서론
지난 포스팅에서는 gRPC에서 사용되는 protobuf와 REST 통신에서 사용되는 JSON 크기와 Serialization/Deserialization 관점에서 성능을 비교해봤습니다. 이번에는 gRPC에서 제공하는 통신 방법에 대해서 살펴보고 REST 단건 통신과 비교하여 송/수신 시간을 비교해보겠습니다.
1. gRPC 통신 방법
gRPC는 HTTP 2.0을 기반으로 구성되어있기 때문에 Multiplexing으로 연결을 구성할 수 있습니다. 따라서 단일 Connection으로 순서의 상관없이 여러 응답을 전달받을 수 있는 Streaming 처리가 가능합니다. gRPC는 총 4가지의 통신 방법을 지원하며 그 중 3가지 방식은 Streaming 처리 방식입니다. 지금부터 하나씩 살펴보겠습니다.
2. Unary
첫 번째 방식은 Unary 통신 방식입니다.

이는 가장 단순한 서비스 형태로써 클라이언트가 단일 요청 메시지를 보내고 서버는 이에 단일 응답을 내려보내주는 방식입니다. 일반적으로 사용하는 REST API를 통해 주고 받는 Stateless 방식과 동일하다고 볼 수 있으며, 개념적으로 이해하기 쉽습니다.
그렇다면 gRPC의 Unary 통신과 REST의 성능을 비교해보면 어떤차이를 보일까요? 테스트 시나리오를 기반으로 두 통신방법을 비교해보록 하겠습니다.
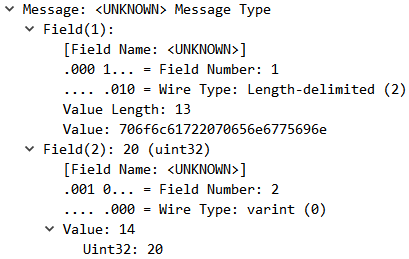
| 1. 사용자를 등록하는 서비스가 있다고 가정한다. 2. 10, 100 등 10만까지 10의 거듭 제곱 형태로 delay없이 요청 횟수를 늘리면서 REST와 gRPC의 응답 총 시간을 구한다. 3. 테스트 시작전 warm up을 위해 50회의 요청 수행 후 테스트를 진행한다. |
위 시나리오를 기반으로 Unary 통신을 구현해보겠습니다.
syntax = "proto3";
import "google/protobuf/empty.proto";
option java_multiple_files = true;
option java_package = "grpc.polar.penguin";
message Address{
string city = 1;
string zip_code = 2;
}
message Person{
string name = 2;
int32 age = 3;
repeated string hobbies = 4;
optional Address address = 5;
}
service PersonService {
rpc register(Person) returns (google.protobuf.Empty);
}
Protobuf는 위와 같이 디자인했습니다. message 포맷은 이전 포스팅에서 설계 내용과 동일합니다. 여기서 새로 추가된 항목은 service 부분입니다. 추가된 내용을 살펴보면 인자로 Person 타입을 입력받고 반환 값은 없으므로 Empty를 지정하였습니다.
이번 포스팅 내용은 통신 방법에 대한 설명이므로 syntax 설명은 향후 다른 포스팅 내용으로 다루겠습니다.
class PersonGrpcService : PersonServiceGrpcKt.PersonServiceCoroutineImplBase() {
override suspend fun register(request: Person): Empty {
//TODO : request 처리
return Empty.getDefaultInstance()
}
}
Proto 파일 디자인 후 Build하면 Stub 클래스가 자동 생성됩니다. 위 코드는 gRPC 서비스 처리를 구현하기 위해 Stub 클래스인 PersonServiceCoroutineImplBase을 상속받아 구현한 코드입니다. 테스트 시나리오에서는 전달받은 Person 객체를 따로 저장하거나 처리하지 않고 Empty 객체를 반환하도록 구현하였습니다.
fun main() {
val server = ServerBuilder.forPort(6565)
.addService(PersonGrpcService())
.build()
server.start()
server.awaitTermination()
}
Server 기동 시에 Service를 등록 시켜서 Client의 요청이 들어왔을 경우에 해당 Service로 Routing 하도록 설정합니다. 이후 Server를 기동합니다.
fun main() {
val channel = ManagedChannelBuilder.forAddress("localhost", 6565)
.usePlaintext()
.build()
val stub = PersonServiceGrpc.newBlockingStub(channel)
execute(stub, 50) //warm up phase
val base = 10.0
val dec = DecimalFormat("#,###")
for (exponent in 1..5) {
val iterCount = base.pow(exponent).toInt()
val time = measureTimeMillis {
execute(stub, iterCount)
println("count : ${dec.format(iterCount)}")
}
println("elapsed time $time ms")
println("------------------------------------")
}
channel.shutdown()
}
Unary 테스트를 위한 client 코드는 위와같습니다. Server를 localhost의 6565 포트에서 기동중이므로 해당 요청에 대한 Channel을 생성합니다.
