지금까지 gRPC에 대한 소개 및 해당 기술이 가진 이점에 대해서 살펴봤습니다. 이번 포스팅에서는 kotlin 환경에서 gRPC 관련 기본 설정 셋업하는 방법에 대해서 다루어보도록 하겠습니다. 프로젝트 설정은 gradle 기반의 기본 Kotlin 빈 프로젝트는 생성되었음을 가정하고 진행하겠습니다.
1. gradle 설정 추가
build.gradle.kts
import com.google.protobuf.gradle.*
plugins {
...(중략)...
id("com.google.protobuf") version "0.8.13"
}
가장 먼저 설정할 것은 protobuf 관련 plugin을 설정하는 것입니다. 위 내용을 gradle.kts 파일 plugins 항목에 추가합니다.
build.gradle.kts
...(중략)...
val grpcVersion = "3.19.4"
val grpcKotlinVersion = "1.2.1"
val grpcProtoVersion = "1.44.1"
dependencies{
implementation("io.grpc:grpc-kotlin-stub:$grpcKotlinVersion")
implementation("io.grpc:grpc-protobuf:$grpcProtoVersion")
implementation("com.google.protobuf:protobuf-kotlin:$grpcVersion")
}
그 다음에는 protobuf 관리와 stub을 자동으로 생성해주는 라이브러리 의존성을 위와같이 추가합니다.
마지막으로 설정할 내용은 build 시점에 protobuf를 생성하기 위한 task를 추가하는 작업입니다. 해당 설정을 통해 Java Stub 파일과 Kotlin Stub파일을 생성할 수 있습니다.
기본 설정이 모두 끝났으면 gradle refresh를 통해서 설정을 마무리합니다.
2. 임시 Protobuf 생성 테스트
설정이 완료되었으면, Protobuf를 만들어보고 정상적으로 Stub 클래스가 생성되는지 확인해보도록 하겠습니다.
먼저 main 디렉토리 하위에 proto 디렉토리를 생성합니다.
생성된 proto 디렉토리 하위에 test.proto를 생성합니다.
간단한 테스트를 위해 위 내용을 기입합니다.
gradle 탭에서 build 버튼을 클릭합니다.
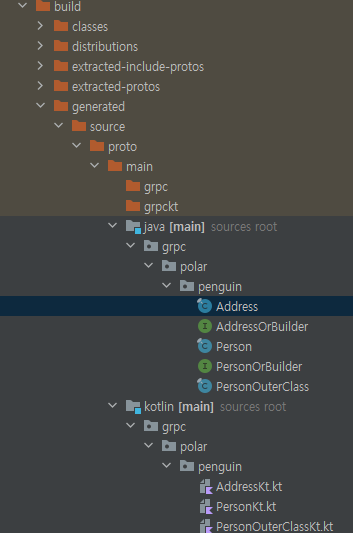
build가 정상적으로 완료되면, 위 그림과 같이 build 폴더가 생깁니다. 이를 확인해봅시다.
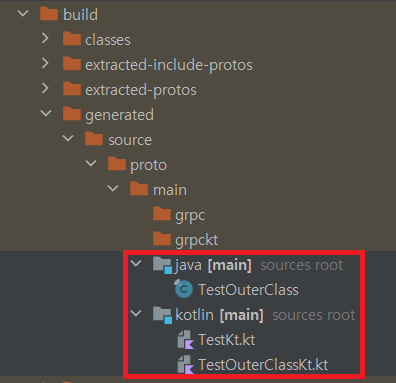
Stub 클래스가 정상 생성되었는지 확인을 위해 build > generated > source > proto > main 하위에 java와 kotlin 패키지를 열어봅니다. 만약 정상적으로 build가 완료되었으면, 위 그림과 같이 Test Stub 클래스가 생성된 것을 확인할 수 있습니다.
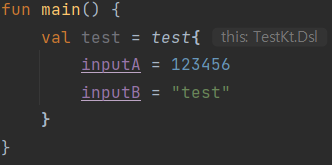
생성된 Stub 클래스를 프로그램내에서 정상 사용할 수 있는지 여부를 테스트하기 위해 위와 같이 별도 main 함수를 만들어 생성 가능 여부를 확인해봅니다.
만약 클래스 참조가 불가하다면, build.gradle.kts 파일에 sourceSets 내 경로가 일치하는지 확인 후 수정합니다.
지금까지 과정이 모두 정상적이라면, proto 파일을 만들고 이를 build하고 Stub 클래스를 생성 후 프로그램 참조하는 모든 과정을 가볍게 훑어볼 수 있었습니다. 테스트를 위해 사용되었던 test.proto 파일은 더 이상 필요하지 않으므로 제거해도 좋습니다.
3. 마치며
이번 포스팅은 Kotlin 기반에서 gRPC 설정 하는 방법에 대해서 알아봤습니다. 다음 포스팅부터는 본격적으로 protobuf 사용법에 대해서 알아보겠습니다.
지난 포스팅에서는 gRPC에서 사용되는 protobuf와 REST 통신에서 사용되는 JSON 크기와 Serialization/Deserialization 관점에서 성능을 비교해봤습니다. 이번에는 gRPC에서 제공하는 통신 방법에 대해서 살펴보고 REST 단건 통신과 비교하여 송/수신 시간을 비교해보겠습니다.
1. gRPC 통신 방법
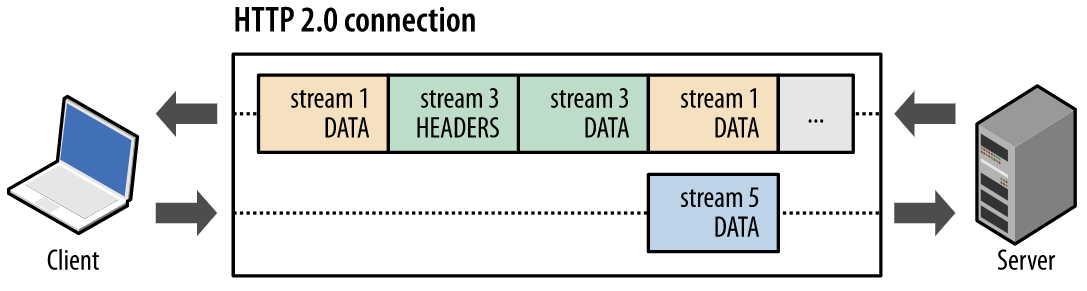
gRPC는 HTTP 2.0을 기반으로 구성되어있기 때문에 Multiplexing으로 연결을 구성할 수 있습니다. 따라서 단일 Connection으로 순서의 상관없이 여러 응답을 전달받을 수 있는 Streaming 처리가 가능합니다. gRPC는 총 4가지의 통신 방법을 지원하며 그 중 3가지 방식은 Streaming 처리 방식입니다. 지금부터 하나씩 살펴보겠습니다.
