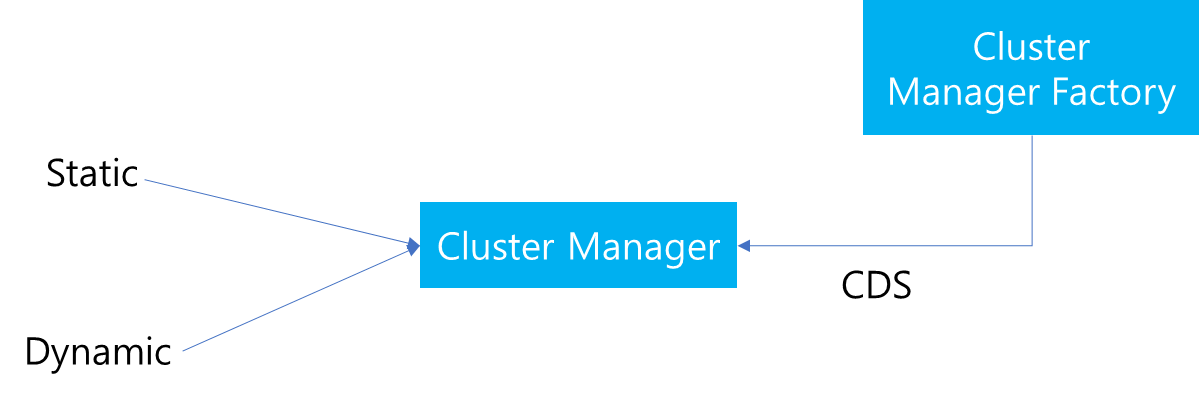
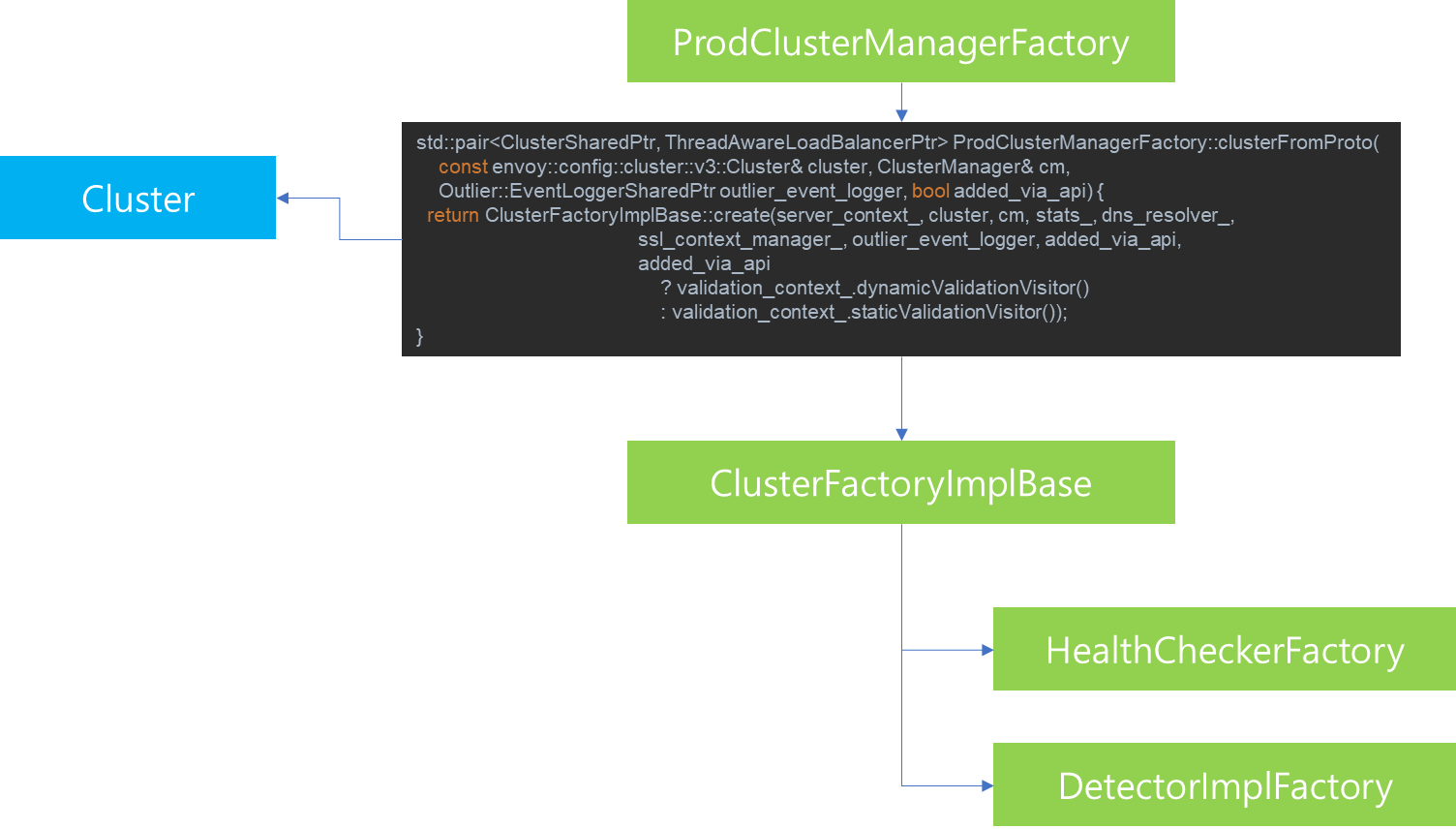
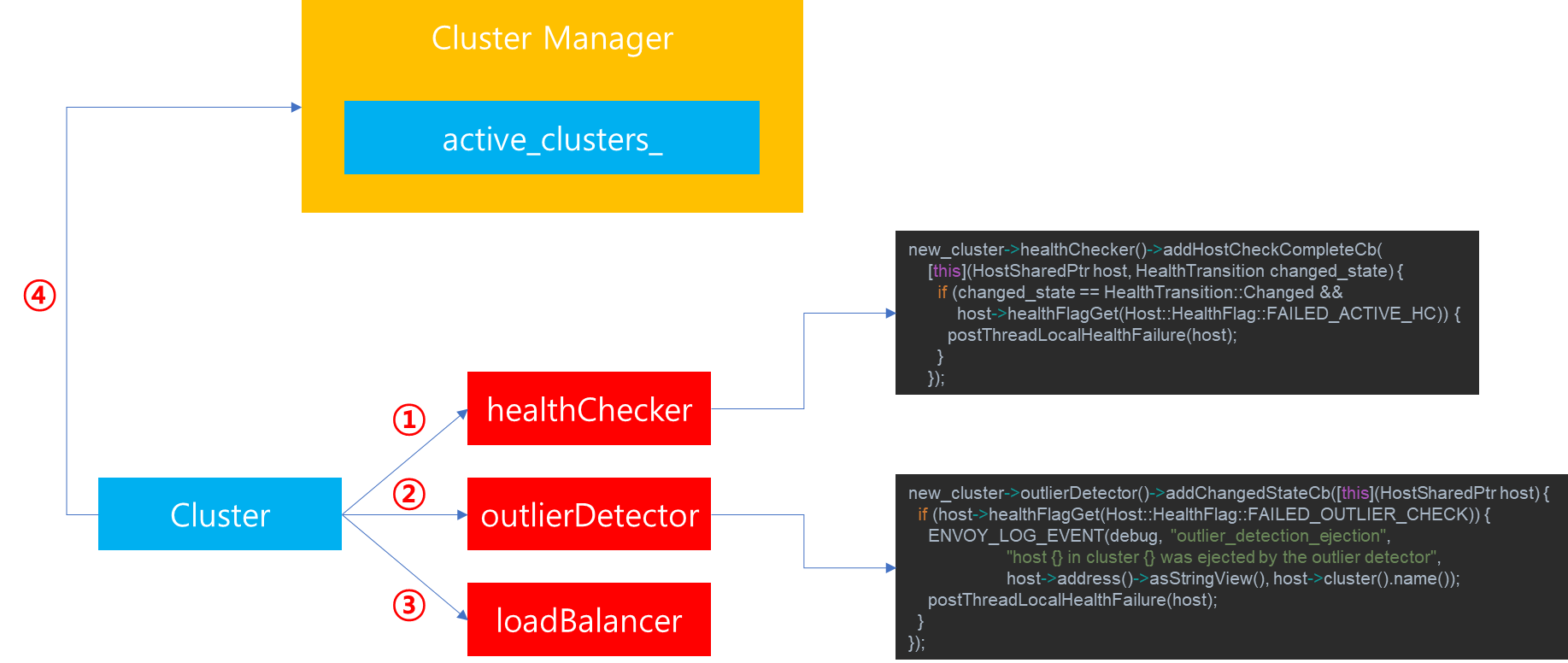
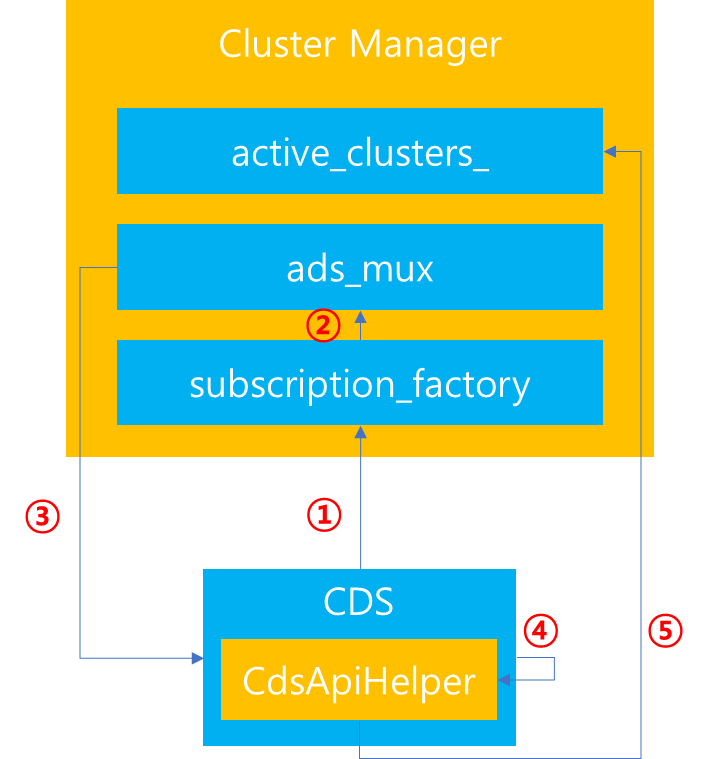
이전 포스팅을 통해서 Envoy Cluster Manager의 역할에 대해서 살펴봤습니다. Cluster Manager는 Cluster 관리 뿐만 아니라 Multiplexer 및 Subscription 생성에 관여합니다. 이번 포스팅에서는 Cluster Manager에서 관리하는 Cluster 내부에서 지정할 수 있는 Load Balancer 종류와 설정 방법에 대해서 다루고자합니다. 이번 포스팅 내용은 Envoy에 대한 설명 뿐만 아니라 Load Balancer 종류에 대한 알고리즘에 대한 개념 설명 위주로 알아보면서 어떻게 envoy가 Load Balancing을 처리하는지에 대해서 살펴보고자 합니다.
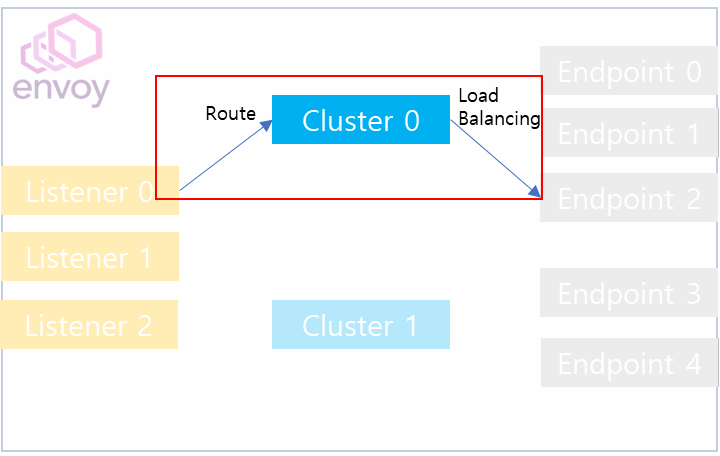
2. Envoy Loadbalancer