이후 proto 파일 Build 과정에서 생성된 PersonServiceGrpc 내에 있는 BlockingStub 객체를 생성 해서 해당 Channel에 Binding 합니다. Channel에 Binding 한 다음에는 Stub 객체의 메소드를 호출하면 Server와 통신을 수행할 수 있습니다.
stub 객체까지 만들고 나면, 10 ~ 10만번까지 10의 거듭제곱 형태로 늘려가면서 gRPC Unary 통신을 수행 후 총 수행 시간을 출력합니다.
위 코드에서 실질적으로 gRPC를 호출하는 부분은 execute 함수입니다.
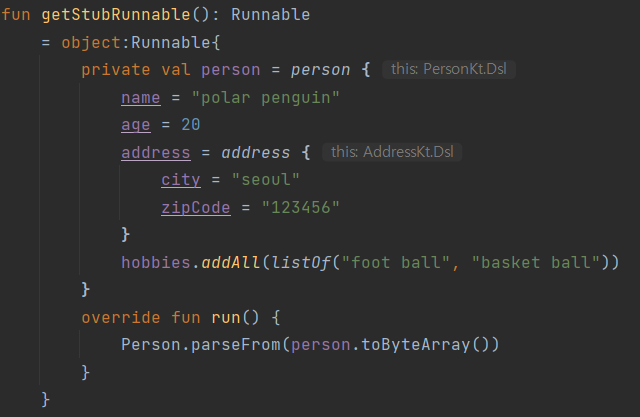
fun execute(stub: PersonServiceGrpc.PersonServiceBlockingStub, count: Int) {
repeat(IntRange(1, count).count()) {
stub.register(
person {
name = "kevin"
age = (1..50).random()
address = address {
city = "seoul"
zipCode = "123456"
}
hobbies.addAll(listOf("foot ball", "basket ball"))
}
)
}
}
execute 함수를 살펴보면 위와 같이 iteration count를 인자로 전달받고 그 횟수만큼 gRPC 요청을 보내는 것을 확인할 수 있습니다.
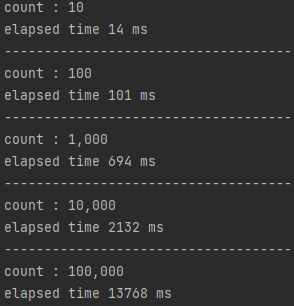
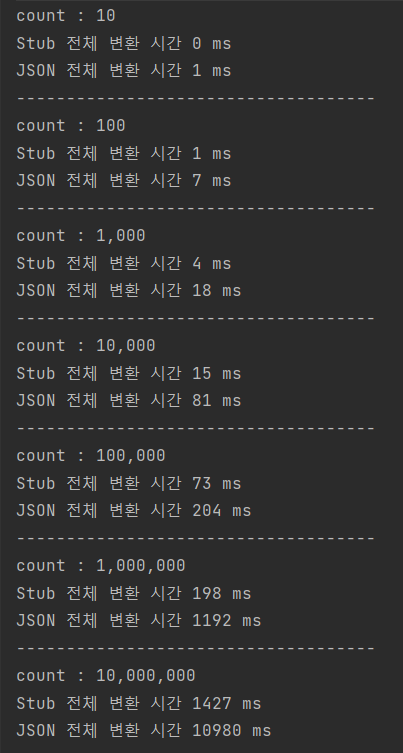
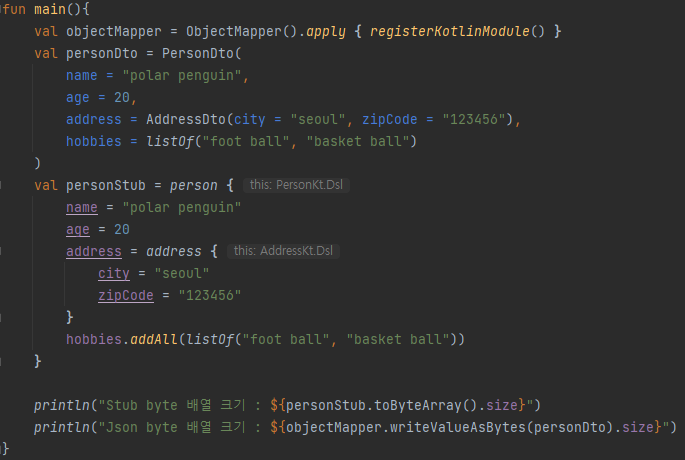
프로그램을 실행하면 위와 같이 Unary 요청 수행 결과를 확인할 수 있습니다.
이번에는 REST 통신을 통해 같은 횟수를 반복했을 때 Unary 통신과 비교하여 총 수행시간이 얼만큼의 차이가 있는지를 비교해보도록 하겠습니다. 이때 Unary 테스트 또한 단일 Channel에서 Blocking 방식으로 수행시간을 측정하였으므로 REST 통신 또한 같은 방법으로 테스트를 진행하겠습니다.