2. Unary
첫 번째 방식은 Unary 통신 방식입니다.
이는 가장 단순한 서비스 형태로써 클라이언트가 단일 요청 메시지를 보내고 서버는 이에 단일 응답을 내려보내주는 방식입니다. 일반적으로 사용하는 REST API를 통해 주고 받는 Stateless 방식과 동일하다고 볼 수 있으며, 개념적으로 이해하기 쉽습니다.
그렇다면 gRPC의 Unary 통신과 REST의 성능을 비교해보면 어떤차이를 보일까요? 테스트 시나리오를 기반으로 두 통신방법을 비교해보록 하겠습니다.
1. 사용자를 등록하는 서비스가 있다고 가정한다. 2. 10, 100 등 10만까지 10의 거듭 제곱 형태로 delay없이 요청 횟수를 늘리면서 REST와 gRPC의 응답 총 시간을 구한다. 3. 테스트 시작전 warm up을 위해 50회의 요청 수행 후 테스트를 진행한다.
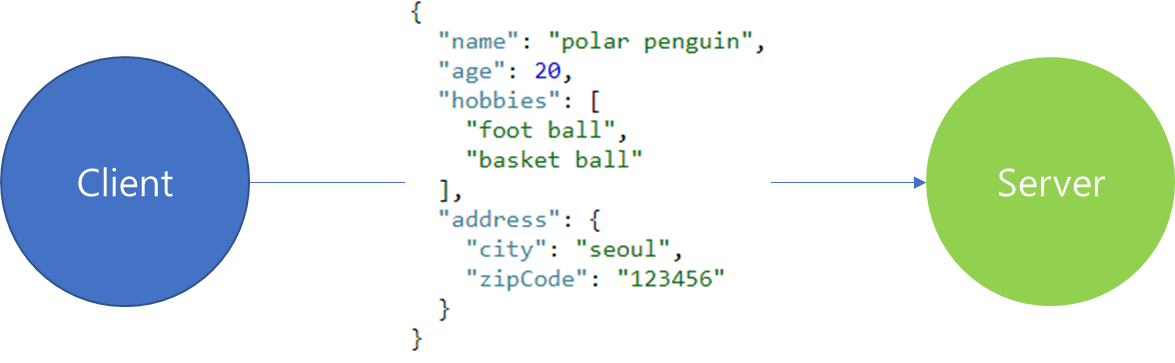
Protobuf는 위와 같이 디자인했습니다. message 포맷은 이전 포스팅에서 설계 내용과 동일합니다. 여기서 새로 추가된 항목은 service 부분입니다. 추가된 내용을 살펴보면 인자로 Person 타입을 입력받고 반환 값은 없으므로 Empty를 지정하였습니다.
이번 포스팅 내용은 통신 방법에 대한 설명이므로 syntax 설명은 향후 다른 포스팅 내용으로 다루겠습니다.
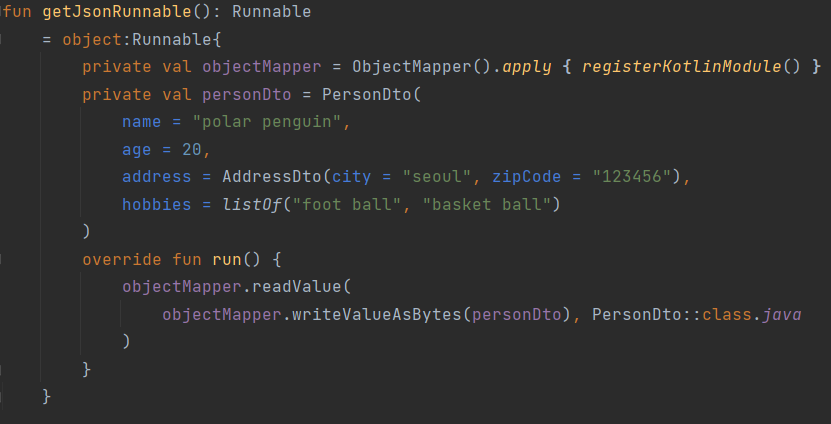
class PersonGrpcService : PersonServiceGrpcKt.PersonServiceCoroutineImplBase() {
override suspend fun register(request: Person): Empty {
//TODO : request 처리
return Empty.getDefaultInstance()
}
}
Proto 파일 디자인 후 Build하면 Stub 클래스가 자동 생성됩니다. 위 코드는 gRPC 서비스 처리를 구현하기 위해 Stub 클래스인 PersonServiceCoroutineImplBase을 상속받아 구현한 코드입니다. 테스트 시나리오에서는 전달받은 Person 객체를 따로 저장하거나 처리하지 않고 Empty 객체를 반환하도록 구현하였습니다.
fun main() {
val server = ServerBuilder.forPort(6565)
.addService(PersonGrpcService())
.build()
server.start()
server.awaitTermination()
}
Server 기동 시에 Service를 등록 시켜서 Client의 요청이 들어왔을 경우에 해당 Service로 Routing 하도록 설정합니다. 이후 Server를 기동합니다.
fun main() {
val channel = ManagedChannelBuilder.forAddress("localhost", 6565)
.usePlaintext()
.build()
val stub = PersonServiceGrpc.newBlockingStub(channel)
execute(stub, 50) //warm up phase
val base = 10.0
val dec = DecimalFormat("#,###")
for (exponent in 1..5) {
val iterCount = base.pow(exponent).toInt()
val time = measureTimeMillis {
execute(stub, iterCount)
println("count : ${dec.format(iterCount)}")
}
println("elapsed time $time ms")
println("------------------------------------")
}
channel.shutdown()
}
Unary 테스트를 위한 client 코드는 위와같습니다. Server를 localhost의 6565 포트에서 기동중이므로 해당 요청에 대한 Channel을 생성합니다.