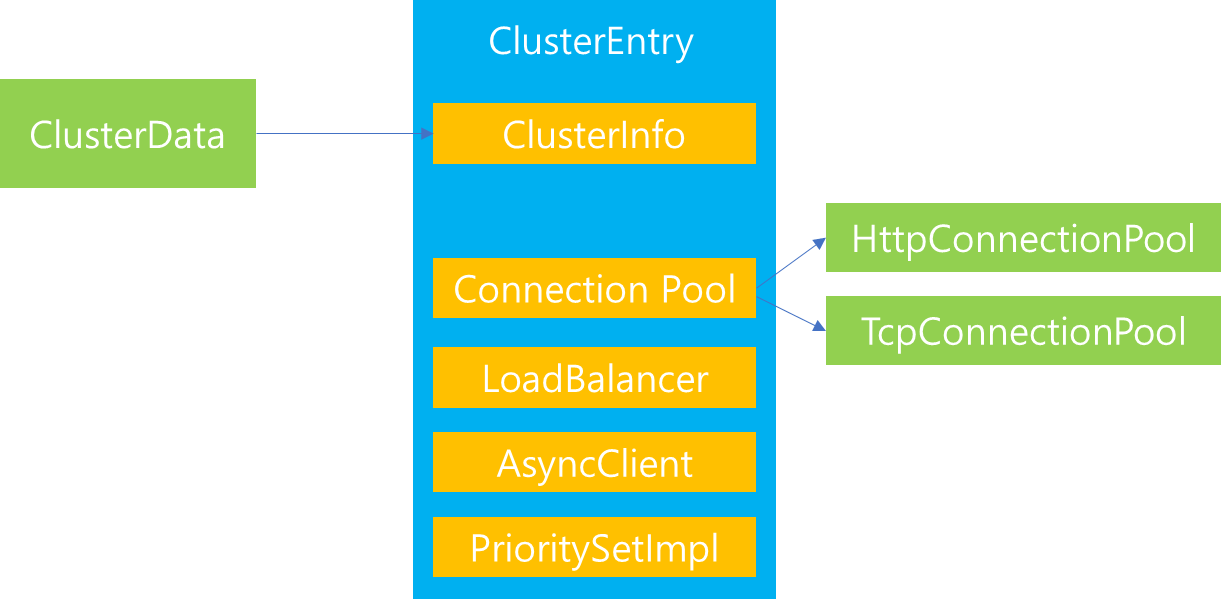
cluster_manager_impl.cc
ClusterManagerImpl::ThreadLocalClusterManagerImpl::ClusterEntry::ClusterEntry(
ThreadLocalClusterManagerImpl& parent, ClusterInfoConstSharedPtr cluster,
const LoadBalancerFactorySharedPtr& lb_factory)
: parent_(parent), lb_factory_(lb_factory), cluster_info_(cluster) {
priority_set_.getOrCreateHostSet(0);
// TODO(mattklein123): Consider converting other LBs over to thread local. All of them could
// benefit given the healthy panic, locality, and priority calculations that take place.
if (cluster->lbSubsetInfo().isEnabled()) {
lb_ = std::make_unique<SubsetLoadBalancer>(
cluster->lbType(), priority_set_, parent_.local_priority_set_, cluster->stats(),
cluster->statsScope(), parent.parent_.runtime_, parent.parent_.random_,
cluster->lbSubsetInfo(), cluster->lbRingHashConfig(), cluster->lbMaglevConfig(),
cluster->lbRoundRobinConfig(), cluster->lbLeastRequestConfig(), cluster->lbConfig(),
parent_.thread_local_dispatcher_.timeSource());
} else {
switch (cluster->lbType()) {
case LoadBalancerType::LeastRequest: {
ASSERT(lb_factory_ == nullptr);
lb_ = std::make_unique<LeastRequestLoadBalancer>(
priority_set_, parent_.local_priority_set_, cluster->stats(), parent.parent_.runtime_,
parent.parent_.random_, cluster->lbConfig(), cluster->lbLeastRequestConfig(),
parent.thread_local_dispatcher_.timeSource());
break;
}
case LoadBalancerType::Random: {
ASSERT(lb_factory_ == nullptr);
lb_ = std::make_unique<RandomLoadBalancer>(priority_set_, parent_.local_priority_set_,
cluster->stats(), parent.parent_.runtime_,
parent.parent_.random_, cluster->lbConfig());
break;
}
case LoadBalancerType::RoundRobin: {
ASSERT(lb_factory_ == nullptr);
lb_ = std::make_unique<RoundRobinLoadBalancer>(
priority_set_, parent_.local_priority_set_, cluster->stats(), parent.parent_.runtime_,
parent.parent_.random_, cluster->lbConfig(), cluster->lbRoundRobinConfig(),
parent.thread_local_dispatcher_.timeSource());
break;
}
case LoadBalancerType::ClusterProvided:
case LoadBalancerType::LoadBalancingPolicyConfig:
case LoadBalancerType::RingHash:
case LoadBalancerType::Maglev:
case LoadBalancerType::OriginalDst: {
ASSERT(lb_factory_ != nullptr);
lb_ = lb_factory_->create();
break;
}
}
}
}
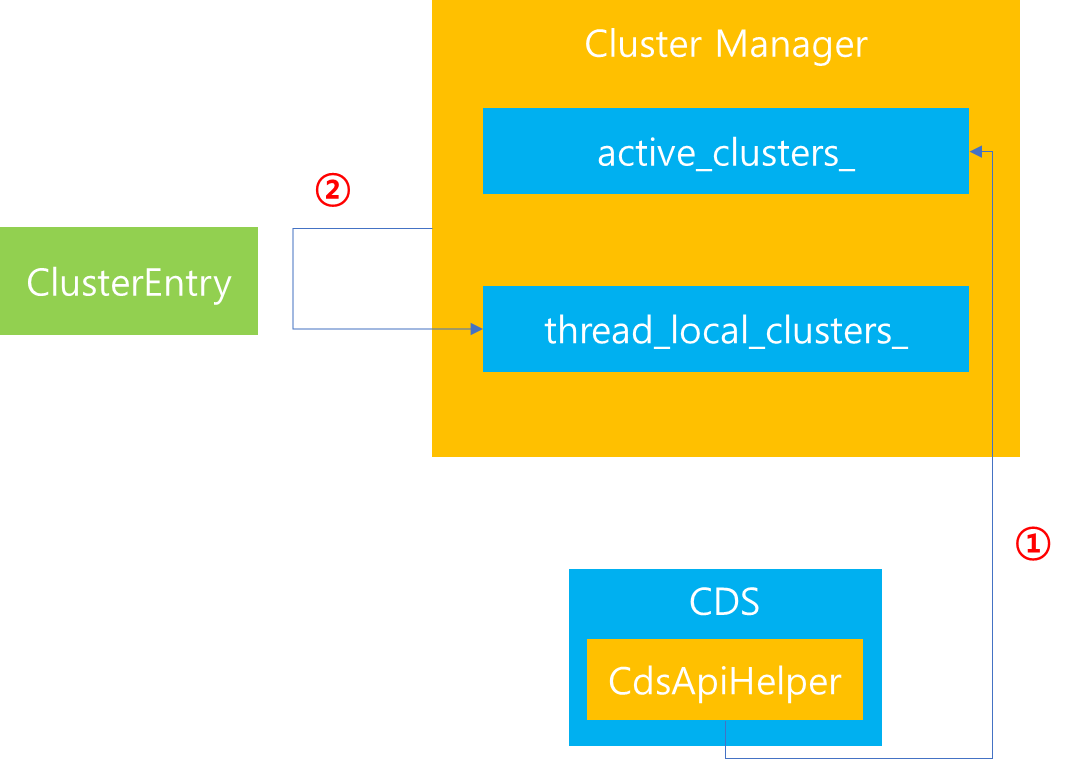
Envoy에서 Load Balancer는 ClusterEntry 내부에 존재하는 프로퍼티로써, ClusterEntry 생성 당시에 같이 생성됩니다. 이는 위 코드에서도 확인할 수 있으며, 생성자 내부에서 지정된 LoadBalancerType에 따라서 각기 다른 LoadBalancer가 지정됨을 확인할 수 있습니다.
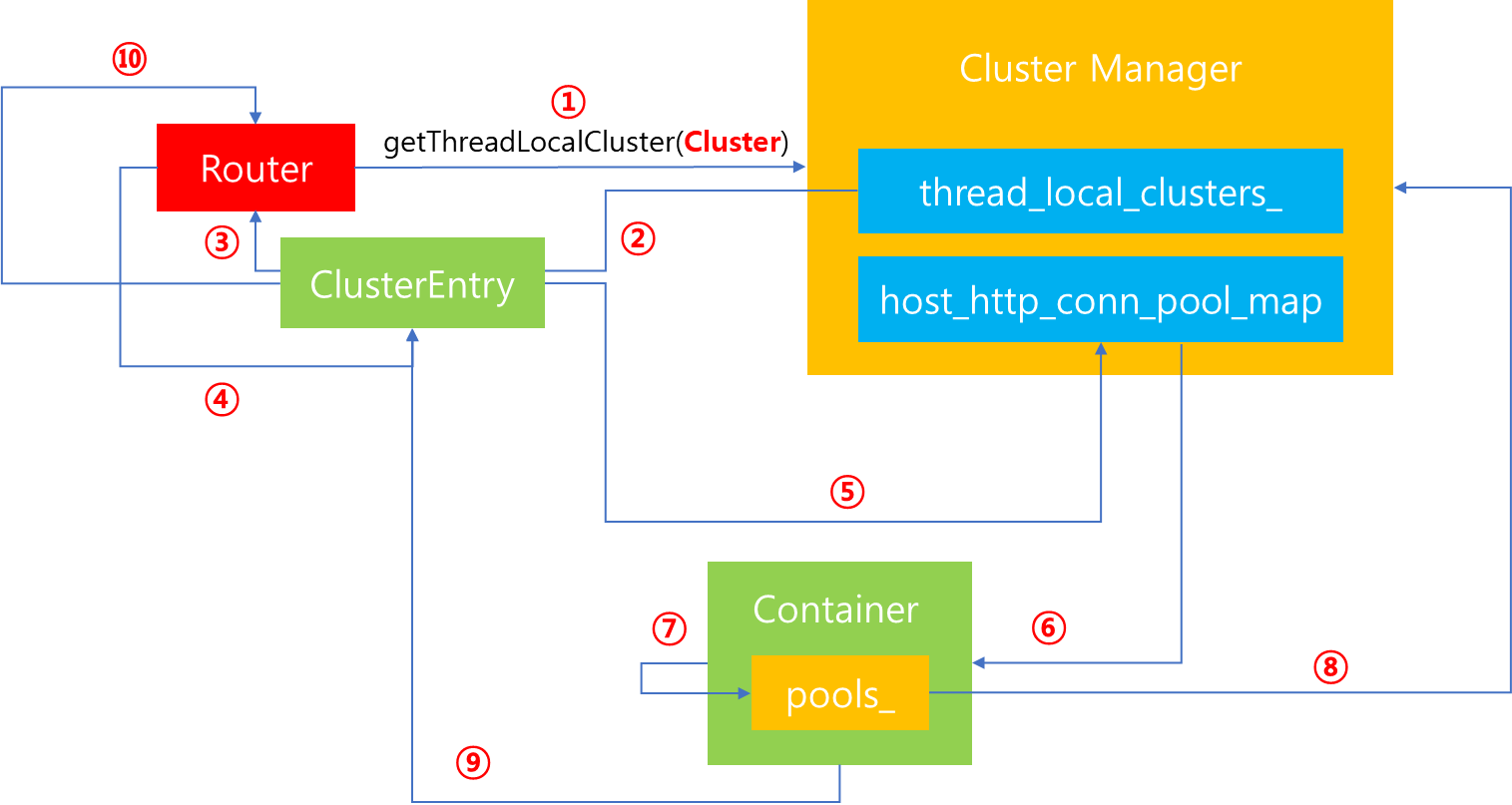
그렇다면 Load Balancer 생성 이후 해당 과정은 어느 단계에서 이루어질까요?
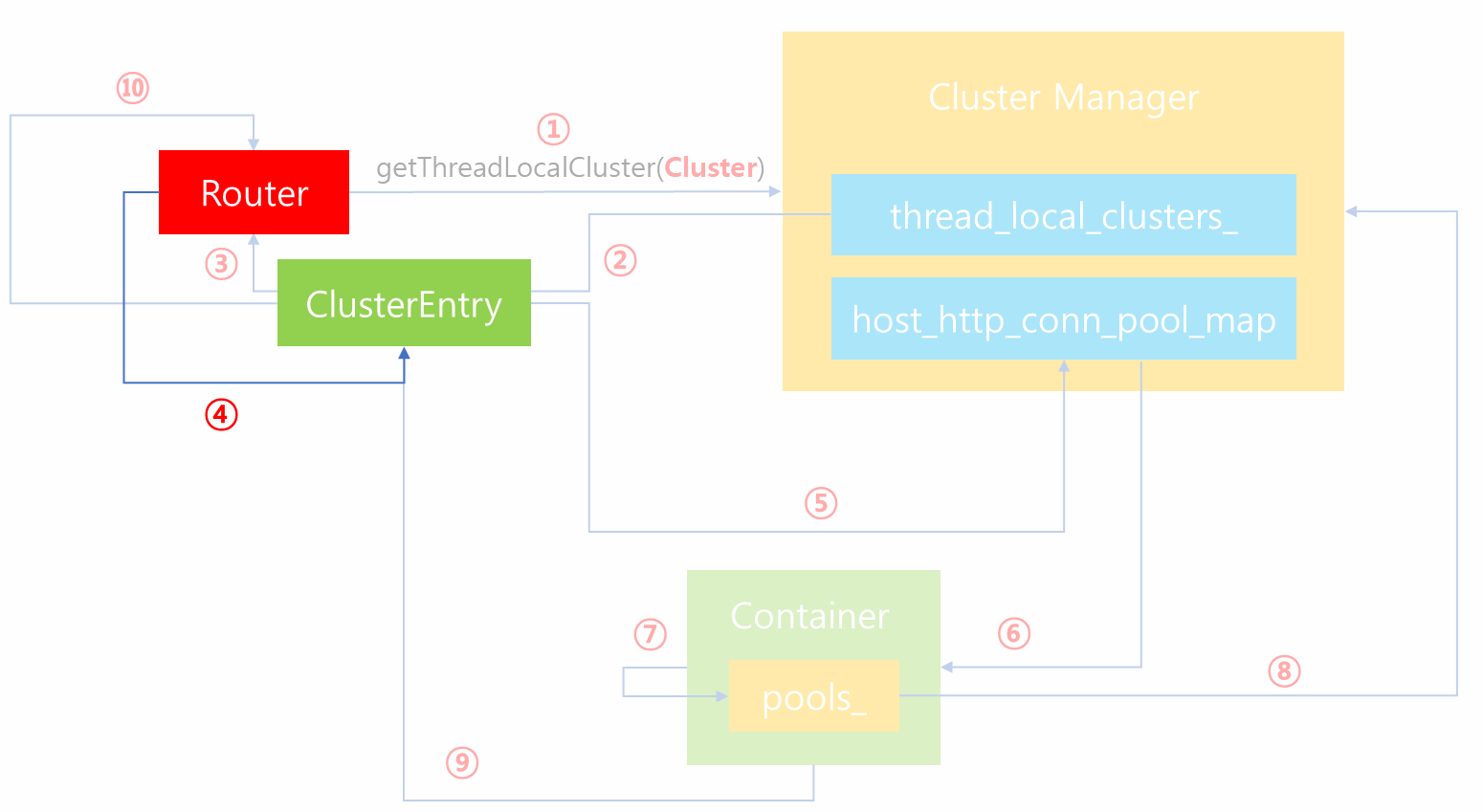
이전 포스팅에서 Router로 부터 Connection Pool 획득 과정에 대해서 다루었습니다. 이 과정에서 Connection Pool을 획득하려면 먼저 host가 지정되어야합니다. 따라서 위 단계에서 4번째 단계 즉 Router가 Cluster 정보를 얻은 다음 Connection Pool을 요청하는 단계에서 Cluster Entry 내부에서는 가장먼저 Load Balancer에게 요청하여 어떤 host에 사용자 요청을 할당할 것인지를 요청합니다. 그리고 해당 host 정보를 토대로 Cluster Manager에게 해당 host에 대한 Connection Pool 요청을 수행합니다.
그렇다면 envoy에서 제공하는 Load Balancer는 어떤 종류가 있으며, 각 종류별로 어떻게 동작할까요? 이에 대해서 개념적으로 살펴보겠습니다.
3. Latency 관점
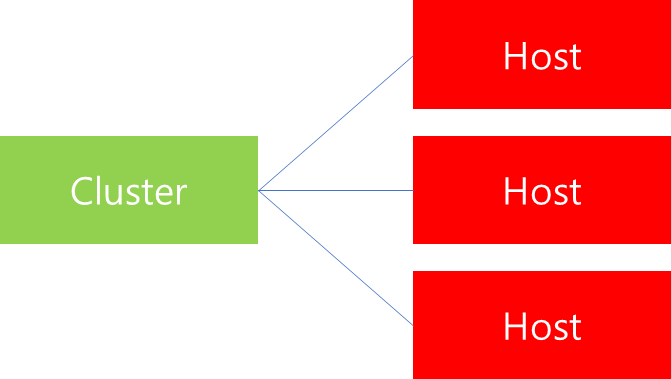
하나의 Cluster 안에 여러개의 Host가 매핑되어있다고 가정해봅시다. 그러면 사용자가 연결 요청을 시도하면, Cluster 내부에 있는 여러 Host 중 하나를 Load Balancer가 선택할 것입니다. 이때 어떤 Host를 선택하는 것이 효율적일까요? 특정 Host에만 요청을 집중한다면, 결국 해당 Host의 처리 능력이 떨어지게되고 결국에는 해당 Host에 장애가 발생할 것입니다. 이를 처리하기 위해 응답속도 관점에서 고려할 수 있는 Load Balancing 알고리즘 종류에 대해 알아보겠습니다.
3-1 Random
첫 번째로 고려해볼 수 있는 것은 Random 알고리즘입니다. Random 알고리즘은 말 그대로 Load를 분배할 때, 임의로 아무 host에 배정함을 의미합니다. 따라서 해당 알고리즘은 특별할 것이 없으며, 굉장히 단순하고 구현하기가 쉽습니다. 즉 이말은 Load Balancing을 수행하는데 있어 overhead가 적다는 것을 의미합니다.
하지만 Random 알고리즘은 무작위로 부하를 분배하는 알고리즘이기 때문에 트래픽이 몰렸을 때, 완벽히 균등하게 모든 Host에 부하가 분배되지 못할 수 있습니다. 즉 운이 좋지 않으면 특정 노드에 부하가 몰릴 수 있음을 의미합니다. 따라서 해당 알고리즘은 트래픽이 적으며, Load Balancing 수행에 대한 overhead를 줄이고 싶을 때 사용하면 좋습니다.
envoy에서는 아래와 같이 lb_policy를 random으로 지정함으로써 Random 알고리즘을 사용하여 부하를 분산할 수 있습니다.
static_resources:
clusters:
- name: my_service
connect_timeout: 0.25s
type: strict_dns
lb_policy: random
load_assignment:
cluster_name: my_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8080
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8081
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8082
3-2. Round Robin
두 번째로 살펴볼 것은 Round Robin 알고리즘입니다.