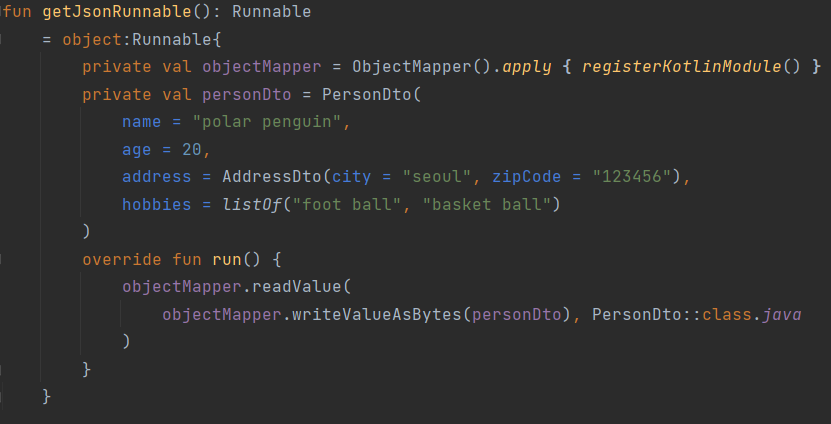
data class PersonDto(
val name : String,
val age : Int,
val hobbies : List<String>? = null,
val address : AddressDto? = null
)
data class AddressDto(
val city : String,
val zipCode : String
)
JSON으로 입력받을 DTO를 위와 같이 디자인합니다.
@RestController
class PersonController(private val service: PersonService) {
@PostMapping("/person")
suspend fun register(@RequestBody person : PersonDto) {
//TODO : request 처리
}
}
REST Controller 코드는 위와 같습니다. gRPC 서비스 코드에서도 인자를 전달받아 아무런 처리를 하지 않았기 때문에 마찬가지로 요청만 전달받고 아무 처리를 수행하지 않도록 구성하였습니다.
@Component
class RegisterTest : CommandLineRunner {
override fun run(vararg args: String?) {
val client = WebClient.builder()
.build()
execute(client, 50) // warm up phase
val base = 10.0
val dec = DecimalFormat("#,###")
for (exponent in 1..5) {
val iterCount = base.pow(exponent).toInt()
val time = measureTimeMillis {
execute(client, iterCount)
println("count : ${dec.format(iterCount)}")
}
println("elapsed time $time ms")
println("------------------------------------")
}
}
private fun execute(client: WebClient, count: Int) {
repeat(IntRange(1, count).count()) {
client.post().uri("localhost:8080/person")
.bodyValue(
PersonDto(
name = "kevin",
age = (1..50).random(),
address = AddressDto(city = "seoul", zipCode = "123456"),
hobbies = listOf("foot ball", "basket ball")
)
)
.retrieve()
.bodyToMono(Void::class.java)
.block()
}
}
}
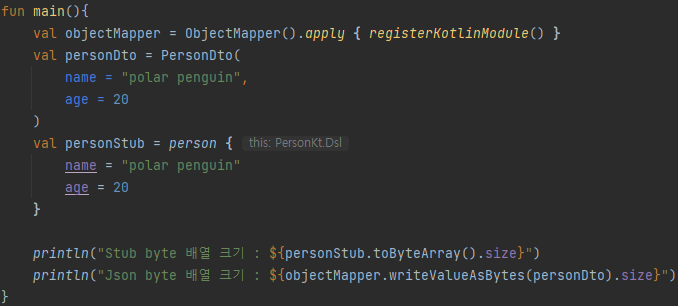
Client 수행 프로그램은 위와 같습니다. gRPC 테스트 코드와 크게 다르지 않으며, 차이점이 있다면 Stub 객체를 사용한 것이 아닌 Webclient를 사용한 부분입니다.
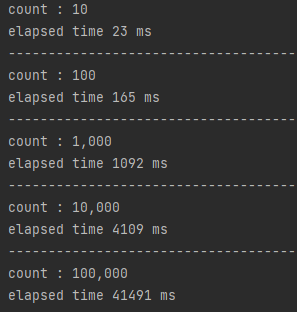
Client 코드를 수행하면 위와 같은 결과를 얻을 수 있습니다.
| 횟수 | REST | gRPC(Unary) | 성능 |
| 10 | 23 ms | 14 ms | 1.64배 |
| 100 | 165 ms | 101 ms | 1.63배 |
| 1,000 | 1,000 ms | 694 ms | 1.44배 |
| 10,000 | 4,109 ms | 2,132 ms | 1.92배 |
| 100,000 | 41,491 ms | 13,768 ms | 3.01배 |
결과를 살펴보면, Iteration 횟수가 증가할 수록 그 차이가 벌어지는 것을 확인할 수 있습니다. 격차가 벌어진 이유는 다양한 이유가 있지만 Protobuf의 Serialization & Deserialization이 가장 큰 영향을 미치지 않았을까 생각합니다.