이후 proto 파일 Build 과정에서 생성된 PersonServiceGrpc 내에 있는 BlockingStub 객체를 생성 해서 해당 Channel에 Binding 합니다. Channel에 Binding 한 다음에는 Stub 객체의 메소드를 호출하면 Server와 통신을 수행할 수 있습니다.
stub 객체까지 만들고 나면, 10 ~ 10만번까지 10의 거듭제곱 형태로 늘려가면서 gRPC Unary 통신을 수행 후 총 수행 시간을 출력합니다.
위 코드에서 실질적으로 gRPC를 호출하는 부분은 execute 함수입니다.
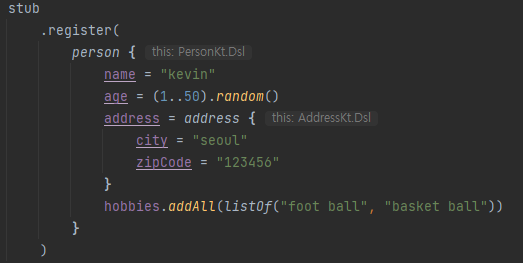
fun execute(stub: PersonServiceGrpc.PersonServiceBlockingStub, count: Int) {
repeat(IntRange(1, count).count()) {
stub.register(
person {
name = "kevin"
age = (1..50).random()
address = address {
city = "seoul"
zipCode = "123456"
}
hobbies.addAll(listOf("foot ball", "basket ball"))
}
)
}
}
execute 함수를 살펴보면 위와 같이 iteration count를 인자로 전달받고 그 횟수만큼 gRPC 요청을 보내는 것을 확인할 수 있습니다.
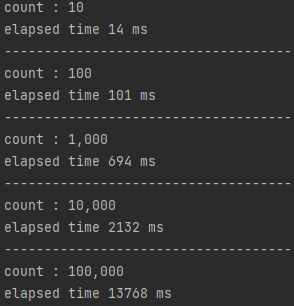
프로그램을 실행하면 위와 같이 Unary 요청 수행 결과를 확인할 수 있습니다.
이번에는 REST 통신을 통해 같은 횟수를 반복했을 때 Unary 통신과 비교하여 총 수행시간이 얼만큼의 차이가 있는지를 비교해보도록 하겠습니다. 이때 Unary 테스트 또한 단일 Channel에서 Blocking 방식으로 수행시간을 측정하였으므로 REST 통신 또한 같은 방법으로 테스트를 진행하겠습니다.
data class PersonDto(
val name : String,
val age : Int,
val hobbies : List<String>? = null,
val address : AddressDto? = null
)
data class AddressDto(
val city : String,
val zipCode : String
)
JSON으로 입력받을 DTO를 위와 같이 디자인합니다.
@RestController
class PersonController(private val service: PersonService) {
@PostMapping("/person")
suspend fun register(@RequestBody person : PersonDto) {
//TODO : request 처리
}
}
REST Controller 코드는 위와 같습니다. gRPC 서비스 코드에서도 인자를 전달받아 아무런 처리를 하지 않았기 때문에 마찬가지로 요청만 전달받고 아무 처리를 수행하지 않도록 구성하였습니다.
@Component
class RegisterTest : CommandLineRunner {
override fun run(vararg args: String?) {
val client = WebClient.builder()
.build()
execute(client, 50) // warm up phase
val base = 10.0
val dec = DecimalFormat("#,###")
for (exponent in 1..5) {
val iterCount = base.pow(exponent).toInt()
val time = measureTimeMillis {
execute(client, iterCount)
println("count : ${dec.format(iterCount)}")
}
println("elapsed time $time ms")
println("------------------------------------")
}
}
private fun execute(client: WebClient, count: Int) {
repeat(IntRange(1, count).count()) {
client.post().uri("localhost:8080/person")
.bodyValue(
PersonDto(
name = "kevin",
age = (1..50).random(),
address = AddressDto(city = "seoul", zipCode = "123456"),
hobbies = listOf("foot ball", "basket ball")
)
)
.retrieve()
.bodyToMono(Void::class.java)
.block()
}
}
}
Client 수행 프로그램은 위와 같습니다. gRPC 테스트 코드와 크게 다르지 않으며, 차이점이 있다면 Stub 객체를 사용한 것이 아닌 Webclient를 사용한 부분입니다.
Client 코드를 수행하면 위와 같은 결과를 얻을 수 있습니다.
횟수
REST
gRPC(Unary)
성능
10
23 ms
14 ms
1.64배
100
165 ms
101 ms
1.63배
1,000
1,000 ms
694 ms
1.44배
10,000
4,109 ms
2,132 ms
1.92배
100,000
41,491 ms
13,768 ms
3.01배
결과를 살펴보면, Iteration 횟수가 증가할 수록 그 차이가 벌어지는 것을 확인할 수 있습니다. 격차가 벌어진 이유는 다양한 이유가 있지만 Protobuf의 Serialization & Deserialization이 가장 큰 영향을 미치지 않았을까 생각합니다.
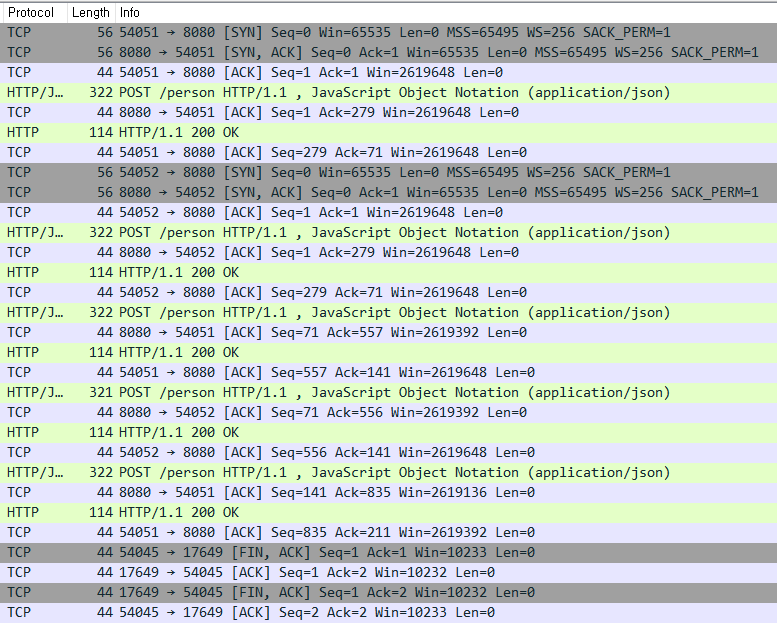
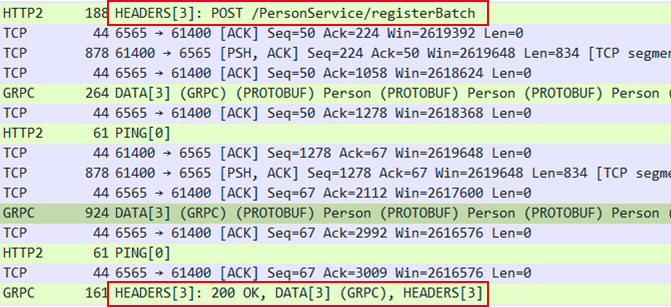
이번에는 네트워크 패킷을 통해서 REST와 gRPC의 통신 과정을 비교 해보겠습니다. 비교를 위해서 사용자 등록을 5회만 수행 후 종료한 내용을 확인해보도록 하겠습니다.