Round Robin 알고리즘은 보편적으로 많이 사용되는 Load Balancing 알고리즘으로 부하를 모든 Host 서버를 순환하면서 균등하게 분배하는 방식을 의미합니다. 가령 위 그림과 같이 6대의 Client 요청을 분배한다고 가정해봅시다. 그러면 3대의 B/E 서버에 순차적으로 하나씩 Client 요청을 분배합니다. 따라서 첫 요청은 Host 1에게 두번째 요청은 Host 2에게 분배하는 등 요청이 들어올 때마다 균등하게 분배합니다. 해당 알고리즘은 Random과 더불어 구현이 굉장히 단순합니다. Load Balancer 입장에서는 연결된 Host 중에서 이전에 분배했던 Host가 누구였는지 기억한다면, 그 다음에 분배해야될 대상이 누군지 알 수 있기 때문입니다.
static_resources:
clusters:
- name: my_service
connect_timeout: 0.25s
type: strict_dns
lb_policy: round_robin
load_assignment:
cluster_name: my_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8080
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8081
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8082
envoy에서는 위와같이 lb_policy를 round_robin으로 지정하여 Round Robin 알고리즘으로 부하 분산을 수행할 수 있습니다.
3-2-1 Weighted Round Robin
Round Robin 알고리즘은 부하가 몰릴 경우에도 순차적으로 Host에게 부하를 분배하기 때문에 효율적으로 동작합니다. 하지만 여기에는 전제조건이 붙습니다. 그것은 모든 Host가 처리 시간이 동일함을 가정하였을 경우입니다. 이 경우 모든 서버의 하드웨어 스펙이 동일하지 않는다면 어떤 일이 벌어질까요?

가령 Host 1의 하드웨어 사양이 나머지 두 개의 서버보다 2배 이상 좋다고 가정해봅시다. 이 경우 부하를 위와 같이 동일하게 분산하면, Host 1의 경우는 사용자의 요청을 다른 서버보다 빠르게 처리하여 idle 상태일 동안 나머지 서버에서는 여전히 사용자의 요청을 처리하는 경우가 발생합니다. 이 경우 요청 분배를 Host 1에 조금 더 할 수 있다면, 처리 속도를 높일 수 있음에도 불구하고 일반적인 Round Robin의 알고리즘의 경우에는 이를 처리할 수 없습니다. 따라서 이러한 하드웨어 성능 차이를 고려하기 위해 추가된 것이 가중치(Weight)입니다.
static_resources:
clusters:
- name: my_service
connect_timeout: 0.25s
type: strict_dns
lb_policy: round_robin
load_assignment:
cluster_name: my_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8080
load_balancing_weight: 2
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8081
load_balancing_weight: 1
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8082
load_balancing_weight: 3
가중치는 위와 같이 각각의 endpoint 별로 load_balancing_weight 속성을 추가할 수 있습니다. 위 예시는 해당 서버의 처리 능력을 고려하여 운영자가 임의로 매핑한 값이라고 가정해봅시다.

이 경우 Round-Robin 방식으로 동작하지만, 각각의 Server 별로 가중치가 존재하기 때문에 이를 고려하여 위와같이 부하를 분배합니다. 즉 이전과 동일하게 6개의 요청을 전달받는다고 가정한다면, Host 1은 전체 부하의 33% 정도를 할당 받으며, Host 2는 17%, Host 3의 경우는 50%의 부하를 분배받는 것을 볼 수 있습니다.
3-3 Least Request
지금까지 Random과 Round-Robin 알고리즘에 대해 살펴봤습니다. 위 두 알고리즘은 구현이 굉장히 쉽다는 장점이 존재합니다. 특히 Round-Robin의 경우는 부하가 집중될 때도 적은 overhead를 가지면서 적절히 부하를 분배할 수 있습니다. 하지만 Round-Robin에 가중치까지 적용하였다 할지라도 여기에는 이만큼 처리할 수 있다는 가정을 기반으로 처리하는 것이지 실제 처리량을 기반으로 Load Balancer가 부하를 처리하지는 않습니다.

가령 위 그림과 같이 Host 서버의 하드웨어 스펙이 모두 동일하다고 가정해봅시다. 또한 해당 host들이 매핑된 실제 서버에는 하나의 B/E만 존재하는 것이 아니라 여러 다른 app이 존재한다고 가정해봅시다. 이는 서버가 k8s 클러스터 등으로 구성되어있다면 충분히 가능한 시나리오일 것입니다.
이 경우 Round-Robin으로 분배하거나 Weighted Round-Robin을 적용하기 쉽지 않을 것입니다. 따라서 이 경우에는 실제 응답 요청을 처리하는 Connection 개수를 실시간으로 모니터링하면서 부하를 얼마나 감당할 수 있는지를 살펴보고 Load Balancer가 부하가 적은 쪽으로 전달하는 것이 효율적입니다.
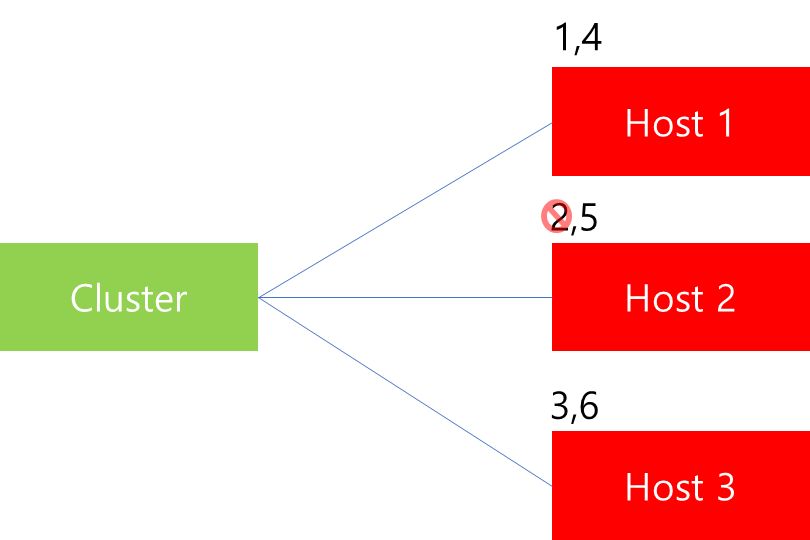
가령 Least Request 알고리즘 환경에서는 위와 같이 현재 6개 Host에 부하를 분배한 상황에서 가령 Host 2에서 2번 요청에 대한 처리가 완료되어 Connection을 해제하였을 때, 그 다음 7번 요청을 Host 2에게 분배하는 방식입니다. 따라서 이를 지원하는 Load Balancer 타입에는 현재 연결된 active_requests가 몇 개인지를 관리하고 있습니다.
또한 Least Request 알고리즘을 사용하는 환경에서도 서버마다 하드웨어 스펙등이 다를 수 있기 때문에 가중치를 적용할 수 있습니다.
static_resources:
clusters:
- name: my_service
connect_timeout: 0.25s
type: strict_dns
lb_policy: least_request
load_assignment:
cluster_name: my_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8080
load_balancing_weight: 2
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8081
load_balancing_weight: 1
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8082
load_balancing_weight: 3
가령 위와 같이 envoy에서 지정했다면, 내부적으로는 아래와 같은 공식을 적용하여 가중치 값이 높은 쪽으로 부하가 분산됩니다. 참고로 해당 공식은 envoy 공식 문서에서 발췌하였습니다.
weight = load_balancing_weight / (active_requests + 1)^active_request_bias
참고로 active_request_bias 값은 load balancing 과정에서 active_requests에 대하여 우선 순위를 조정할 수 있는 값으로써 envoy config를 통해 지정할 수 있으며, 기본 값은 1.0입니다.
4. 가용성 관점
지금까지 세 가지 알고리즘에 대해서 살펴봤습니다. 세 가지 알고리즘의 특성은 구현이 용이하며, 합리적인 부하 분산을 균등하게 해준다는 점에서 이점이 존재합니다. 하지만 다음과 같은 상황에서는 어떨까요?
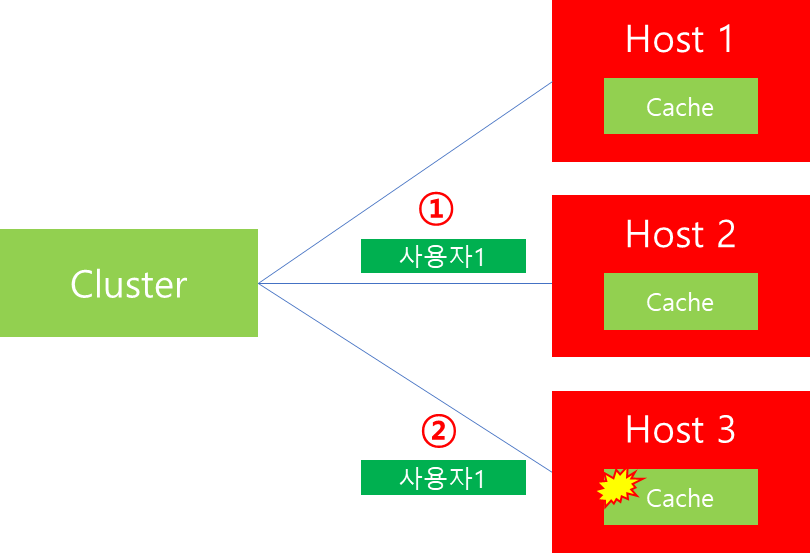
가령 위 그림과 같이 3개의 Host가 있고 각각의 Host에는 별개의 Cache 레이어가 존재하는 시스템이라고 가정해봅시다. 해당 시스템은 시스템 규모가 너무 커서 사용자별로 특정 데이터를 샤딩하여 각각의 Host 별개 Cache에 보관한다고 가정해봅시다. 이때 Cache Hit를 높이기 위해서는 특정 사용자 요청은 특정 Host로 보내져야 효율적일 것입니다.
하지만 Random, Round-Robin, Least Request 알고리즘은 이러한 특성을 보장해주지 않습니다. 그 이유는 해당 알고리즘은 해당 시점 전달된 트래픽 부하 분산에 초점이 맞추어져있기 때문입니다. 따라서 이전 요청 응답 전달 이후 같은 사용자 요청이 전달되었을 때, 각기 다른 Host로 전달될 가능성이 매우 높습니다. 그리고 어디로 배정될지 운영자 입장에서는 정확히 알 수 없기 때문에 운영상 불확실성을 가지고 있습니다. 이러한 불확실성은 대규모 시스템을 운영하는 입장에서는 엄청난 부담이 아닐 수 없습니다.
그렇다면 이러한 특성을 고려한다면, 어떻게 부하 분산하는 것이 좋을까요?