이번에는 네트워크 패킷을 통해서 REST와 gRPC의 통신 과정을 비교 해보겠습니다. 비교를 위해서 사용자 등록을 5회만 수행 후 종료한 내용을 확인해보도록 하겠습니다.
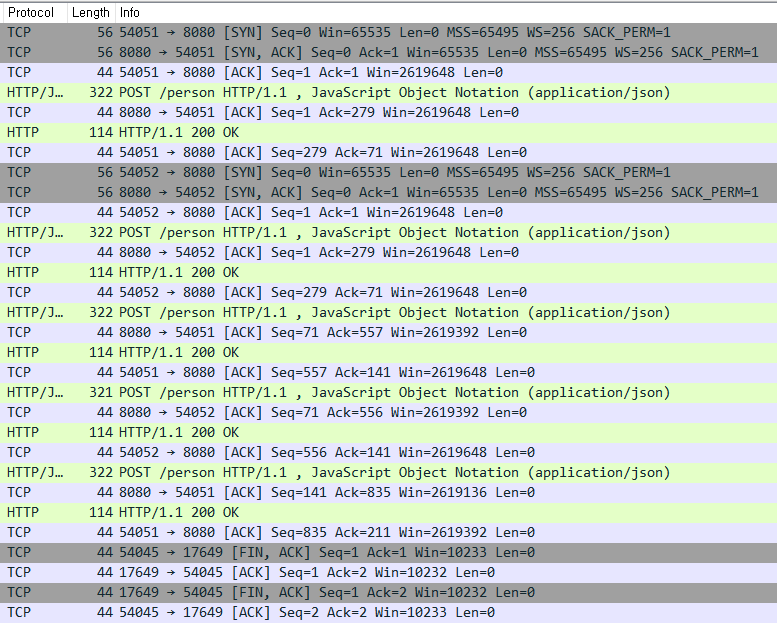
REST 통신을 5회 수행하였을 때, 네트워크 흐름을 표시하면 위 그림과 같습니다. 자세히보면 REST 통신은 HTTP 1.1을 사용한 것을 알 수 있고 SYN, ACK와 FIN, ACK가 매 요청마다 보이지 않는 것으로 보아 Connection을 매번 요청하지 않았음을 확인할 수 있습니다.
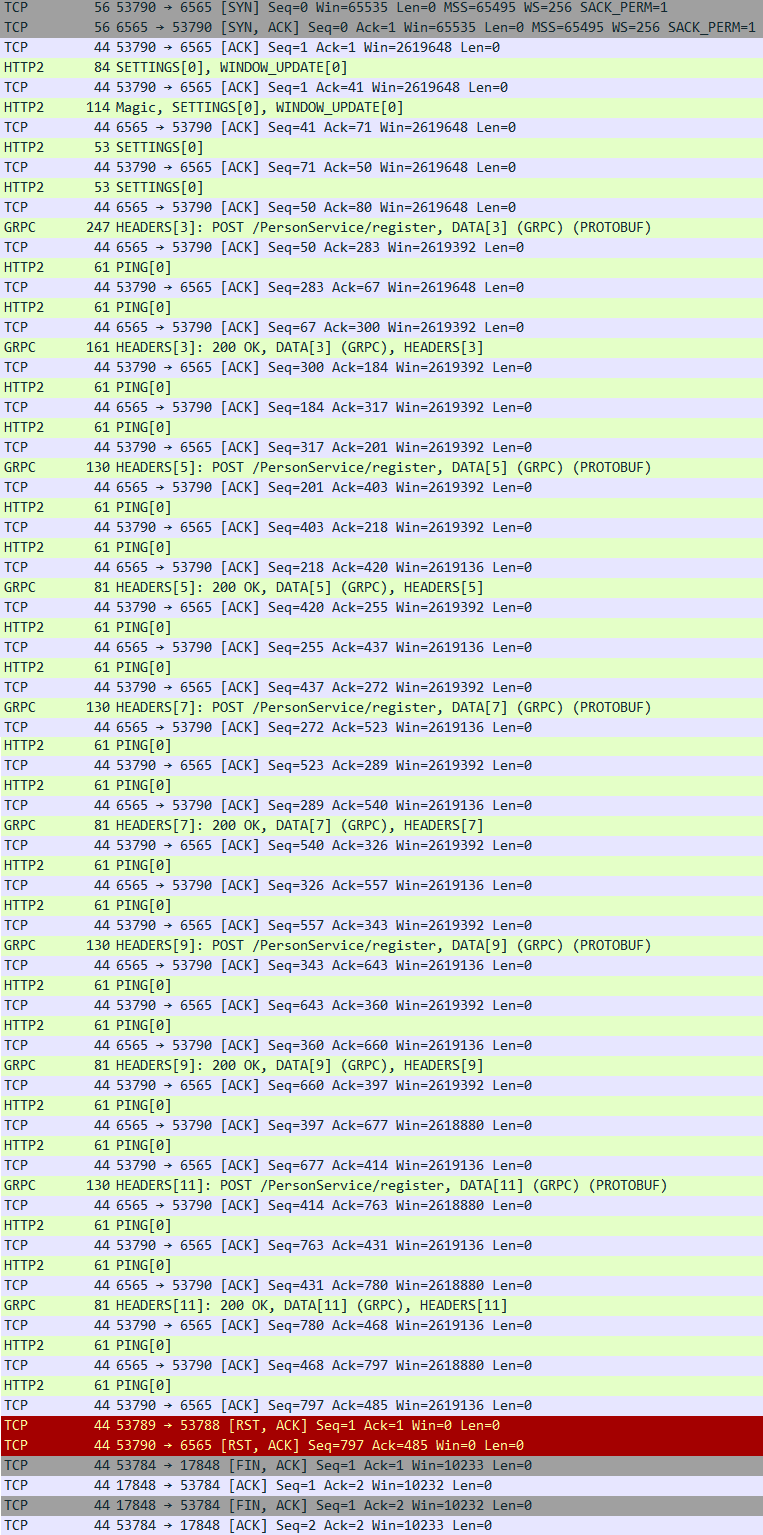
이번에는 gRPC Unary 통신 결과입니다. REST에서는 HTTP 1.1 방식이었던 것과 달리 예상대로 HTTP 2.0으로 통신을 수행한 것을 확인할 수 있습니다.
gRPC에서 Unary 통신은 HTTP 2.0 Stream으로 데이터를 전송합니다. 따라서 위 패킷 내용을 살펴보면, Stream 통신에 있어서 필요한 데이터 흐름을 파악할 수 있습니다.
가령 WINDOW_UPDATE를 통해서 Client가 수신할 수 있는 Byte 수를 Server에 알려줘 해당 정보를 기반으로 Flow control이 가능하도록 사전 설정하는 것을 확인할 수 있습니다. 또한 PING 패킷의 경우는 연결된 Channel 에서 사용중인 Connection liveness를 체크합니다. 