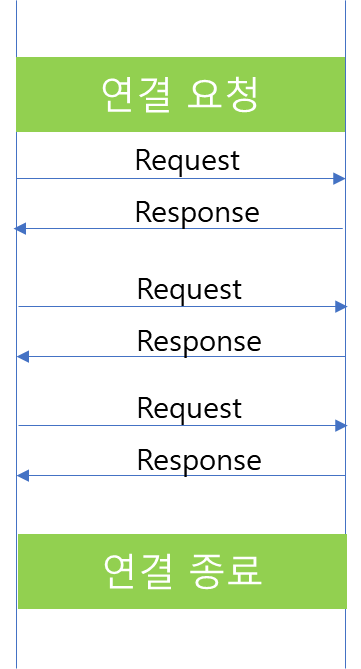
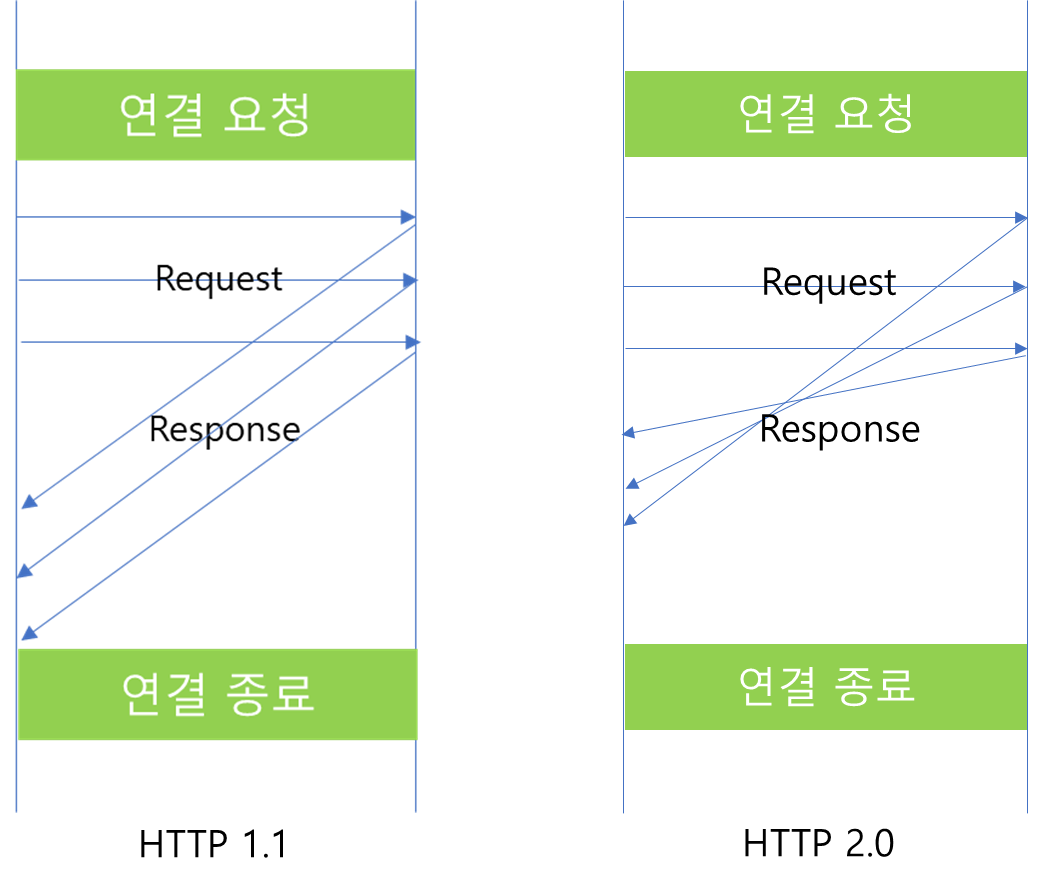
REST 통신을 5회 수행하였을 때, 네트워크 흐름을 표시하면 위 그림과 같습니다. 자세히보면 REST 통신은 HTTP 1.1을 사용한 것을 알 수 있고 SYN, ACK와 FIN, ACK가 매 요청마다 보이지 않는 것으로 보아 Connection을 매번 요청하지 않았음을 확인할 수 있습니다.