일반적으로 많이 사용하는 방법은 Hash 함수와 Modular를 활용하는 것입니다. 즉 위 그림과 같이 Host 목록에 대해서 특정 Key(사용자 Id) 등을 활용한 Hash 값을 토대로 Modular 연산을 적용하면, 특정 사용자 요청에 대해서는 매번 같은 결과 값이 나오게되니 아무리 요청을 많이 할지라도 특정 Host로 전달됨이 보장됩니다. 참고로 Modular 연산을 적용하는 이유는 아무리 Hash 값이 다르더라도 서버의 갯수만큼으로 Modular 연산을 수행하면, 서버 갯수 이내만큼의 값을 얻을 수 있기 때문입니다.
가령 Modular 연산 결과가 0이면 Host 1, 1이면 Host 2, 2이면 Host 3으로 할당된다고 가정했을 때, 사용자1의 Hash 값이 1이 나왔다면, 매번 Host 2로 전달이 보장됩니다.
위와 같이 살펴봤을 경우 Hash 와 Modular 연산 적용 또한 부하 부하를 적절히 분산하는데, 도움이 되는 것으로 보입니다. 하지만 여기에는 다음과 같은 문제가 있습니다.

가령 위와 같이 Host 1 ~ 3에 Connection과 사용자 데이터들이 Cache에 할당되어있다고 가정해봅시다. 이때 해당 비즈니스가 트래픽이 급격히 올라 Scale Out을 해야하는 상황이 발생하면 어떻게 해야할까요?
위 그림을 살펴보면 기존 Modular 연산은 Host 개수가 3개기 때문에 1 ~ 3 Host에만 할당할 수 있을 뿐 Host 4에는 할당할 수 없습니다. 따라서 Host 4를 수용하기 위해서는 Host 4를 Host 리스트에 포함하고 나머지 연산 또한 4로 변경해야할 것입니다.
하지만 이 경우 지금까지 분배되었던 Connection과 데이터 저장에 커다란 이슈가 발생합니다.
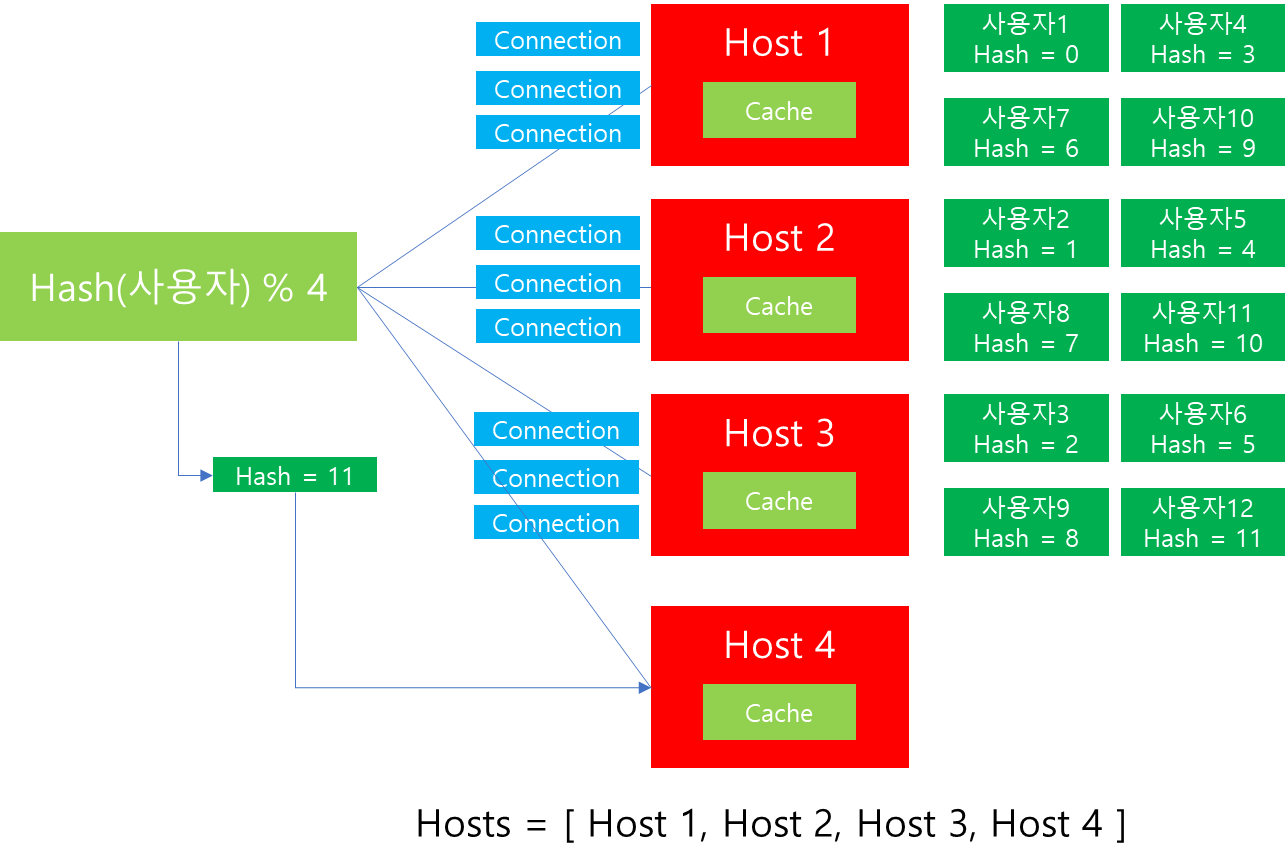
기존에 Hash 값이 11인 경우에는 원래대로라면 Host 3에 지속 라우팅이 되었어야 합니다. 하지만 연산 수식이 달라졌기 때문에, Host 4가 추가된 이후에는 수식의 결과에 따라(11%4=3) Host 4에 라우팅 될 것입니다. 따라서 Scale out 이후에도 서비스 안정성을 유지하기 위해서는 기존 Host 들에 연결된 Connection과 Cache된 데이터들에 대한 재분배가 필요합니다.
그렇다면 어느정도 데이터가 재분배가 일어나야할까요? 위 사례를 기반으로 데이터 재분배가 일어난 다음 상황을 살펴보겠습니다. 이해를 돕기위해 데이터 재분배가 발생한 항목은 파란색 음영으로 표시하였습니다.
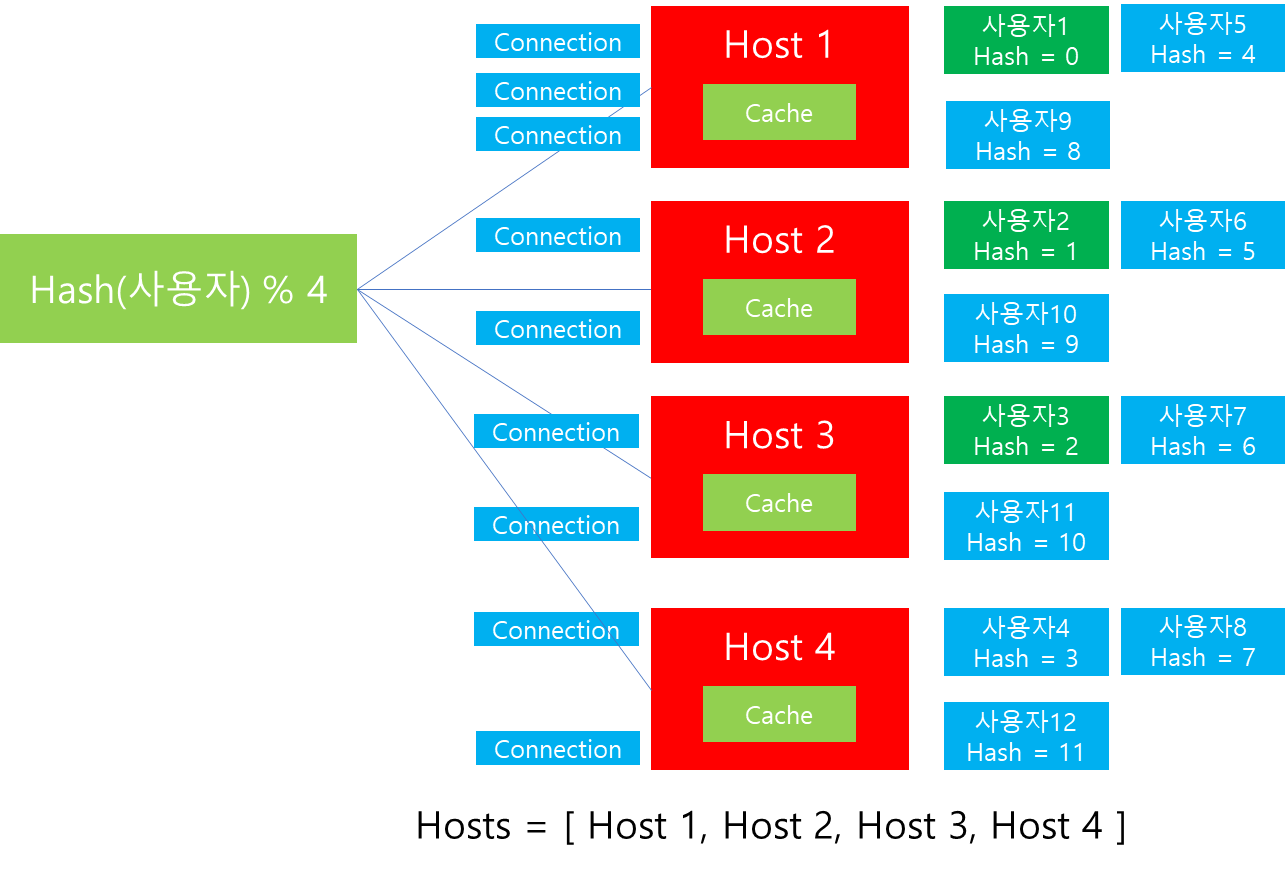
위 그림의 결과를 통해서 확인할 수 있는 사실은 Host 4 추가 이후 기존 데이터까지 포함해서 총 75%의 데이터 이동이 필요하며, 그만큼 Connection 또한 재분배가 일어난다는 점입니다. 이는 Scale out 수행해야하는 운영자 입장에서는 엄청난 부담으로 작용할 수 있습니다. 그 이유는 데이터 이동과 Connection을 분배하는 과정에서 발생하는 overhead로 인해 자칫 다른 Host에도 장애가 발생할 수 있기 때문입니다.
따라서 Hash와 Modular 연산을 통해서 부하를 분산하는 환경에서는 Scale Out이 발생할 때, Connection 분배와 데이터 이동을 최소화하는 방안을 강구해야합니다. 그렇다면 어떻게 이를 해결할 수 있을까요?
첫 번째로 고민해볼 수 있는 방법은 Scale Out 시에 기존 서버 대비 2배씩 확장하는 방법입니다.

