서론
Excel Upload 기능이 필요하여 많이쓰는 POI 라이브러리를 살펴보았으나, 2가지 아쉬운점이 있었습니다.
1. 비즈니스 로직과 POI 라이브러리 코드의 강결합
2. DOM과 SAX 방식은 코드 작성 방법이 달라 둘 다 쓰는데 있어 유지보수의 어려움
DOM 방식
try {
Workbook workbook = WorkbookFactory.create(file.getInputStream());
Sheet sheet = workbook.getSheetAt(0);
for(int i = 0 ; i < sheet.getPhysicalNumberOfRows() ; i++){
final Row row = sheet.getRow(i);
for(int j = 0; j < row.getPhysicalNumberOfCells(); j++){
final Cell cell = row.getCell(j);
//Business Code
}
}
} catch (IOException e) {
e.printStackTrace();
}
SAX 방식
try {
OPCPackage pkg = OPCPackage.open(file.getInputStream());
XSSFReader r = new XSSFReader(pkg);
SharedStringsTable sst = r.getSharedStringsTable();
StylesTable styles = r.getStylesTable();
XMLReader parser = XMLHelper.newXMLReader();
SAXSheetHandler sheetHandler = //사용자가 정의한 SAXSheetHandler(? extends DefaultHandler)
ContentHandler handler = new XSSFSheetXMLHandler(styles, sst, sheetHandler, false);
SAXRowHandler rowHandler = new SAXRowHandler();
parser.setContentHandler(handler);
try (InputStream sheet = r.getSheetsData().next()) {
parser.parse(new InputSource(sheet));
}
}
catch (Exception e) {
e.printStackTrace();
}
이러한 문제를 어떻게 해결할 수 있을까 고민하던 와중 우아한 형제들 Excel 기술 블로그를 보고 영감을 얻어 Excel 업로드 라이브러리를 개발하기로 했습니다. 이번 포스팅은 개인 프로젝트로 진행한 라이브러리 설계 과정과 적용 기술 및 개발 당시 어려움을 겪은 내용을 다루겠습니다.
라이브러리 사용법 및 공식 문서는 Github 및 Wiki 페이지를 참고하시기 바랍니다.
개발 과정
먼저 개발에 앞서 필요 기능을 리스트업 했습니다.
1. DOM과 SAX 방법에 대한 추상화된 API를 제공해야한다.
2. Streaming 방식과 Collection 방식을 제공해야한다.
3. 사용자 코드에서 POI 코드가 직접적으로 의존되지 않아야한다.
4. 학습비용이 낮아야한다.
5. 다국어 처리를 지원해야한다.
6. Validation 기능을 제공해야한다.
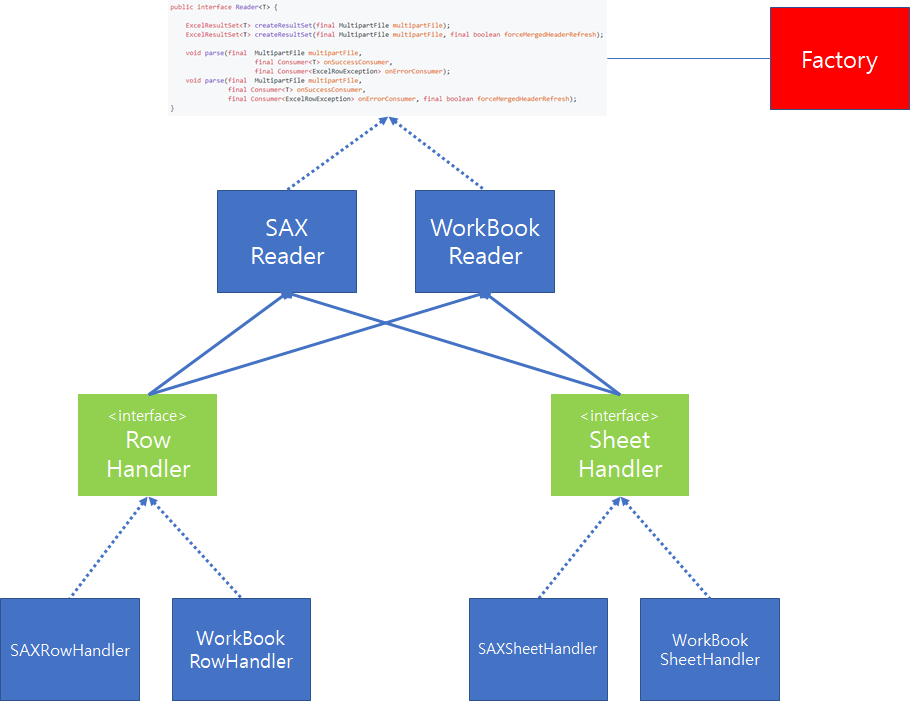
1. DOM 과 SAX 방식에 대한 공통 API 구현
POI에서 제공하는 DOM과 SAX 방식은 구현 방법이 완전히 다릅니다. 그 이유는 제공하는 API도 다를 뿐더러 DOM 방식은 Pull 방식, SAX 방식은 Push 방식으로 Parsing 결과를 제공하기 때문입니다.
따라서, 먼저 이러한 두 가지 방법에 대해서 공통으로 처리할 수 있는 API를 설계하고 이를 Interface 제공하도록 구상하였습니다.