만약 PING 단계에서 정상 응답을 수신 받지 못하면, Connection을 끊습니다. 이후 Connection 재생성을 통해 다시 연결할 수 있습니다.
이번에는 데이터 패킷을 상세하게 살펴보도록 하겠습니다.

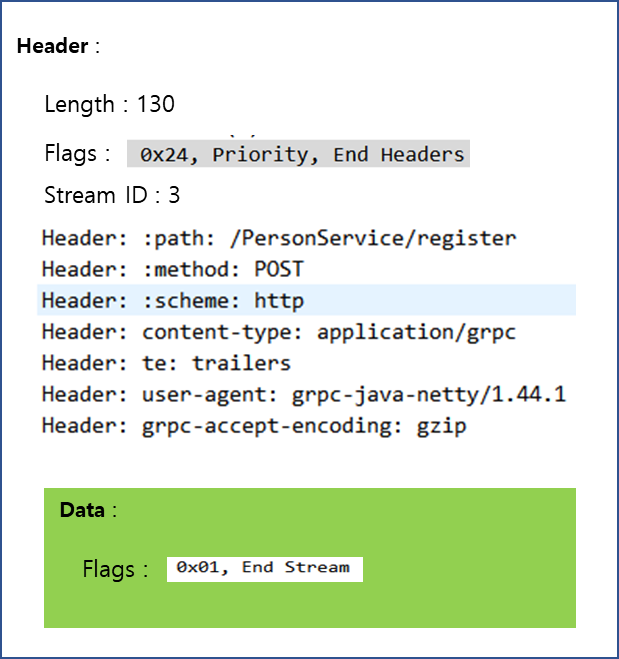
위 그림은 요청 패킷을 구조화한 모습입니다.
Header를 살펴보면, Header의 길이 그리고 Header의 종류 flag가 보입니다. 그리고 Stream ID가 표시된 것을 볼 수 있는데, 이는 HTTP Stream 내에서 사용되는 Stream 메시지 별 Unique ID 입니다. Client에서 보내는 메시지는 Stream ID가 홀수개로 증가합니다.
Header에는 그 밖에 요청 Path 정보 및 Schema, Content-type이 표시됩니다. 내부적으로 요청은 POST로 요청되는 것을 확인할 수 있습니다.
Data 영역에는 실제 전달되는 데이터와 Flag등을 전달합니다. Unary 통신의 경우 gRPC Stream 요청은 아니므로 Flag에는 End Stream으로 지정된 것을 확인할 수 있습니다.


응답 패킷은 크게 3가지 부분으로 이루어져있습니다. 첫번째는 요청에 대한 응답헤더이고, 두 번째는 응답에 대한 데이터 마지막으로는 trailer 헤더로 구성되어있습니다.