가령 위 그림과 같이 기존 3대의 Host에서 Scale Out을 위해 서버를 2배로 확장했을 때 모습입니다. 이때 Connection 및 데이터 재분배 현황을 보면, 서버를 2배로 늘렸을 때 데이터 재분배 비율이 50% 정도로 낮아진 것을 볼 수 있습니다. 또한 데이터 이동 현황을 보면, 기존 Host가 보유하고 있던 데이터 중 일부가 다른 Host에게 그대로 전달된 것을 확인할 수 있습니다. 이는 데이터를 마이그레이션 해야하는 운영자 입장에서도 계획을 세우기 훨씬 수월하며, 분배에 대한 비효율도 다소 줄일 수 있습니다. 하지만 매번 Scale Out이 필요할 경우 서버를 2배씩 늘리는 것은 매우 비효율 적일 것입니다. 또한 이는 Scale Out시에는 도움이 될 수 있지만, Scale In을 수행하는 경우에는 문제가 발생합니다. Scale In을 수행할 때는 1/2씩 서버를 줄여야하는데 현실적으로 힘들기 때문입니다.
따라서 대규모 시스템에서 Scale in/out이 잦은 Application을 사용하는 경우 단순한 Hash 함수와 Modular 연산의 적용은 운영 안정성이 저하되는 이슈를 낳습니다.
4-1 Ring Hash(Consistent Hashing)
이전에 살펴봤듯이 Hash와 Modular 기반으로 부하를 분산시에 Scale In/Out에 탄력적으로 대응하기 위해서는 서버 추가/삭제 이후 Connection과 연관된 데이터 재분배되는 양이 적어야 합니다. 이때 Consistent Hashing 알고리즘은 이에 대한 해결책을 제시해줍니다.
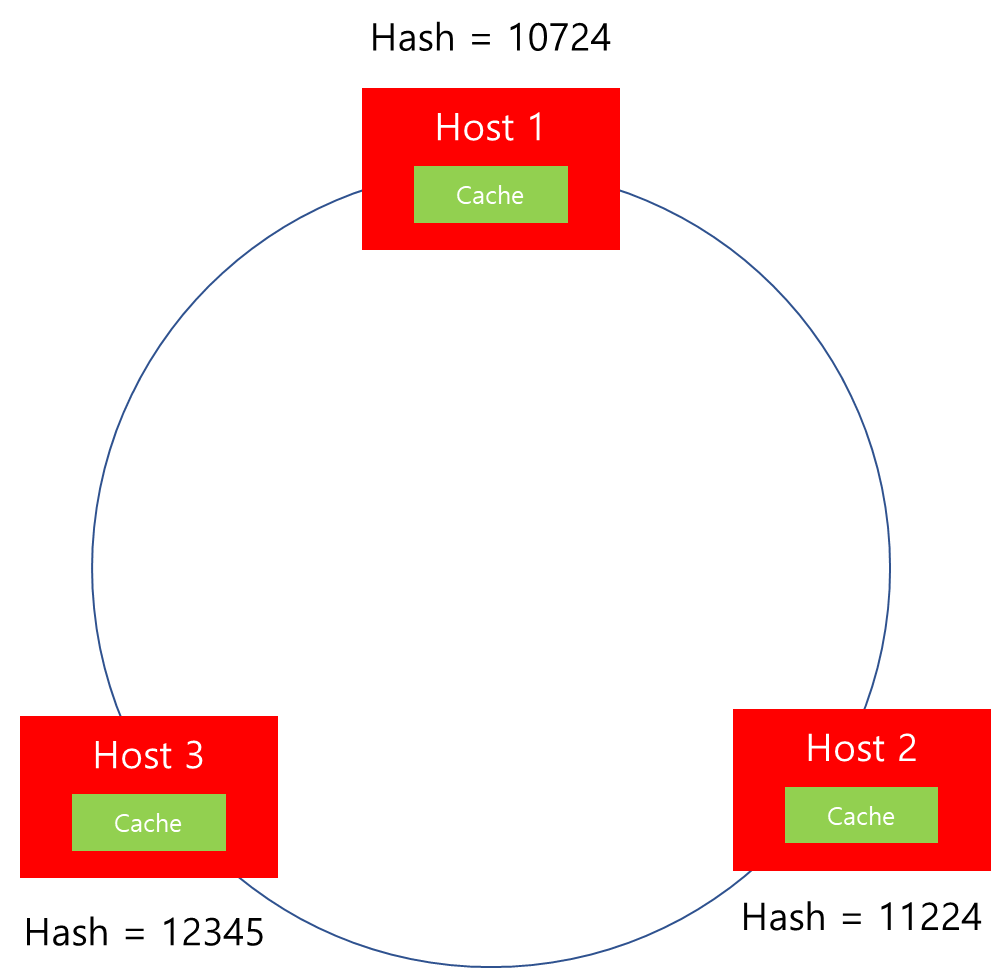
Consistent Hashing 방식은 위와 같이 Host 들이 하나의 Circle 안에 배치되어있다고 가정합니다. 그리고 각각의 Host가 담당하게될 Hash 값의 데이터 범위를 할당하여 그 안에 위치한 Connection을 담당하는 구조입니다. 이때 두 Host 사이에 위치한 Hash 값을 지닌 Connection은 시계 방향에 위치한 Host에 할당되는 것이 특징입니다.
| Host | 데이터 담당 범위 |
| Host 1 | 해시값 <= 10724 OR 해시값 > 12345 |
| Host 2 | 10724 < 해시값 <= 11224 |
| Host 3 | 11224 < 해시값 <= 12345 |
즉 위와 같이 각각의 Host 별로 Client 요청에 대한 Hash 값을 계산하였을 때, 해당 Hash 값이 담당하는 Host를 범위로써 관리합니다. 위와 같이 Ring Hash가 구축된 상태에서 Client 요청이 들어왔다고 가정해보겠습니다.
Case 1. 해시값 10765 요청 전달 시
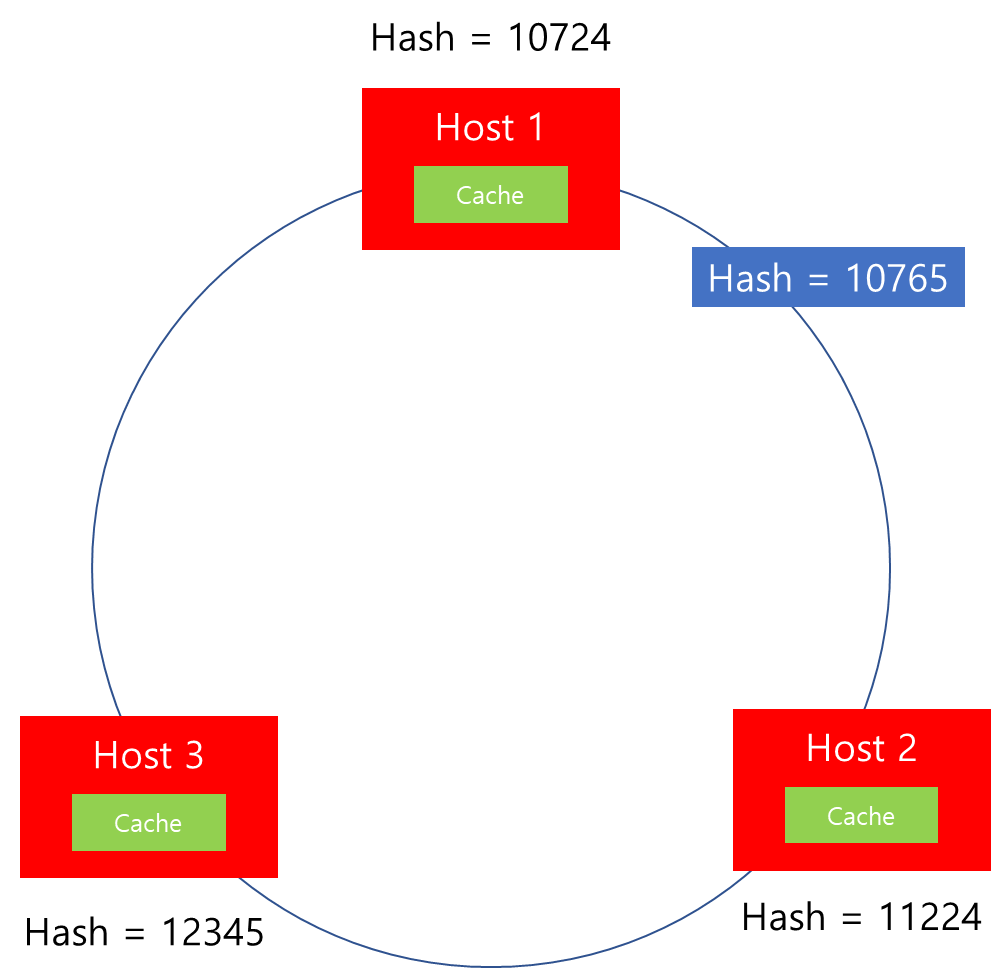
해당 해시값이 10765이므로, 이는 Host1의 데이터 범위인 10724 보다 크고 Host 2의 해시값 범위인 11224보다 작으므로 Host 2에 할당될 것입니다. 또한 이후에 동일한 해시값이 입력된다면 지속적으로 Host 2에 할당됨이 보장됩니다.
Case 2. 해시값 12086 요청 전달 시
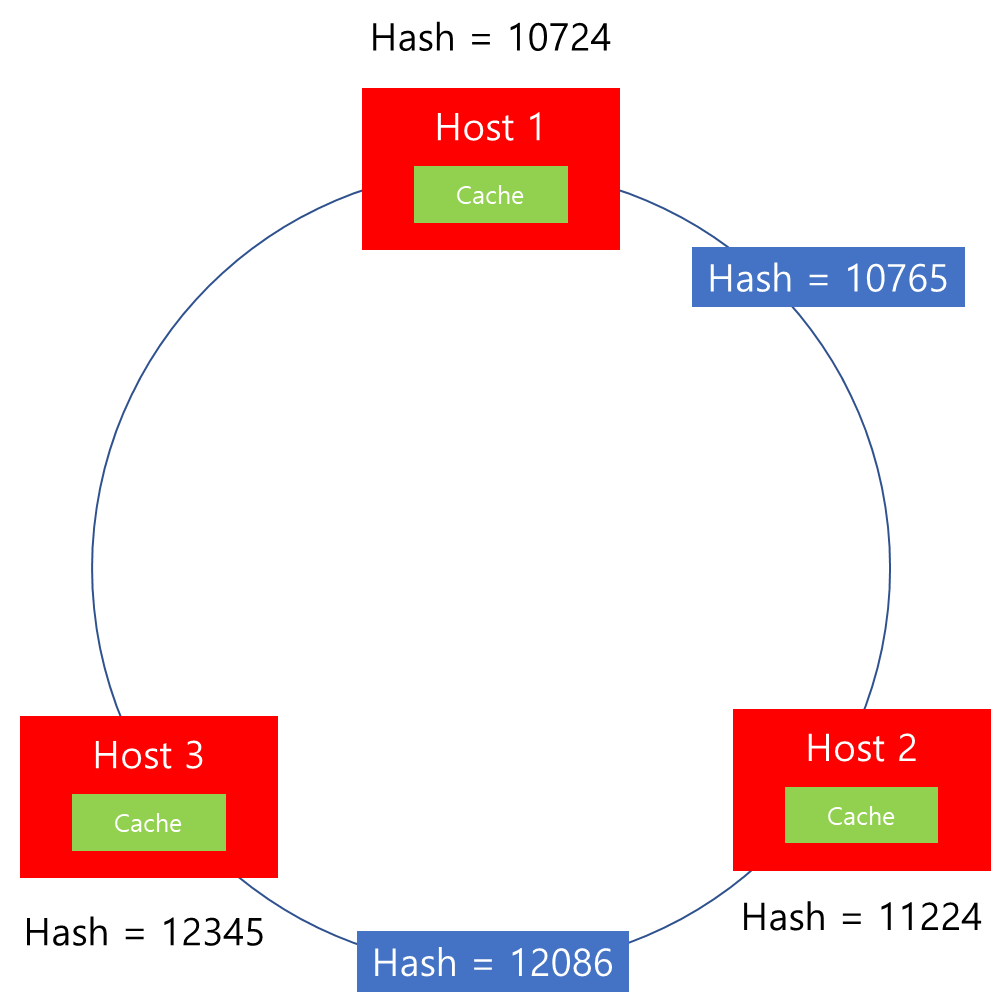
해시값이 12086의 요청이 전달되면, 11224보다 크고 12345보다 작으므로 Host 3에 Connection이 할당됩니다.
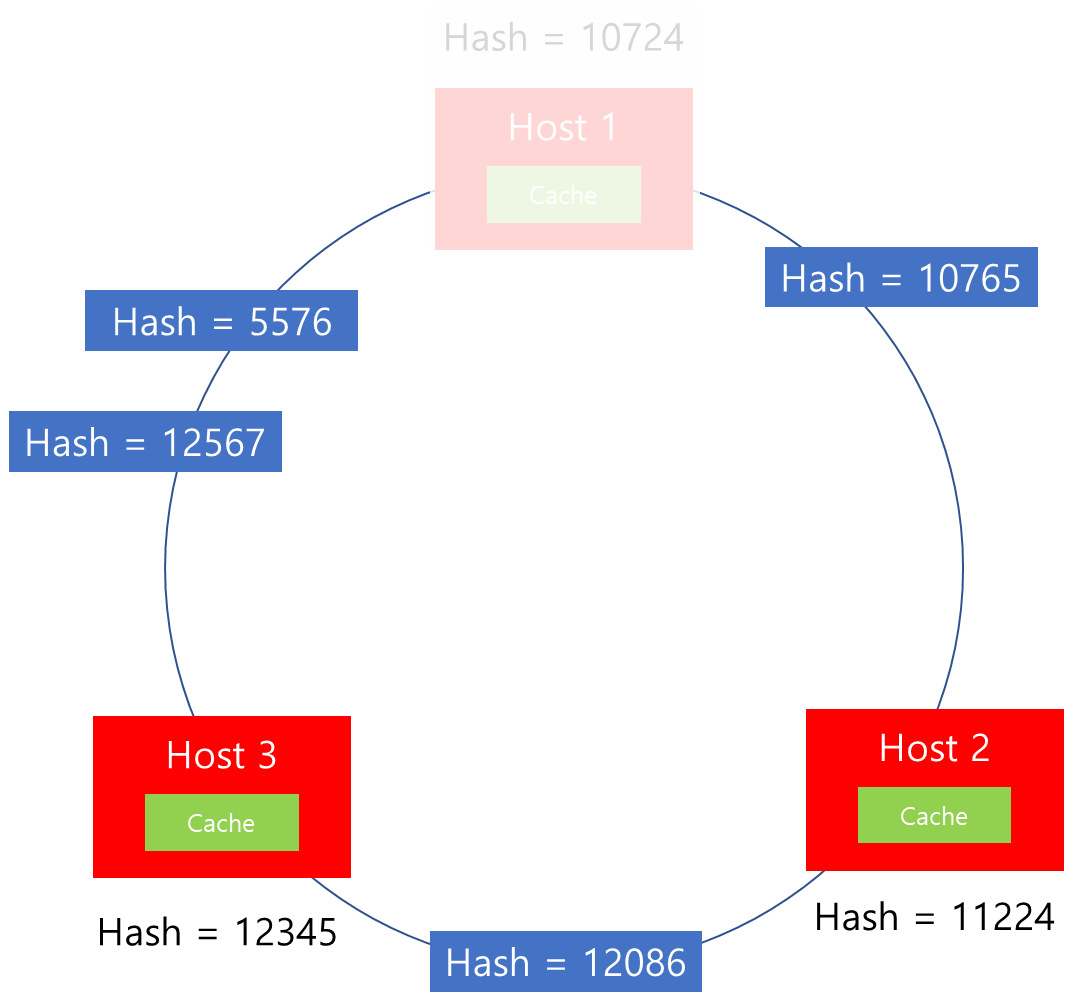
이후 지속적인 Connection 연결이 요청되었고 그 결과 위와 같은 모습이 되었다고 가정해봅시다. 위 그림을 살펴보면 Host 1은 해시값이 5576과, 12567에 해당하는 Connection이 연결된 상황이라고 볼 수 있습니다. 만약 이 상황에서 Host 1에 장애가 발생하여 Down되었을 경우 어떻게 될까요?
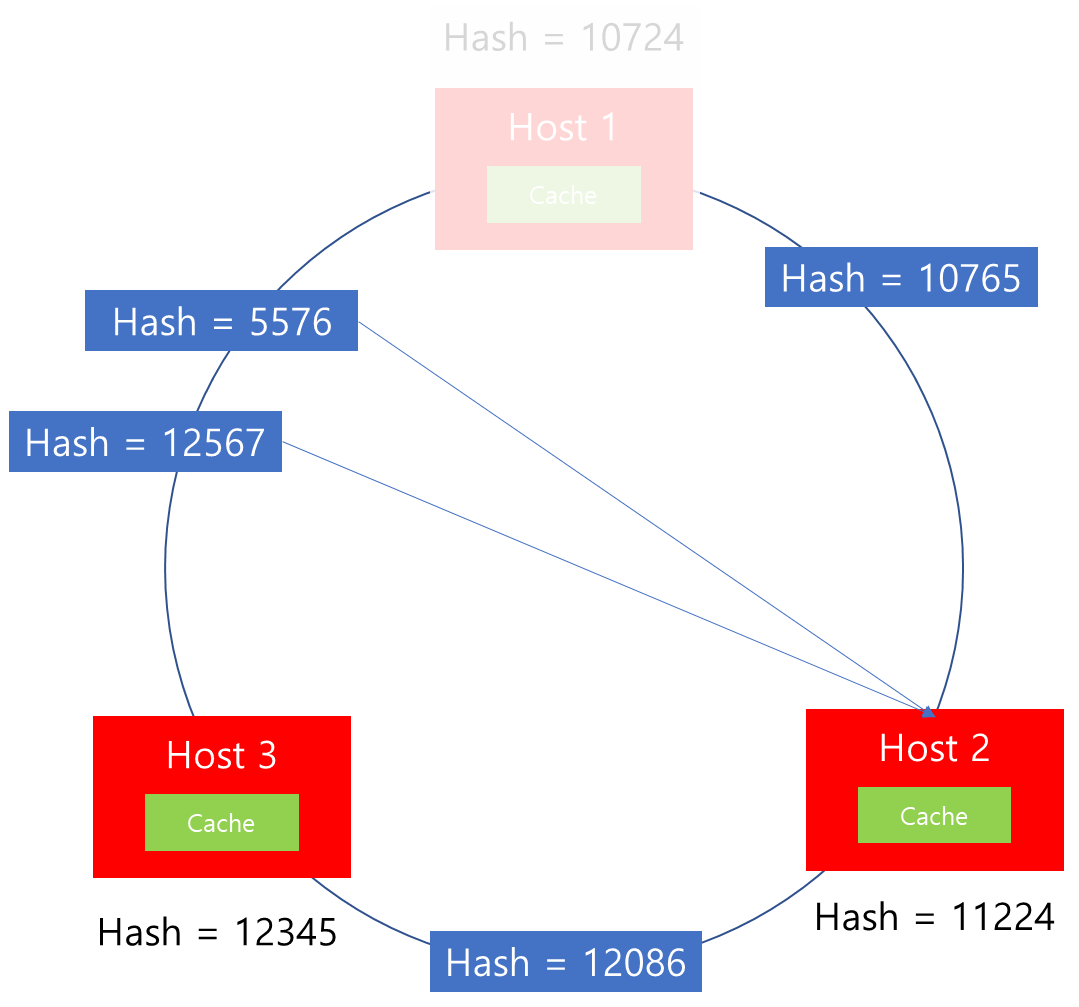
Ring Hash를 살펴보면, Host 1이 없어졌을 경우 그 다음 연결된 Host는 Host 2임을 알 수 있습니다. 따라서 Consistent Hashing 알고리즘에서는 Host 1에 할당되었던 기존 Connection이 Host 2로 모두 이관됨을 확인할 수 있습니다.
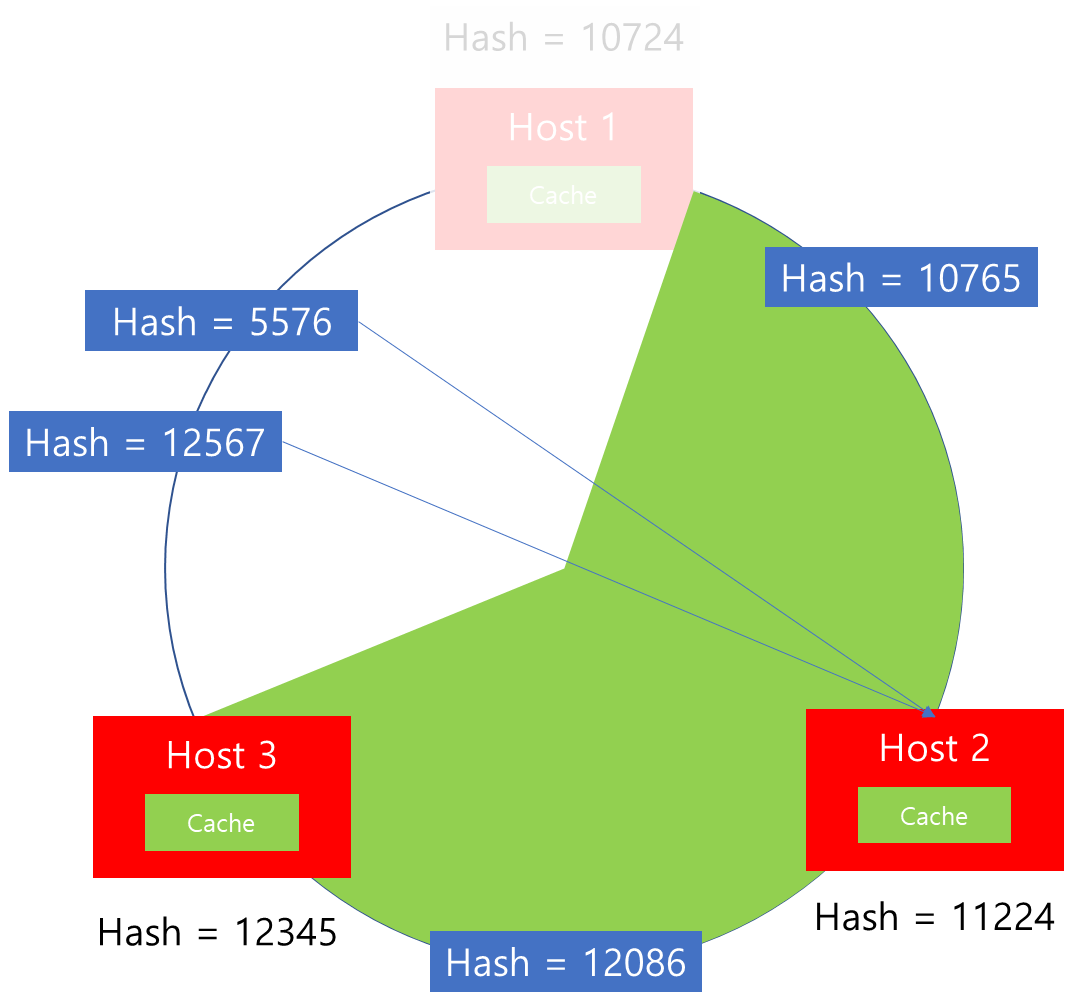
또한 위 결과를 통해 흥미로운 사실을 알 수 있습니다. Host 삭제에 따른 변화를 살펴보면, 기존 Host 1에 할당된 Connection만 영향을 받을 뿐 그외 나머지 Host에 연결된 Connection에는 전혀 영향을 받지 않는 것을 확인할 수 있습니다. 이를 통해 알 수 있는 사실은 Consistent Hashing 알고리즘을 사용할 경우에는 이전과 달리 Host 추가/삭제에 따른 영향도가 적어짐을 알 수 있습니다.
하지만 위와 같은 기본 Consistent Hashing 방식은 문제점이 존재합니다. 위 그림을 통해 살펴보면 Host 1이 Down 되었을 때 그 부하가 고스란히 Host 2에게 전달되는 것을 확인할 수 있습니다. 이는 Host 2 입장에서는 엄청난 부담으로 작용할 수 있습니다. 두 번째 문제는 Hash 값이 고르게 분포되지 않을 경우 특정 Host에 연결되는 Connection이 많을 수 있음을 의미합니다. 가령 위 예에서는 비교적 Hash 값이 고르게 분포되어 각각의 Host에서 Connection을 수행할 수 있었습니다. 하지만 상황에 따라서는 특정 Hash 범위 값이 지속 할당되면, 특정 Host에만 부하가 집중될 수 있습니다. 따라서 이를 보완하기 위해서 추가적으로 Virtual Node를 추가하는 방법을 많이 사용합니다.
4-2-1 Virtual Node
기존의 문제점이 서버 추가/제거 시 특정 Host에 Connection 재매핑이 몰린다는 특징이 있었습니다. 따라서 이러한 문제를 해결하기 위해서는 Virtual Node를 추가합니다. 이해를 돕기 위해 사례를 통해 확인해보겠습니다.
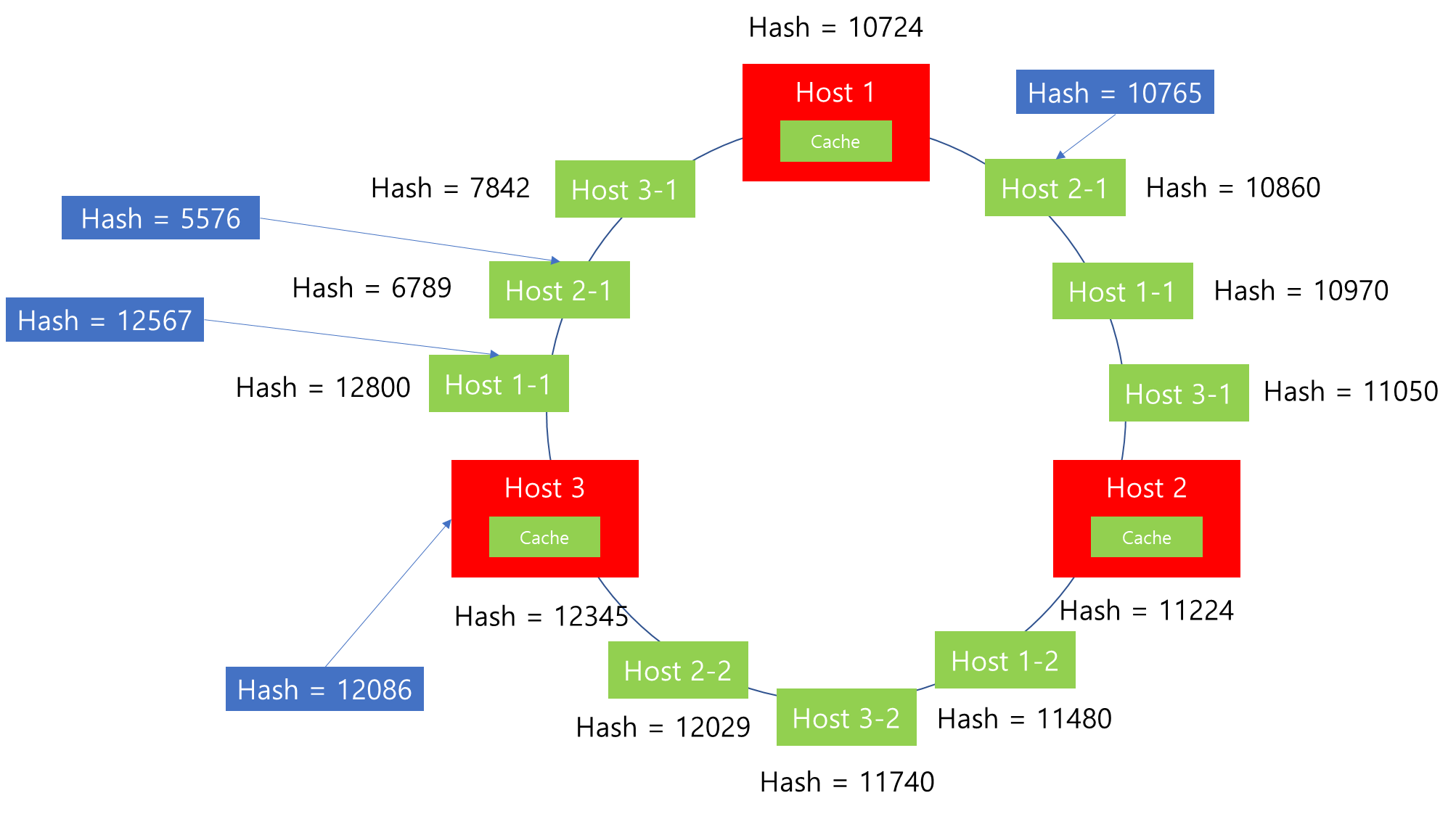
위와 같이 Host 별로 하나씩 Ring에 배치하는 것이 아니라 Ring Hash에 여러개의 Virtual Node를 생성하여 해시값을 부여하고 위 그림과 같이 배치를 수행합니다. 그러면 각각의 Node와 데이터 사이의 해시값 범위가 줄어들게 됩니다. 따라서 위 그림과 같이 Connection 별로 Hash 값을 수행한 결과가 조금 더 다양한 Host로 매핑될 수 있습니다.