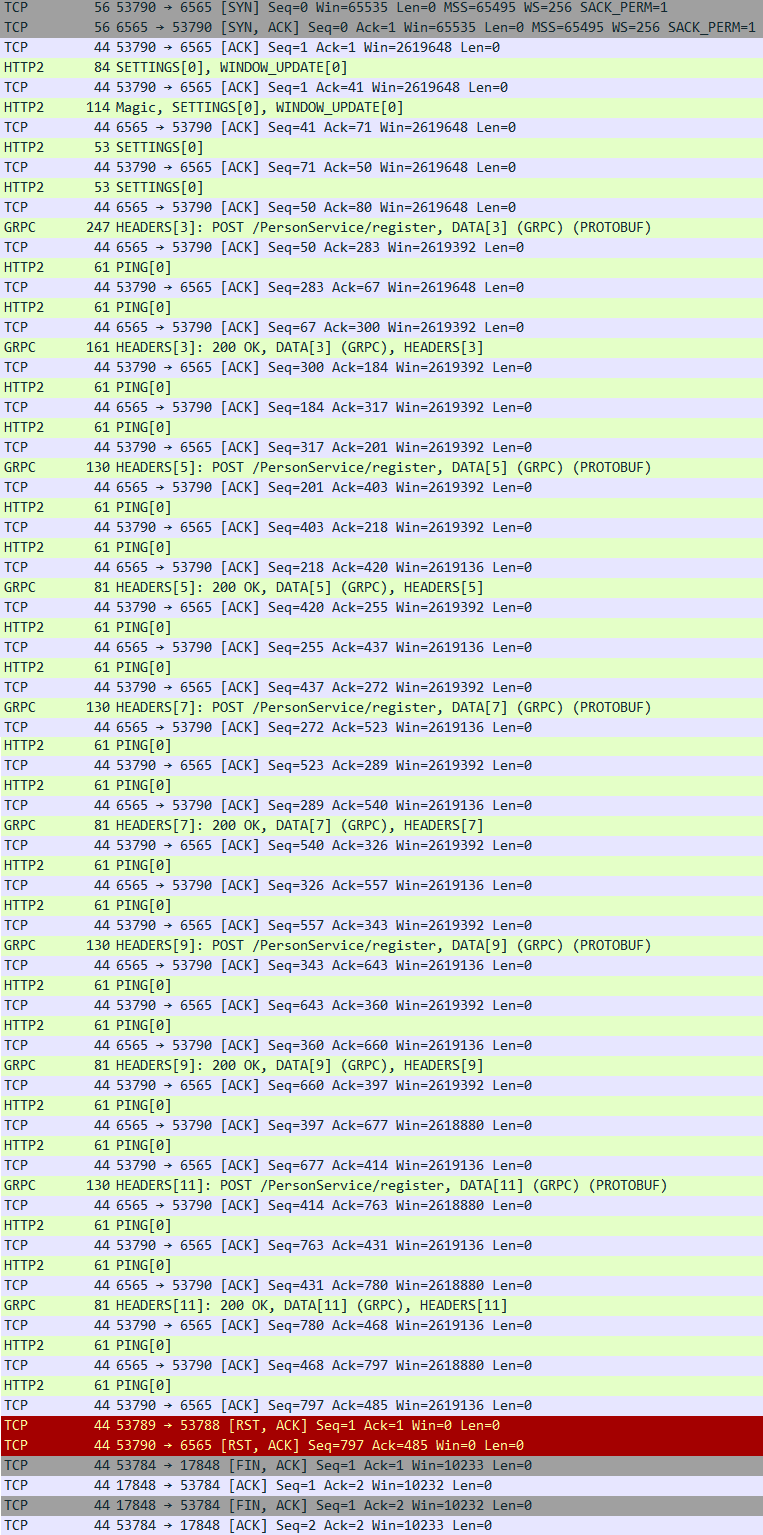
이번에는 gRPC Unary 통신 결과입니다. REST에서는 HTTP 1.1 방식이었던 것과 달리 예상대로 HTTP 2.0으로 통신을 수행한 것을 확인할 수 있습니다.
gRPC에서 Unary 통신은 HTTP 2.0 Stream으로 데이터를 전송합니다. 따라서 위 패킷 내용을 살펴보면, Stream 통신에 있어서 필요한 데이터 흐름을 파악할 수 있습니다.
가령 WINDOW_UPDATE를 통해서 Client가 수신할 수 있는 Byte 수를 Server에 알려줘 해당 정보를 기반으로 Flow control이 가능하도록 사전 설정하는 것을 확인할 수 있습니다. 또한 PING 패킷의 경우는 연결된 Channel 에서 사용중인 Connection liveness를 체크합니다. 만약 PING 단계에서 정상 응답을 수신 받지 못하면, Connection을 끊습니다. 이후 Connection 재생성을 통해 다시 연결할 수 있습니다.
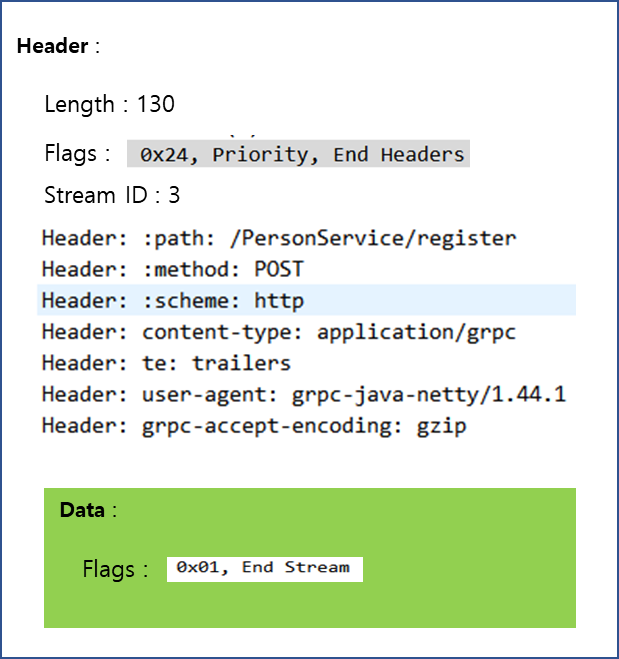
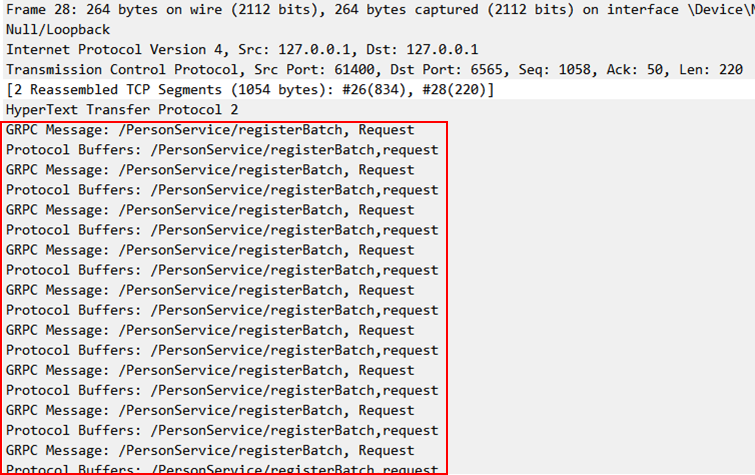
이번에는 데이터 패킷을 상세하게 살펴보도록 하겠습니다.