그렇다면 위 5개의 데이터 전송 흐름에서 gRPC 패킷은 어떤 특징을 지니고 있을까요?

요청 패킷을 살펴보면, Header 길이가 최초 메시지를 보낼 때보다 크기가 줄어든 것을 확인할 수 있습니다. 또한 Stream ID는 홀수 번호로 순차 증가한 것을 확인할 수 있습니다.

마찬가지로 응답 패킷을 살펴보면, 최초 응답 헤더에 비해 이후 응답 메시지의 Header 크기가 줄어든 것을 확인할 수 있습니다.
위와 같이 gRPC는 기반에 HTTP 2.0을 기반으로 하여 메시지 전송간 데이터 Payload가 줄어드는 장점이 존재하기 때문에 이전 REST 방식에 통신에 있어서 조금 더 빠른 결과를 나타낼 수 있습니다.
3. Streaming
이번에는 Streaming 처리 방법에 대해서 살펴보도록 하겠습니다. Stream은 데이터를 한번만 전송하는 것이 아니라 연속적인 흐름으로 전달하는 것을 의미합니다.
gRPC에서는 총 3가지 종류의 Streaming이 존재합니다.
1) Client Stream
Client는 Stream 형태로 전달하고 Client의 요청이 끝나면 Server에서 한번에 응답을 내려주는 경우는 Client Stream이라고 부릅니다.
2) Server Stream
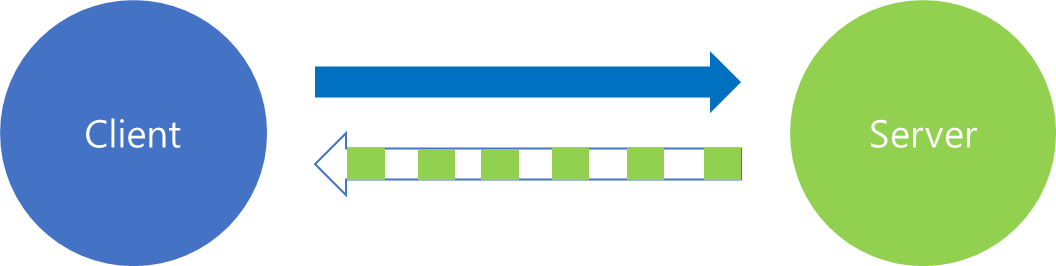
Client의 요청은 한번만 전달하고 Server에서 응답은 여러 번에 걸쳐 전송하는 경우는 Server Stream이라고 부릅니다.
3) Bidirectional Stream
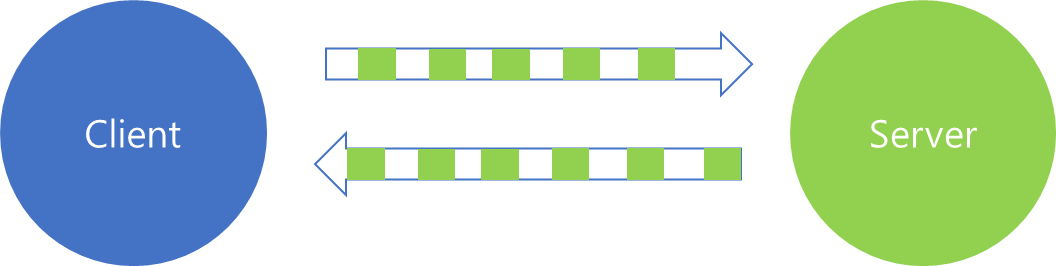
양방향 모두 Stream으로 데이터를 전송하는 경우는 Bidirectional Stream 이라고 부릅니다.
Stream 처리 방법은 개념적으로 어렵지 않고 이번 포스팅에서는 사용 방법 보다는 성능 비교가 주 목적이므로 모든 Stream 방식에 대한 구현을 다루지는 않겠습니다.
Stream 처리 관련해서 다루어볼 내용은 Client Stream 방식을 활용해서 Unary, REST 방식의 테스트 시나리오를 동일하게 적용하여 어떤 차이점이 있는지를 살펴보도록 하겠습니다.
...(중략)...
service PersonService {
...(중략)...
rpc registerBatch(stream Person) returns (google.protobuf.Empty);
}
먼저 Stream 처리를 위해 서비스에 RPC를 등록합니다. 이후 Build를 수행합니다.
class PersonGrpcService : PersonServiceGrpcKt.PersonServiceCoroutineImplBase() {
...(중략)...
override suspend fun registerBatch(requests: Flow<Person>): Empty {
val start = System.currentTimeMillis()
requests
.catch {
//TODO : Error 처리
}
.onCompletion {
println("${System.currentTimeMillis() - start} ms elapsed. ")
}
.collect {
//TODO : request 처리
}
return Empty.getDefaultInstance()
}
}
Build 이후 해당 Stub 메소드 구현을 위해서 PersonServiceCoroutineImplBase Stub 클래스에서 RPC 관련 메소드를 override 합니다. 이때 Stream으로 전달받은 데이터를 기반으로 비즈니스 로직 처리는 수행하지 않기 때문에 collect 부분은 아무런 작업을 수행하지 않도록 구성했습니다.