위와 같이 interface를 정의하면 사용자는 구현의 Detail은 알 필요없이 API 호출만으로 SAX 방식 혹은 DOM 방식으로 결과를 얻을 수 있습니다.

두번째는 Excel 파일에서 데이터를 Parsing하기 위해서는 Sheet에 대한 처리, 각각의 Row에 대한 처리가 필요합니다. 따라서, 이전과 마찬가지로 Row와 Sheet에 대한 각각의 inteface를 정의한 다음 각각의 Reader는 interface에 의존함으로써, 공통화된 기능을 제공할 수 있도록 설계했습니다.
public class ReaderFactory {
private final ExcelMetaModelMappingContext context;
public ReaderFactory(ExcelMetaModelMappingContext context) {
this.context = context;
}
public <T> Reader<T> createInstance(ReaderType type, Class<T> tClass) {
final boolean isCached = context.hasMetaModel(tClass);
if (type == ReaderType.WORKBOOK) {
return isCached ? new WorkBookReader<>(tClass, context.getMetaModel(tClass)) : new WorkBookReader<>(tClass);
}
return isCached ? new SAXReader<>(tClass, context.getMetaModel(tClass)) : new SAXReader<>(tClass);
}
public <T> Reader<T> createInstance(Class<T> tClass){
final ExcelBody entity = tClass.getAnnotation(ExcelBody.class);
return createInstance(entity.type(), tClass);
}
}
여기에, Factory 클래스를 추가하여 사용자가 Enum 값으로 SAX 혹은 DOM(WorkBook) 방식 중 하나를 지정하면, 그에 해당하는 Excel Reader를 생성하도록 추가하였습니다. 지금까지 설명한 내용을 도식화하면 위 그림과 같습니다.
2. Annotation 기반 메타 정보 작성
Excel로 읽는 각 Row 데이터는 결국 특정 Entity로 변환되어 DB에 저장되거나 비즈니스 로직에서 사용될 것입니다. 이러한 Entity를 POJO스럽게 유지하면서도 라이브러리에서 필요한 다양한 메타 정보를 기록할 수 있는 방법 중 하나는 @Annotation 활용입니다. Spring 환경에서 개발하면, 다양한 Annotation을 접하게 되는데, 라이브러리를 개발함에 있어서도 이러한 Annotation을 사용하여 Entity 클래스내에 라이브러리 코드가 직접 침투되지 않도록 설계하였습니다.
또한, Annotation을 사용함에 있어 JPA와 유사한 스타일을 적용하면, 학습곡선을 많이 낮출 수 있다고 생각하여 비슷하게 디자인했습니다.
@ExcelBody(dataRowPos = 3,
type = ReaderType.SAX,
headerRowRange = @RowRange(start = 1, end = 2),
messageSource = PersonMessageConverter.class)
@ExcelBody(dataRowPos = 2)
@ExcelMetaCachePut
@ExcelColumnOverrides({
@ExcelColumnOverride(headerName = "생성일", index = 8, column = @ExcelColumn(headerName = "생성일자")),
@ExcelColumnOverride(headerName = "수정일", index = 10, column = @ExcelColumn(headerName = "수정일자"))
})
public class Person extends BaseAuditEntity{
@ExcelColumn(headerName = "이름")
@NotNull
private String name;
@Merge(headerName = "전화번호")
@ExcelColumnOverrides(@ExcelColumnOverride(headerName = "집전화번호", index = 5, column = @ExcelColumn(headerName = "휴대전화번호", index = 4)))
private Phone phone;
@ExcelEmbedded
private Address address;
@ExcelColumn(headerName = "생성일자")
@DateTimeFormat(pattern = "yyyyMMdd")
private LocalDate createdAt;
@ExcelColumn(headerName = "성별")
@ExcelConvert(converter = GenderConverter.class)
private Gender gender;
}
결과적으로 위와 같이 Entity내 라이브러리 코드 작성 없이 메타 Annotation을 작성하게되면, 라이브러리 코드내에서 해당 Annotation 정보들을 참조하여 Entity 생성 및 데이터를 주입할 수 있도록 하였습니다.
(사용법은 Excel-Parser Wiki 페이지를 참고하시기 바랍니다)
3. Reflection 활용
사용자 코드에서 무엇을(What) 처리 해야할지 명시하고 어떻게(How) 처리해야할지는 기술하지 않았습니다. 즉 원하는 바만 선언하였으니, 라이브러리내에서 메타 정보를 읽어들여 사용자가 원하는대로 처리하고 반환 해야합니다.
Java에서는 Runtime 시점에 Reflection을 통해서 Instance 및 Class의 내부 정보를 알 수 있는 방법을 제공합니다. 따라서 이를 활용해서 라이브러리 내부에서 Annotation 분석 → 데이터 Parsing → Entity 생성 → 데이터 주입 → 데이터 Validation 검증 과정 순서대로 처리할 수 있도록 구상하였습니다.