위 그림은 요청 패킷을 구조화한 모습입니다.
Header를 살펴보면, Header의 길이 그리고 Header의 종류 flag가 보입니다. 그리고 Stream ID가 표시된 것을 볼 수 있는데, 이는 HTTP Stream 내에서 사용되는 Stream 메시지 별 Unique ID 입니다. Client에서 보내는 메시지는 Stream ID가 홀수개로 증가합니다.
Header에는 그 밖에 요청 Path 정보 및 Schema, Content-type이 표시됩니다. 내부적으로 요청은 POST로 요청되는 것을 확인할 수 있습니다.
Data 영역에는 실제 전달되는 데이터와 Flag등을 전달합니다. Unary 통신의 경우 gRPC Stream 요청은 아니므로 Flag에는 End Stream으로 지정된 것을 확인할 수 있습니다.
응답 패킷은 크게 3가지 부분으로 이루어져있습니다. 첫번째는 요청에 대한 응답헤더이고, 두 번째는 응답에 대한 데이터 마지막으로는 trailer 헤더로 구성되어있습니다.
그렇다면 위 5개의 데이터 전송 흐름에서 gRPC 패킷은 어떤 특징을 지니고 있을까요?
요청 패킷을 살펴보면, Header 길이가 최초 메시지를 보낼 때보다 크기가 줄어든 것을 확인할 수 있습니다. 또한 Stream ID는 홀수 번호로 순차 증가한 것을 확인할 수 있습니다.
마찬가지로 응답 패킷을 살펴보면, 최초 응답 헤더에 비해 이후 응답 메시지의 Header 크기가 줄어든 것을 확인할 수 있습니다.
위와 같이 gRPC는 기반에 HTTP 2.0을 기반으로 하여 메시지 전송간 데이터 Payload가 줄어드는 장점이 존재하기 때문에 이전 REST 방식에 통신에 있어서 조금 더 빠른 결과를 나타낼 수 있습니다.
3. Streaming
이번에는 Streaming 처리 방법에 대해서 살펴보도록 하겠습니다. Stream은 데이터를 한번만 전송하는 것이 아니라 연속적인 흐름으로 전달하는 것을 의미합니다.
gRPC에서는 총 3가지 종류의 Streaming이 존재합니다.
1) Client Stream
Client는 Stream 형태로 전달하고 Client의 요청이 끝나면 Server에서 한번에 응답을 내려주는 경우는 Client Stream이라고 부릅니다.
2) Server Stream
Client의 요청은 한번만 전달하고 Server에서 응답은 여러 번에 걸쳐 전송하는 경우는 Server Stream이라고 부릅니다.
3) Bidirectional Stream
양방향 모두 Stream으로 데이터를 전송하는 경우는 Bidirectional Stream 이라고 부릅니다.
Stream 처리 방법은 개념적으로 어렵지 않고 이번 포스팅에서는 사용 방법 보다는 성능 비교가 주 목적이므로 모든 Stream 방식에 대한 구현을 다루지는 않겠습니다.
Stream 처리 관련해서 다루어볼 내용은 Client Stream 방식을 활용해서 Unary, REST 방식의 테스트 시나리오를 동일하게 적용하여 어떤 차이점이 있는지를 살펴보도록 하겠습니다.
먼저 Stream 처리를 위해 서비스에 RPC를 등록합니다. 이후 Build를 수행합니다.
class PersonGrpcService : PersonServiceGrpcKt.PersonServiceCoroutineImplBase() {
...(중략)...
override suspend fun registerBatch(requests: Flow<Person>): Empty {
val start = System.currentTimeMillis()
requests
.catch {
//TODO : Error 처리
}
.onCompletion {
println("${System.currentTimeMillis() - start} ms elapsed. ")
}
.collect {
//TODO : request 처리
}
return Empty.getDefaultInstance()
}
}
Build 이후 해당 Stub 메소드 구현을 위해서 PersonServiceCoroutineImplBase Stub 클래스에서 RPC 관련 메소드를 override 합니다. 이때 Stream으로 전달받은 데이터를 기반으로 비즈니스 로직 처리는 수행하지 않기 때문에 collect 부분은 아무런 작업을 수행하지 않도록 구성했습니다.
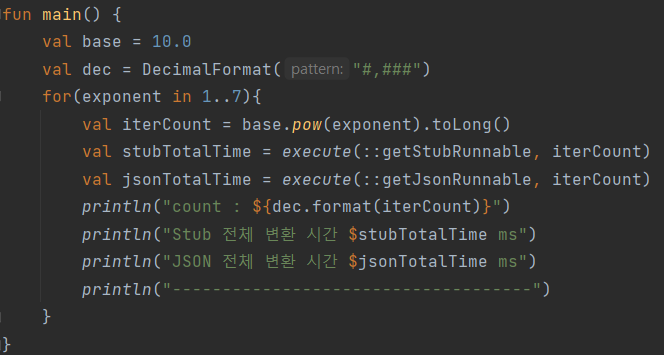
fun main() {
val channel = ManagedChannelBuilder.forAddress("localhost", 6565)
.usePlaintext()
.build()
val stub = PersonServiceGrpcKt.PersonServiceCoroutineStub(channel)
runBlocking { execute(stub, 50) } // warm up phase
val base = 10.0
val dec = DecimalFormat("#,###")
runBlocking {
for (exponent in 1..5) {
val iterCount = base.pow(exponent).toInt()
val time = measureTimeMillis {
execute(stub, iterCount)
println("count : ${dec.format(iterCount)}")
}
println("elapsed time $time ms")
println("------------------------------------")
}
}
}
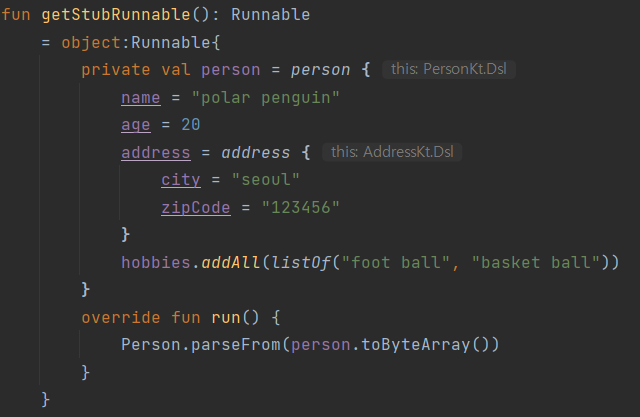
suspend fun execute(stub: PersonServiceGrpcKt.PersonServiceCoroutineStub, count: Int) {
try {
stub.registerBatch(
IntRange(1, count)
.map {
person {
name = "kevin"
age = (1..50).random()
address = address {
city = "seoul"
zipCode = "123456"
}
hobbies.addAll(listOf("foot ball", "basket ball"))
}
}
.asFlow()
)
} catch (e: StatusException) {
println(e)
}
}
Client 프로그램은 위와 같이 구성했습니다. gRPC의 Stream 처리를 구현하기 위해서 StreamObserver를 활용해서 구현하는 방식과 Kotlin의 Coroutine 방식 두 가지 방식으로 구현 가능한데, 위 코드는 Coroutine 방식으로 구현하였습니다.