이러한 상황에서 Host 1에 Down이 발생하면 어떻게 될까요? 기존에 Host 1에 매핑되었던 Connection Hash 값 12567만 재배치를 수행하면 되기 때문에, 기존의 Consistent Hashing 방식 보다는 재배치되는 Connection 수가 많이 줄어들 수 있습니다.
이렇듯 Virtual Node를 Ring Hash에 추가하면, 재배치의 이점과 Virtual Node 개수가 증가할 수록 상대적으로 촘촘하게 Ring에 배치되기 때문에 부하를 보다 고르게 분산할 수는 있습니다. 다만 이러한 방법도 완벽하게 부하를 고르게 분산할 수는 없습니다.
Consistent Hashing 방식의 구현체는 다양하게 존재하는데, envoy는 위와 같이 내부에 virtual node가 추가된 형태의 자체 Consistent Hashing 방식으로 구현되어있습니다.
이때 각각의 host 별로 Virtual Node 할당을 위해서 envoy에서는 Configuration 설정에 minimum_ring_size, maximum_ring_size, 그리고 Hash 함수 등을 설정할 수 있으며, 각각의 Host 별로도 load_balancing_weight를 지정하여 개별 Host 별로 할당받는 hash bucket 개수를 조정할 수 있습니다.
이를 적용한 envoy configuration 예시는 다음과 같습니다.
static_resources:
clusters:
- name: my_service
connect_timeout: 0.25s
type: strict_dns
lb_policy: ring_hash
ring_hash_lb_config:
minimum_ring_size: 1024
load_assignment:
cluster_name: my_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8080
load_balancing_weight: 2
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8081
load_balancing_weight: 1
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8082
load_balancing_weight: 3
지금까지 Consistent Hashing 방식에 대해서 살펴봤습니다. 그렇다면 Consistent Hashing 방식은 어떤 경우 사용하면 좋을까요? 이 방식은 Cluster와 Server의 변경이 잦은 경우 즉 대규모 환경에서 Reliability가 중요한 경우 Connection의 안정적인 재매핑을 위해 사용하면 좋습니다.
하지만 Ring Hash를 만들고 이를 유지하기 위해서는 기존에 소개한 다른 알고리즘(Random, Round-Robin, Least Request)에 비해 조금 더 많은 메모리 사용이 필요합니다. 또한 Cluster로부터 Server가 추가되거나 제거될 때 Hash Ring을 재구축 해야하기 때문에 update가 다른 알고리즘에 비해 조금 느린 특성이 있습니다.
따라서 해당 알고리즘을 사용한다면 이러한 특징을 참고하여 여러 알고리즘과 비교 및 PoC를 통해 선정하는 것이 좋습니다.
4-2 Maglev
마지막으로 소개할 알고리즘은 Maglev 입니다. 해당 알고리즘은 Google에서 사용하는 Load Balancing 알고리즘으로 Consistent Hashing에 비해 부하를 보다 균등하게 분산해줄 수 있습니다. 또한 Consistent Hashing 알고리즘과 마찬가지로 서버의 삭제/수정 시에 Connection 재매핑 비율을 줄여줍니다. 해당 알고리즘 특징에 대해 살펴보면 다음과 같습니다.
Maglev 방식을 통해 부하를 분산하기 위해서는 2가지 자료구조가 필요합니다.