위 4가지 단계에서 데이터 Parsing은 SAX Reader, WorkBook Reader가 담당하는 것을 이전 내용을 통해 확인했습니다.
따라서, Annotation 분석과, Entity 생성을 위해 이를 담당할 Class를 추가로 생성하였습니다.
ExcelEntityParser와 EntityInstantiator는 Reflection을 활용하여, Entity 내부를 탐색하는 과정을 담당합니다. Parser는 이 과정에서 Entity에 작성된 Annotation의 유효성 검증 및 헤더 정보 등을 취합하는 역할을 담당하고, Instantiator는 Entity를 생성하고, Parser에서 취합된 헤더 정보를 토대로 데이터를 주입하는 역할을 담당합니다.
public class ExcelEntityParser implements EntityParser {
...(중략)...
private void doParse() {
visited.add(tClass);
findAllFields(tClass);
final int annotatedFieldHeight = extractHeaderNames();
calcHeaderRange(annotatedFieldHeight);
validateHeaderRange();
calcDataRowRange();
validateOverlappedRange();
extractOrder();
validateOrder();
validateHeaderNames();
}
...(중략)...
private void findAllFields(final Class<?> tClass) {
ReflectionUtils.doWithFields(tClass, field -> {
final Class<?> clazz = field.getType();
if(field.isAnnotationPresent(ExcelConvert.class)){
final Class<?> converterType = field.getAnnotation(ExcelConvert.class).converter();
if(!converterType.getSuperclass().isAssignableFrom(ExcelColumnConverter.class)){
throw new InvalidHeaderException(String.format("Only ExcelColumnConverter is allowded. Entity : %s Converter: %s",this.tClass.getName(), converterType.getName()));
}
}
else if(instantiatorSource.isSupportedDateType(clazz) && !field.isAnnotationPresent(DateTimeFormat.class)){
throw new InvalidHeaderException(String.format("Date Type must be placed @DateTimeFormat Annotation. Entity : %s Field : %s ", this.tClass.getName(), clazz.getName()));
}
else if(!instantiatorSource.isSupportedInjectionClass(clazz) && visited.contains(clazz)){
throw new UnsatisfiedDependencyException(String.format("Unsatisfied dependency expressed between class '%s' and '%s'", tClass.getName(), clazz.getName()));
}
if (instantiatorSource.isSupportedInjectionClass(clazz)) {
declaredFields.add(field);
} else {
visited.add(clazz);
findAllFields(clazz);
visited.remove(clazz);
}
});
}
...(중략)...
}
public class EntityInstantiator<T> {
...(중략)...
public <R> EntityInjectionResult<T> createInstance(Class<? extends T> clazz, List<String> excelHeaderNames, ExcelMetaModel excelMetaModel, RowHandler<R> rowHandler) {
resourceCleanUp();
final T object = BeanUtils.instantiateClass(clazz);
ReflectionUtils.doWithFields(clazz, f -> {
if (!excelMetaModel.isPartialParseOperation()) {
instantiateFullInjectionObject(object, excelHeaderNames, excelMetaModel, f, rowHandler);
} else if (excelMetaModel.getInstantiatorSource().isCandidate(f)) {
instantiatePartialInjectionObject(object, excelHeaderNames, excelMetaModel, f);
}
});
if (excelMetaModel.isPartialParseOperation()) {
setupInstance(excelHeaderNames, excelMetaModel.getInstantiatorSource(), rowHandler);
}
return new EntityInjectionResult<>(object, List.copyOf(exceptions));
}
...(중략)...
private <U> void setupInstance(final List<? extends String> headers, EntitySource entitySource, final RowHandler<U> rowHandler) {
for (int i = 0; i < instances.size(); i++) {
if (Objects.isNull(instances.get(i))) continue;
Field field = instances.get(i).field;
Class<?> type = field.getType();
field.setAccessible(true);
String value = rowHandler.getValue(i);
try {
final Object instance = instances.get(i).instance;
if (!StringUtils.isEmpty(value)) {
inject(entitySource, field, type, value, instance);
}
validate(instance, headers.get(i), value, field.getName()).ifPresent(exceptions::add);
} catch (IllegalAccessException | ParseException e) {
addException(headers, field, value, e.getLocalizedMessage());
}
}
}
...(중략)...
}