내용을 살펴보면 이전 Unary 코드와 크게 다르지는 않으며, 데이터 전달시 Flow로 변환하여 전달하는 것을 확인할 수 있습니다.
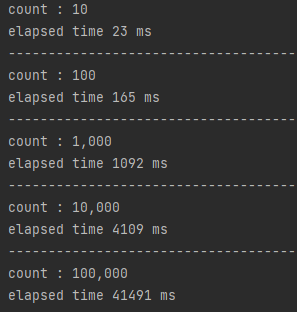
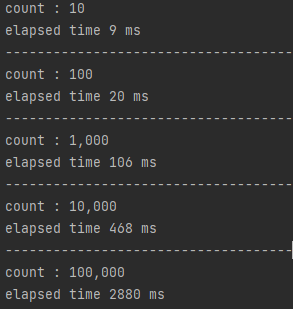
코드 구현이 완료되었으면 실행 후 결과를 비교해보겠습니다.
실행 결과를 살펴보면, REST와 gRPC(Unary)와 비교했을 때 엄청난 개선이 이루어진 것을 확인할 수 있습니다.
이를 표로 나타내면 다음과 같습니다.
횟수
REST
gRPC(Unary)
gRPC(Client Stream)
10
23 ms
14 ms
9 ms
100
165 ms
101 ms
20 ms
1,000
1,000 ms
694 ms
106 ms
10,000
4,109 ms
2,132 ms
468 ms
100,000
41,491 ms
13,768 ms
2,880 ms
요청 횟수가 적을 때보다 횟수가 늘어감에 따라 차이가 더 커지는 것을 확인할 수 있습니다. 가령 10만번 데이터 전송의 경우 REST 방식보다 14.4배 Unary 방식에 비교하면 4.78배 효율이 좋은 것을 확인할 수 있습니다.
그렇다면 Stream 처리 방식은 왜 이리 많은 차이를 보이는 것일까요? 이전과 마찬가지로 패킷의 흐름을 살펴보겠습니다.
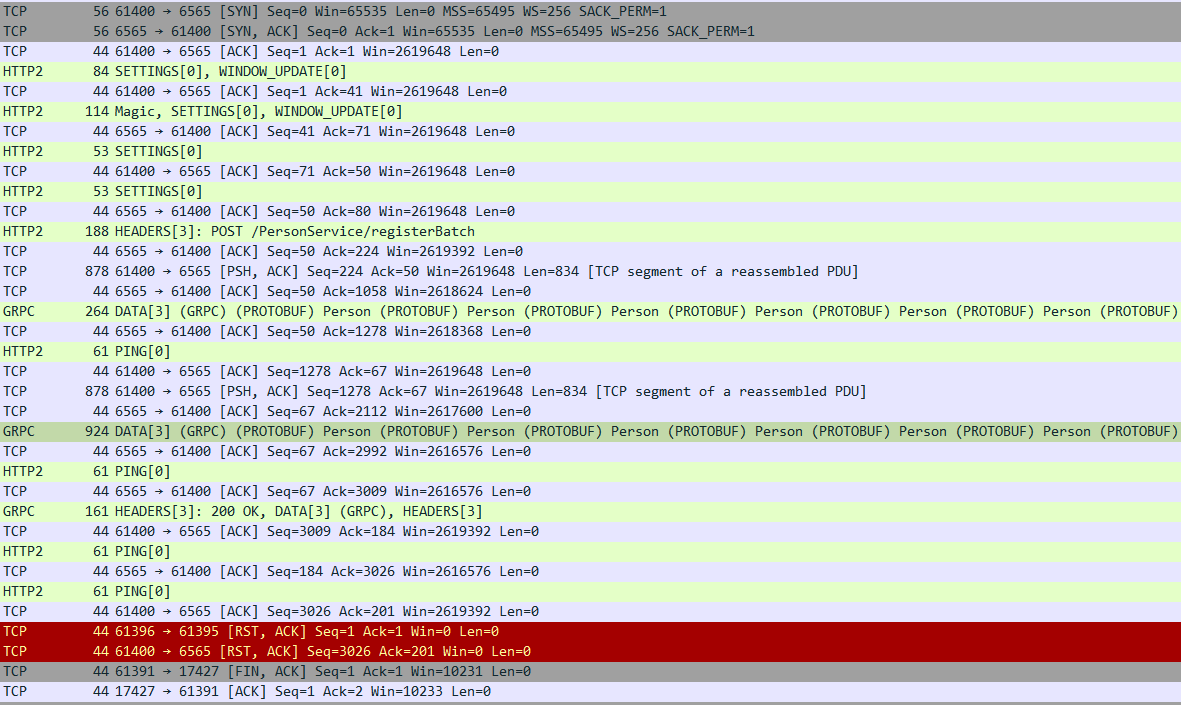
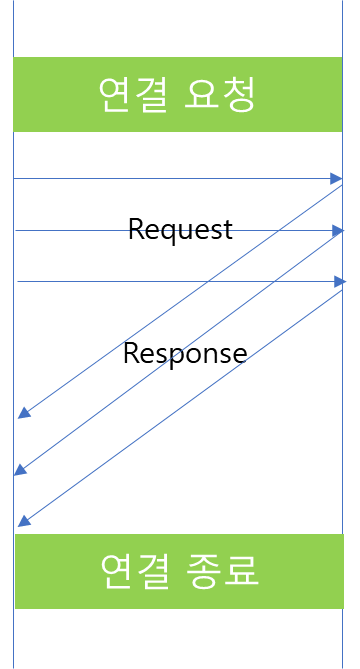
위 내용은 Stream 형식으로 Person 데이터를 50회 전송했을 때 네트워크 흐름입니다.