첫 번째는 Lookup table입니다. Lookup table은 추후 Load Balancer가 어떤 Host로 보낼지 라우팅 정보를 기록하는 리스트입니다. 즉 라우팅 당시 해시 값을 Lookup table의 사이즈만큼으로 나머지 연산을 했을 때 나오는 index를 기준으로 Lookup table에 매핑된 Host로 라우팅을 수행합니다. 위 예시의 경우 Lookup table의 사이즈를 임의로 7로 선정했는데, Lookup table의 사이즈는 변경이 가능하며, 사이즈가 크면 클 수록 향후 서버 추가/삭제 등의 영향을 적게 받습니다.
두 번째 살펴볼 것은 Permutation table입니다. 해당 자료구조는 각 Host 별로 Lookup 테이블 인덱스 어디에 매핑될 지를 희망하는 우선순위를 나타냅니다. 따라서, Lookup table의 사이즈가 결정되면, 가장 먼저 수행하는 것은 각각의 Host 별로 어디에 매핑되기를 희망하는지를 해시 연산을 통해 계산합니다. 해당 과정을 Permutation이라고 부릅니다.
Permutation이 끝나고 나면, 위와 같이 각 Host 별로 우선순위를 결정할 수 있습니다. 그다음에 수행할 작업은 Permutation table을 토대로 Lookup table 내용을 채우는 작업입니다.
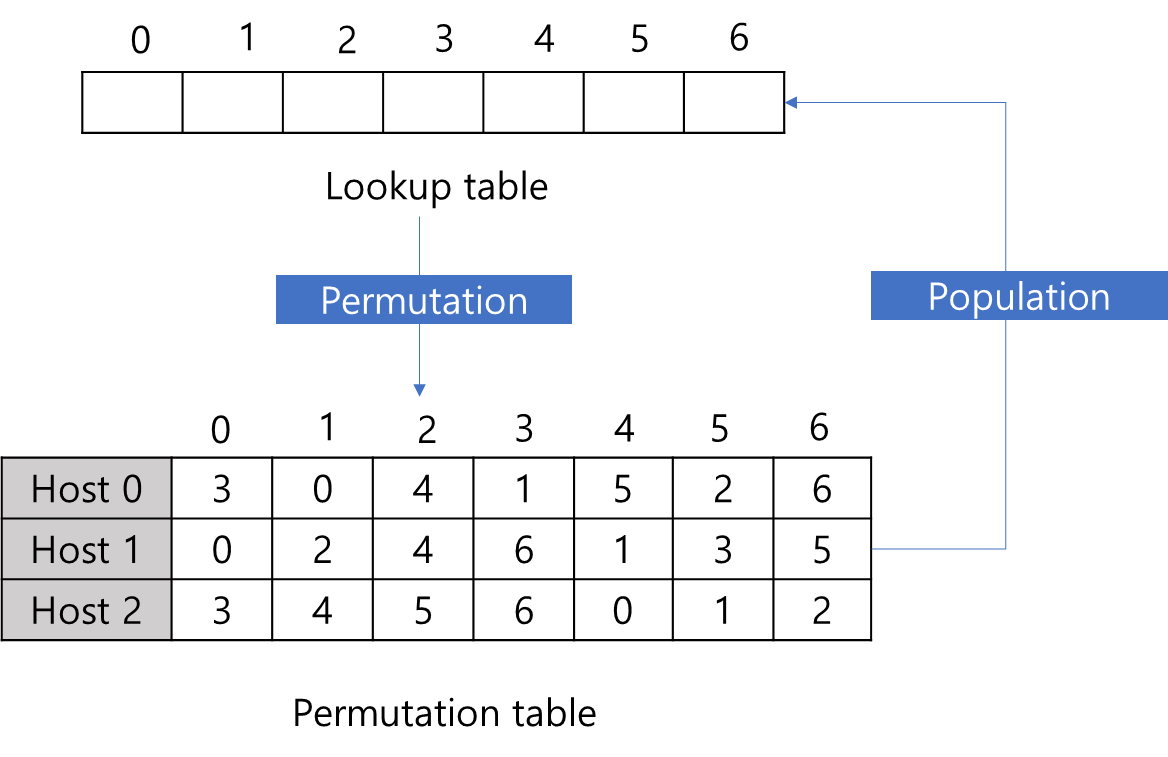
이 과정은 Popluation 이라고 부르며, 해당 과정을 통해 Maglev 알고리즘이 균등하게 부하를 분산할 수 있도록 Lookup table을 채워줍니다. 그렇다면 Popluation은 어떻게 이루어질까요? 위 Permuation table을 기초로 Popluation 과정을 조금 더 자세히 살펴보겠습니다.

N : Host 개수
M : Lookup table 크기
next[] : Permutation table 내에서 Host 별로 다음 index를 추적을 위한 배열
entry[] : Lookup table
Google의 Maglev 논문을 살펴보면, 위와 같이 Popluation 하는 과정에 대한 Pseudocode를 살펴볼 수 있습니다. 해당 과정을 몇 단계만 차례차례 살펴보면서 동작 과정에 대해서 이해해보겠습니다.
Step 1.

가장 먼저 수행하는 작업은 Lookup table과 Next 배열의 초기화입니다. 이때 Lookup table의 모든 원소는 -1로 Next 배열의 경우 배열의 index를 가르켜야 하기 때문에 0으로 초기화하는 것이 특징입니다.
Step 2.