Entity Parser와 Instantiator까지 적용되면, 라이브러리로 Excel Parsing 요청시, 위 흐름대로 처리되는 것을 이해할 수 있습니다.
삽질의 시작
이전 내용을 토대로 기본적인 구현을 마친 이후 테스트를 해보자 몇가지 추가 고민이 생겼습니다. 그리고 이것은 이후 시작되는 삽질의 첫삽을 푼 순간이었습니다.
고민거리
- Entity에 지정된 Annotation 유효성 검증을 런타임에 수행하는데, Spring Boot 기동시점인 로드 타임에 검증하는 것이 더 좋지 않을까?
- Maven Central에 배포해보자!!!
삽질 1. 대상 Entity 클래스 Scanning
Spring Boot 기동 시점에 검증을 하려면, Excel Parser 라이브러리의 대상 Entity를 모두 찾을 수 있어야 합니다. 따라서, Spring에서 Bean Scanning 하는 코드 및 관련 클래스를 사용해야겠다고 생각했지만 검색 능력의 부족으로 인해 찾는데 많은 어려움을 겪었습니다. 많은 시행착오 끝에 ClassPathScanningCandidateComponentProvider 클래스가 해당 기능을 제공하는 것을 확인할 수 있었습니다.
ClassPathScanningCandidateComponentProvider provider = new ClassPathScanningCandidateComponentProvider(false);
provider.findCandidateComponents("base 패키지명");
삽질 2. Default base 패키지명은 어떻게 알 수 있을까?
ClassPathScanningCandidateComponentProvider 클래스를 통해 base 패키지명을 String 타입으로 전달하면, 하위 패키지내 클래스를 탐색하는 기능을 제공해줌을 알 수 있습니다.
여기서 한가지 의문이 들었습니다.
'Spring Data JPA에서는 @EnableJpaRepositories Annotation을 통해 basePackages를 입력하지 않아도 Repository Bean을 만들 수 있었는데, 어떤 원리로 그런것일까? '
이것을 알기위해 구글링을 해봤지만, 어떠한 keyword로 검색해야할지 몰라 정확한 정보를 찾을 수 없었습니다.
(대부분 @EnableJpaRepositories 설정 방법이나 basePackage를 지정하는 방법 관련된 검색결과가 대다수였습니다.)
결국, 선택한 방법은 코드내 EnableJpaRepositories 부터 시작해서 관련된 클래스 Debugger를 걸어놓고 코드를 따라 거슬러 오르는 방법이었습니다.