fun main() {
val channel = ManagedChannelBuilder.forAddress("localhost", 6565)
.usePlaintext()
.build()
val stub = PersonServiceGrpcKt.PersonServiceCoroutineStub(channel)
runBlocking { execute(stub, 50) } // warm up phase
val base = 10.0
val dec = DecimalFormat("#,###")
runBlocking {
for (exponent in 1..5) {
val iterCount = base.pow(exponent).toInt()
val time = measureTimeMillis {
execute(stub, iterCount)
println("count : ${dec.format(iterCount)}")
}
println("elapsed time $time ms")
println("------------------------------------")
}
}
}
suspend fun execute(stub: PersonServiceGrpcKt.PersonServiceCoroutineStub, count: Int) {
try {
stub.registerBatch(
IntRange(1, count)
.map {
person {
name = "kevin"
age = (1..50).random()
address = address {
city = "seoul"
zipCode = "123456"
}
hobbies.addAll(listOf("foot ball", "basket ball"))
}
}
.asFlow()
)
} catch (e: StatusException) {
println(e)
}
}
Client 프로그램은 위와 같이 구성했습니다. gRPC의 Stream 처리를 구현하기 위해서 StreamObserver를 활용해서 구현하는 방식과 Kotlin의 Coroutine 방식 두 가지 방식으로 구현 가능한데, 위 코드는 Coroutine 방식으로 구현하였습니다.
내용을 살펴보면 이전 Unary 코드와 크게 다르지는 않으며, 데이터 전달시 Flow로 변환하여 전달하는 것을 확인할 수 있습니다.
코드 구현이 완료되었으면 실행 후 결과를 비교해보겠습니다.
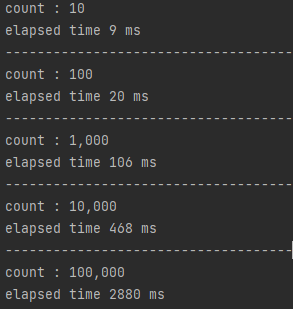
실행 결과를 살펴보면, REST와 gRPC(Unary)와 비교했을 때 엄청난 개선이 이루어진 것을 확인할 수 있습니다.
이를 표로 나타내면 다음과 같습니다.
| 횟수 | REST | gRPC(Unary) | gRPC(Client Stream) |
| 10 | 23 ms | 14 ms | 9 ms |
| 100 | 165 ms | 101 ms | 20 ms |
| 1,000 | 1,000 ms | 694 ms | 106 ms |
| 10,000 | 4,109 ms | 2,132 ms | 468 ms |
| 100,000 | 41,491 ms | 13,768 ms | 2,880 ms |
요청 횟수가 적을 때보다 횟수가 늘어감에 따라 차이가 더 커지는 것을 확인할 수 있습니다. 가령 10만번 데이터 전송의 경우 REST 방식보다 14.4배 Unary 방식에 비교하면 4.78배 효율이 좋은 것을 확인할 수 있습니다.
그렇다면 Stream 처리 방식은 왜 이리 많은 차이를 보이는 것일까요? 이전과 마찬가지로 패킷의 흐름을 살펴보겠습니다.
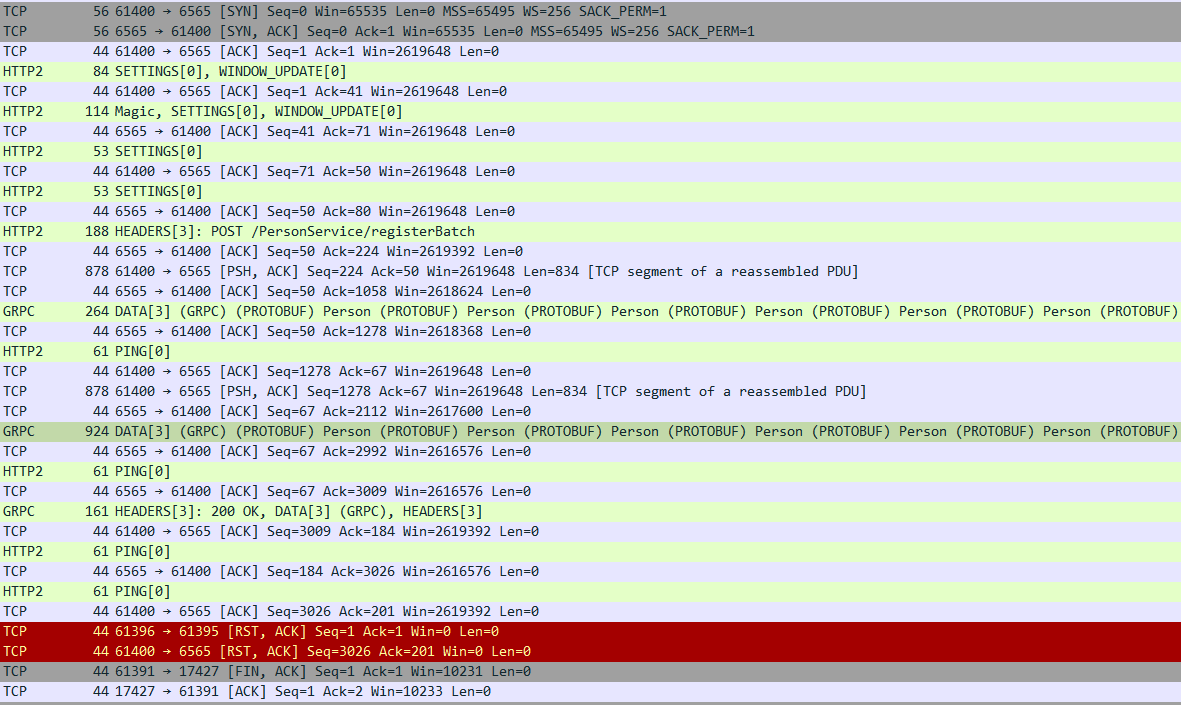
위 내용은 Stream 형식으로 Person 데이터를 50회 전송했을 때 네트워크 흐름입니다.