초기화가 완료되면, Host 별로 순차적으로 Lookup table을 갱신합니다. 먼저 0번 Host의 index가 현재 Next에서 0이므로 Permutation table의 0번 index를 살펴봅니다. 이때 Host 0은 Lookup table의 3번 index에 매핑되기 희망하므로 Lookup table의 해당 index을 탐색합니다. 이때 Lookup table에 해당 값이 -1 즉 아무 값도 매핑되지 않은 상태이므로 갱신이 가능합니다. 따라서 해당 index를 Host 0번 서버의 index인 0번으로 갱신합니다.
이후 Next 배열에서 그 다음 Permutation Table의 다음 참조 index를 가르키기 위해서 1증가한 값으로 갱신합니다.
Step 3.
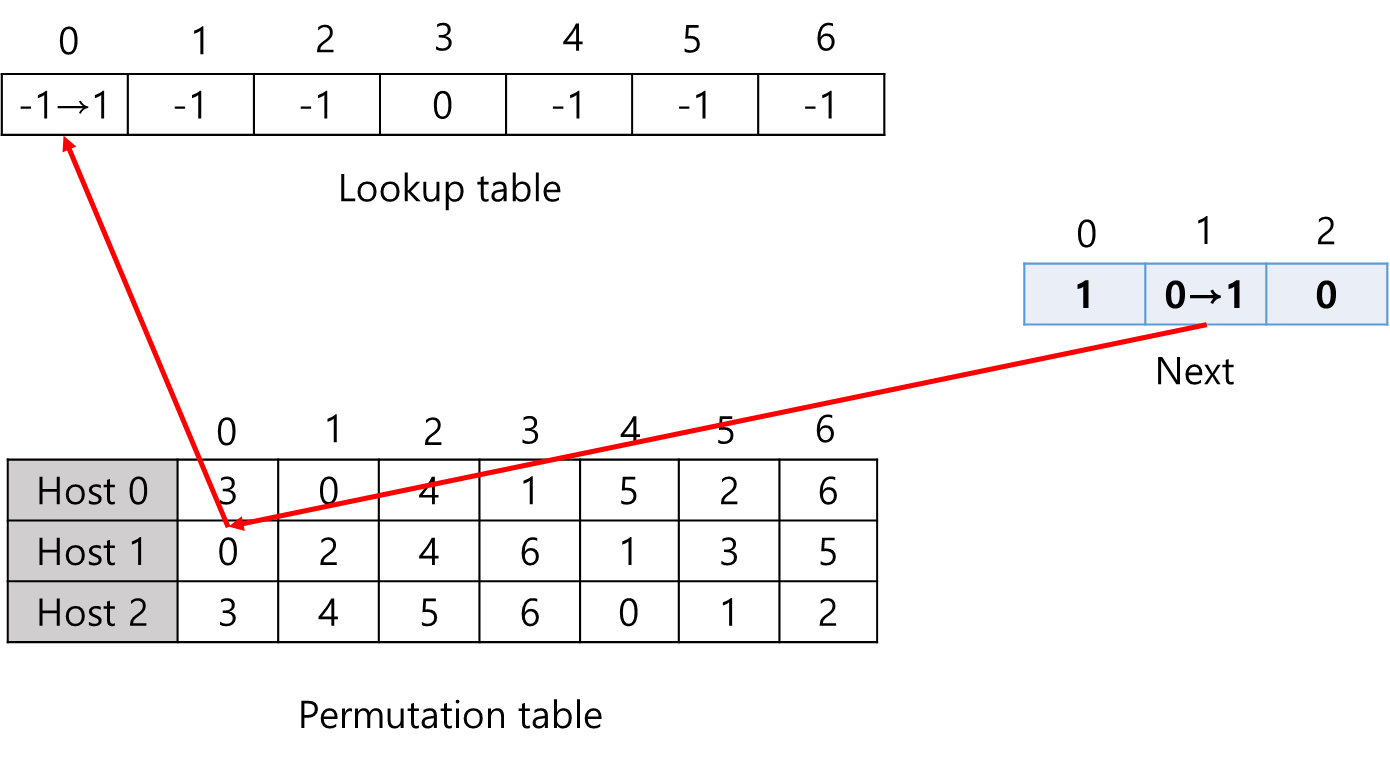
Host 0번이 매핑되었으므로 그 다음은 Host 1 차례입니다. Host 1의 현재 index가 0번이므로 Permutation table에서 해당 index를 살펴봅니다. 이때 Host 1은 Lookup table의 0번 index에 매핑되기 희망하므로 Lookup table의 해당 index를 탐색합니다. 살펴본 결과, 해당 index 값이 -1 이므로 선택될 수 있습니다. 따라서 Lookup table의 0번 index를 Host 1번의 값인 1로 갱신합니다. 또한 Next 배열에서 다음 값을 참조하기 위해서 1증가한 값으로 갱신합니다.
Step 4.

그 다음은 Host 2번이 Lookup table에 매핑될 차례입니다. 이전과 마찬가지로 Next 배열에서 해당 Host의 Permutation table 참조 index가 0번이므로 0번을 살펴봅니다. 이때 Host 2는 Lookup table에서 3번 위치에 매핑되기를 희망합니다. 따라서 Lookup table이 3번 index를 살펴봅니다.
하지만 Host 0번에 기존에 선점하였기 때문에, 해당 index에 Host 2를 매핑할 수는 없습니다. 따라서 다른 Lookup table 위치를 탐색해야합니다.

이 경우에는 Permutation table의 다음 index 참조를 위해 먼저 Next 배열에 저장된 값을 1증가시킵니다. 이후 Permutation table에서 증가된 index 위치를 탐색합니다. 결과를 살펴보면, 두 번째로 선호하는 자리가 4번 index이기 때문에 Lookup table에서 해당 index를 탐색합니다. 살펴본 결과 해당 값은 -1이기 때문에 선점이 가능합니다. 따라서 Lookup table의 4번 index는 Host 2에게 배정합니다.
만약 또 충돌이 발생했다면, 방금전 수행했던 절차대로 Next 배열의 값을 1 증가시키고, Permutation table의 해당 위치를 탐색하여 Lookup table에 해당하는 index 값이 -1이 나올 때까지를 반복 수행하여 매핑을 수행합니다.

Host 2의 매핑이 완료되었으면, Next 배열의 값을 1 증가 시켜, 다음 Permutation table 참조 index를 갱신합니다.
Step 5.
Host 2까지 매핑이 모두 완료되었으면, 다시 Host 0의 차례입니다. 따라서 Step 2-4 단계를 반복하면서, 개별 Host가 선호하는 Lookup table 갱신을 수행합니다. 해당 과정은 Lookup table이 완성될 때까지 반복합니다.
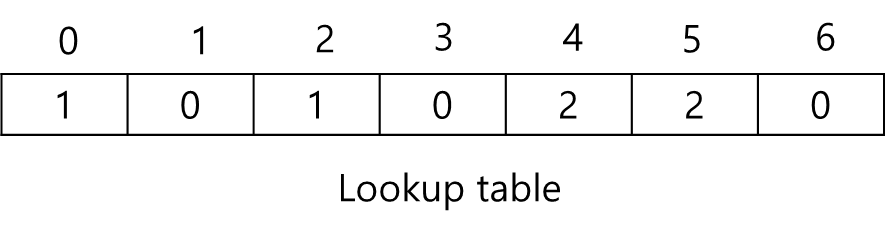
Permutatiion 과정이 모두 끝나고 나면, 위 그림과 같이 Lookup table이 완성됩니다. 완성된 결과를 살펴보면, 모든 Host가 균등하게 배분되었음을 알 수 있습니다. 이는 Permutation 단계에서 각 Host 별로 돌아가면서 Lookup table을 순차적으로 갱신했기 때문입니다.
따라서 이후 Load Balancer는 Hash 값에 대한 Modular 연산을 통해서 Host에게 부하를 분산할 수 있게됩니다.
그렇다면 Maglev 알고리즘을 사용하는 상황에서 Host의 삭제가 발생했을 경우 어떻게 될까요?
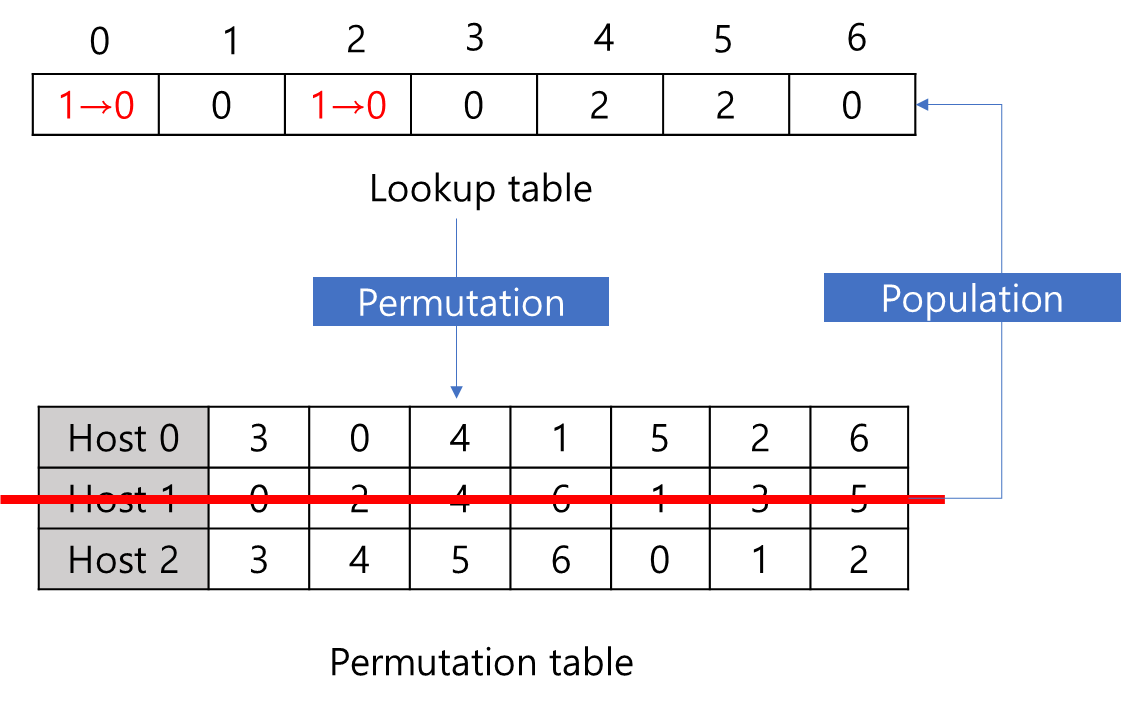
이전과 마찬가지로 Permutation 과정을 진행합니다. 하지만 Permutation을 수행해도 기존 Host가 희망하는 해시값 기반 우선순위에는 변화가 없습니다. 따라서 Host 1이 제거될 경우 기존 table에서 Host 1 데이터들만 제거되어 갱신될 뿐, 기존 Host 들이 선호하는 값은 그대로입니다.
이후 Popluation을 진행하면, 위 그림의 Lookup table과 같이 변경됩니다. 이때 유심히 볼 점은 기존 Host들이 선호했던 Lookup table의 index 변화는 없는 상태에서 Host 1이 희망했던 index에만 다른 Host로 채워졌음을 알 수 있습니다. 따라서 이는 기존의 다른 Host들에게 연결된 Connection은 그대로 유지한채 기존 Host 1에 연결된 Connection만 재연결이 필요함을 의미합니다. 따라서 안정성을 확보할 수 있는 장점이 존재합니다.
지금까지 Maglev 방식에 대해서 살펴봤습니다. envoy에서는 다음과 같이 lb_policy를 maglev로 지정함으로써 해당 알고리즘을 사용할 수 있습니다.
static_resources:
clusters:
- name: my_service
connect_timeout: 0.25s
type: strict_dns
lb_policy: maglev
maglev_lb_config:
table_size: 65536
load_assignment:
cluster_name: my_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8080
load_balancing_weight: 2
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8081
load_balancing_weight: 1
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8082
load_balancing_weight: 3
이때 위와 같이 maglev_lb_config를 통해 Lookup table의 크기를 변경할 수 있습니다. 참고로 Lookup table의 크기를 키우면 키울 수록 Host Down에 대한 Connection 재분배에 대한 영향도를 줄일 수 있으며, envoy에서는 기본값이 65536이고 최대 5000011개로 지정할 수 있습니다.
이때 Lookup table 사이즈를 키우게되면, Connection 재분배 비율은 줄일 수 있으나 Memory를 그만큼 사용하며, Population에 드는 시간이 증가하므로 마찬가지로 적절한 PoC를 통해서 적정 값을 도출하는 것이 좋습니다.
지금까지 Maglev에 대해서 살펴봤는데요. Maglev는 Consistent Hashing 방식에 비해 어떤 이점을 가지고 있을까요?
1. Traffic Balancing
Maglev의 경우는 ECMP(Equal-Cost Multipath) 라우팅을 추구합니다. Lookup table을 구성할 때 모든 Host가 동등한 비율로 배분하여 Traffic 전달 시에 보다 균등하게 부하를 분산할 수 있도록 추가합니다.
2. 단순한 설정
Maglev의 경우는 Virtual Node를 생성하지 않습니다. Consistent Hasing 방식의 경우는 Virtual Node 생성을 위한 여러 기타 설정이나 균등하게 부하를 분산하기 위해 기타 Hashing 파라미터를 조정해야할 수 있지만 Maglev는 Table 사이즈를 조정하는 정도를 통해서 목표를 달성할 수 있습니다.
하지만 Maglev를 사용하기 위해서는 Permutation Table, Lookup table, Next 등 다양한 자료구조가 사용되며, Host 생성/추가 발생 시에 Permutation과 Popluation 작업이 지속 발생되기 때문에 상대적으로 높은 메모리와 CPU 비용이 요구됩니다. 따라서 무조건 Maglev 방식이 좋다고 말할 수는 없으며, 언제나 비즈니스 상황과 인프라 환경에 맞추어 테스트 후 적절한 방법을 사용하는 것이 좋다고 볼 수 있습니다.
8. 마치며
지금까지 envoy에서 제공하는 다양한 Load Balancing 알고리즘 방법에 대해서 살펴봤습니다. 업무 환경에 적용할 때는 비즈니스 환경의 규모 및 성능을 고려하여 적절한 Load Balancing 전략을 차용하는 것이 중요합니다. 따라서 각각의 알고리즘이 어떻게 동작하며, 어떠한 특징이 있는지 잘 이해하고 있는 것이 무엇보다 중요하다고 볼 수 있겠습니다.
'MSA > Istio' 카테고리의 다른 글
| 6. [envoy-internals] Http Connection Manager (0) | 2023.05.24 |
|---|---|
| 5. [envoy-internals] Listener Manager (0) | 2023.05.23 |
| 3. [envoy-internals] Cluster Manager - 역할 (1) | 2023.05.18 |
| 2. [envoy-internals] 쓰레딩 모델과 데이터 공유 (0) | 2023.05.17 |
| 1. [envoy-internals] 아키텍처 Overview (1) | 2023.05.17 |