추적끝에 찾은 결과는 위와 같습니다. @EnableJpaRepositories 어노테이션을 Configuration 클래스에 선언하면, JpaRepositoriesRegistrar 클래스 정보가 같이 Import 됩니다. 이때, JpaRepositoryConfigExtension 클래스가 Bean으로 등록됩니다. 그리고 RepositoryConfigurationDelegate에게 Bean 탐색을 위임합니다.

이때, basePackages를 설정하게 되는데, 사용자가 지정한 @EnableRepositories Package 정보를 가져와서 지정합니다.

JpaRepositoriesAutoConfiguration은 JpaRepository 관련 자동설정을 하는데, JpaRepositoryConfigExtension 클래스가 Bean으로 등록되어있으면, 관련 자동설정을 하지 않습니다. @EnableJpaRepositories Annotation을 사용자가 지정했다면, 이전에 설명했듯이, JpaRepositoryConfigExtension가 Bean으로 등록되었기 때문에 자동설정을 하지 않습니다.

반면 @EnableJpaRepositories Annotation이 존재하지 않는다면, 마찬가지로 RepositoryConfigurationDelegate에게 Bean 탐색을 위임합니다. 이때 사용되는 basePackges는 AutoConfigurationPackages.get 메소드를 통해 얻을 수 있습니다. 그리고 해당 메소드가 바로 Spring Boot에서 사용되는 기본 basePackges 정보임을 알 수 있었습니다.
삽질 3. JPA는 되는데 난 안돼!!!
Spring Data JPA에서 사용되는 자동설정 Idea를 토대로 개발중인 라이브러리에 적용하기로 했습니다.
@EnableExcelEntityScan Annotation과 AutoConfiguration 클래스를 만들어서 사용자가 Annotation을 지정하여 basePackage를 지정하지 않으면 AutoConfiguration의 설정을 따르도록 했습니다.
하지만 아무리 AutoConfigurationPackages.get 메소드를 호출해도 Bean 정보가 없다는 Exception이 발생하였습니다.
처음에는 AutoConfigurationPackages.get가 아니라 혹시 다른 메소드가 이를 대신하나 싶어서 샅샅히 찾아봤지만 코드상에서는 찾을 수 없었습니다.
그렇게 한참을 삽질하다 문득 spring.factories에 EnableAutoConfiguration 설정을 하지 않았음을 알게 되었고, 설마 이것때문에? 라는 생각으로 관련 AutoConfiguration 클래스를 등록시켰습니다.

그 결과, 설정 이후에 정상적으로 basePackage 정보를 가져오는 것을 확인하고 많이 부족함을 재차 느꼈습니다.
삽질 4. Gradle기반 Spring Boot Starter 만들기
Spring Boot Starter 관련하여, Maven 기반으로 Starter를 작성하는 방법에 대해서는 다수 있지만, Gradle로 만드는 방법은 찾기 어려웠습니다. 다만 Spring Boot Starter 개념은 아래 링크에 참고된 블로그를 통해서 학습할 수 있었습니다. 한참의 삽질끝에 완성할 수 있었습니다.
참고 블로그
- nevercaution.github.io/spring-boot-starter-custom/
삽질 5. Maven Central 배포하기
운이 좋게 저보다 앞서 고생하시고 그 기록을 남겨주신 siyoon210님 블로그를 통해서 다른 과정과 비교했을 때 큰 문제 없이 업로드할 수 있었습니다.
마치며
숲을 제대로 모른 상태에서 나무만 보면서 만들다보니 삽질이 많았습니다. 하지만 그런 시행착오를 겪으면서 배워서 그런지 학습한 내용이 보다 오랫동안 기억에 남을 것같습니다. 공식 문서에 사용법에 대해서 작성했으나 나중에 기회가된다면 튜토리얼 포스팅을 작성해볼까 합니다. 관련된 자료는 아래 링크를 참고하시기 바랍니다.
마지막으로 해당 라이브러리에 대한 코드기여는 언제나 환영입니다.
GitHub : Excel-Parser
Documentation : Excel-Parser Wiki