Unary와 REST 방식은 5회만 전송했는데도 많은 Network 요청이 있었던 것과 비교하여 50회 데이터를 전송했는데도 패킷의 횟수가 그리 많지 않습니다.
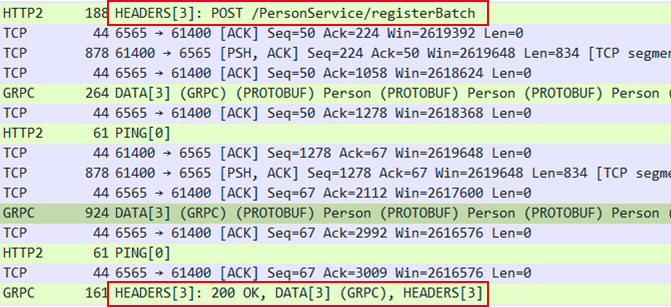
데이터 전송 부분만 살펴보면, 요청을 전달할 때 Header는 한번만 전송한 것을 확인할 수 있고, 응답 또한 한번만 전달받은 것을 확인할 수 있습니다.
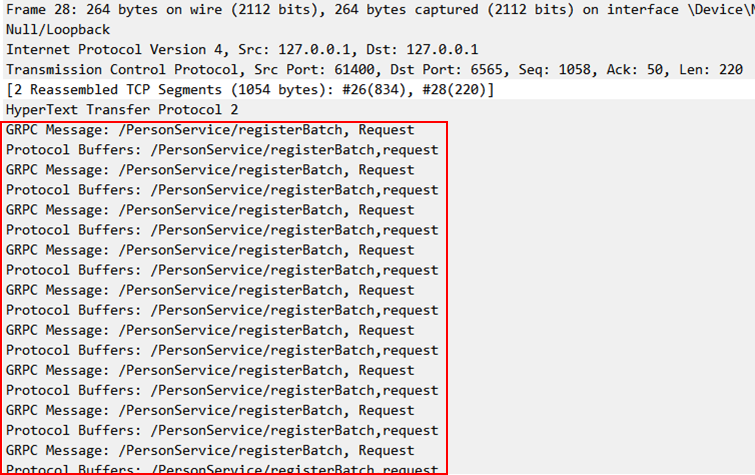
그리고 데이터는 여러번 전달한 것이 아니라 한 Packet안에 여러개의 요청이 포함되어 전달된 것을 확인할 수 있습니다.
위 패킷 흐름에는 총 2번 전달하는 과정에서 50개의 요청이 담겨있는 것을 확인할 수 있습니다.
한번에 동일 요청 다수를 함께 전달할 경우, Stream 방식이 매번 요청을 수행하는 Unary 방법보다 효율적인 데이터 전송이 가능합니다. 따라서 네트워크 전달 과정에서 많은 비용을 감소하여 성능이 더욱 좋다고 볼 수 있습니다.
4. 마치며
지난 포스팅과 이번 포스팅을 통해서 gRPC의 성능 이점에 대해서 다양한 각도로 살펴봤습니다. 다음 포스팅부터는 gRPC를 사용하는 방법에 대해서 차차 알아보도록 하겠습니다.
'MSA > gRPC' 카테고리의 다른 글
| 4. kotlin 환경에서 gRPC 설정하기 (0) | 2022.03.10 |
|---|---|
| 2. gRPC는 왜 빠를까? (Payload) - 1 (1) | 2022.03.10 |
| 1. gRPC 개요 (0) | 2022.03.05 |