Unary와 REST 방식은 5회만 전송했는데도 많은 Network 요청이 있었던 것과 비교하여 50회 데이터를 전송했는데도 패킷의 횟수가 그리 많지 않습니다.
데이터 전송 부분만 살펴보면, 요청을 전달할 때 Header는 한번만 전송한 것을 확인할 수 있고, 응답 또한 한번만 전달받은 것을 확인할 수 있습니다.
그리고 데이터는 여러번 전달한 것이 아니라 한 Packet안에 여러개의 요청이 포함되어 전달된 것을 확인할 수 있습니다.
위 패킷 흐름에는 총 2번 전달하는 과정에서 50개의 요청이 담겨있는 것을 확인할 수 있습니다.
한번에 동일 요청 다수를 함께 전달할 경우, Stream 방식이 매번 요청을 수행하는 Unary 방법보다 효율적인 데이터 전송이 가능합니다. 따라서 네트워크 전달 과정에서 많은 비용을 감소하여 성능이 더욱 좋다고 볼 수 있습니다.
4. 마치며
지난 포스팅과 이번 포스팅을 통해서 gRPC의 성능 이점에 대해서 다양한 각도로 살펴봤습니다. 다음 포스팅부터는 gRPC를 사용하는 방법에 대해서 차차 알아보도록 하겠습니다.
이전 포스팅에서는 gRPC에 대한 기본적인 소개를 다루어 봤습니다. 이번에는 gRPC에서 사용하는 Protocol Buffer(aka Protobuf)와 보편적으로 사용하는 JSON 메시지 포맷에 대한 비교를 통해 어떤 부분에서 Protobuf가 이점이 있는지를 살펴보겠습니다.
1. JSON, Protobuf 변환 속도 비교
이전 포스팅에서 살펴봤듯이 REST 통신에서는 JSON 규격으로 메시지를 주고 받았고 이때 발생하는 Serialization & Deserialization 과정은 비용이 소모되는 작업임을 살펴봤습니다. 반면 gRPC에서는 binary 포맷으로 데이터를 주고받기 때문에 변환 과정에 따른 비용이 JSON에 비해서 적다고 설명했습니다.
그렇다면 실제 Protobuf 변환 과정과 JSON 변환 과정을 측정해보면 얼마나 유의미한 결과를 나타낼까요? 테스트를 통해 차이가 얼마나 발생하는지 살펴봅시다.
data class PersonDto(
val name : String,
val age : Int,
val hobbies : List<String>? = null,
val address : AddressDto? = null
)
data class AddressDto(
val city : String,
val zipCode : String
)
JSON 변환 테스트를 위해 Sample 객체를 위와 같이 디자인합니다. 위 데이터 구조는 Person이라는 객체를 생성함에 있어 이름, 나이, 주소 정보를 입력받으며 취미의 경우 다수가 존재하므로 List로 입력받도록 디자인 했습니다.
앞서 구현한 data class에 대응되는 Proto 파일은 위와 같이 구현합니다. 아직 Protobuf에 대해서 본격적으로 다루어보지 않은만큼 syntax가 이해되지 않더라도 좋습니다.
기본 Spec을 정의하였으면 이제 변환 과정 테스트 시나리오를 정의해봅시다.
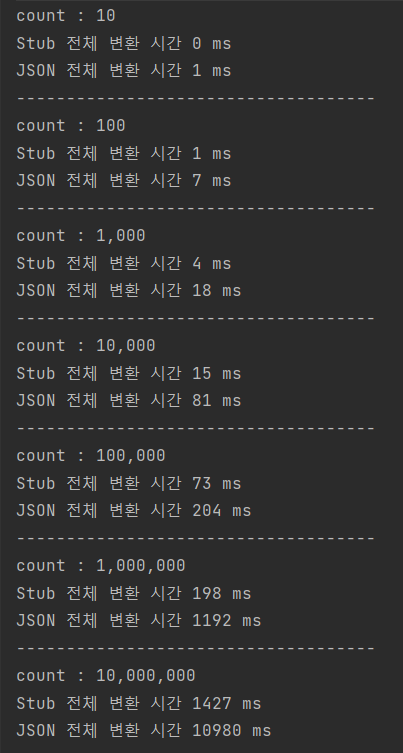
1. 10, 100 ... 천만번까지 10의 거듭제곱 횟수만큼 변환 과정을 수행하면서 각 단계에서 걸린 총 시간을 측정한다.
2. 단계별 warm up 과정을 추가하고 해당 단계에서의 결과는 제외한다. 따라서 단계별 50회 변환 과정을 추가한다.
3. JSON, Proto 변환 측정 과정은 다음과 같다. - JSON : DTO를 JSON Byte 배열로 변환한 다음 해당 Byte을 다시 DTO로 변환하는데 걸린 시간 - Proto : Stub을 Byte 배열로 변환한 다음 해당 Byte 배열을 다시 Stub 객체로 변환하는데 걸린 시간
테스트 시나리오를 위해 작성한 메인 프로그램의 흐름은 위와 같습니다. 10 부터 천만번까지 각각 변환과정을 수행한 결과를 출력하도록 구성했습니다.
측정 과정은 앞서 시나리오대로 단계별 변환 횟수에 맞추어 변환 작업을 수행하며, 단계별 최초 50회는 warm up 단계로 구성하여 결과에서 제외한 총 수행시간을 반환하도록 작성했습니다.
Stub 객체를 Byte 배열로 변환하고 이를 다시 Stub 객체로 변환하는 코드는 위와 같습니다.
DTO 객체를 JSON Byte 배열로 저장한 다음 이를 다시 Person DTO 객체로 변환하는 코드는 위와 같습니다. 이 과정에서 Parser로는 Jackson을 사용했습니다.
코드 작성은 모두 마무리되었습니다. 이제 프로그램을 수행시킨 결과를 확인해봅시다.
측정 결과는 위와 같습니다. 살펴보면 변환 횟수가 증가하면서 두 방식의 변환 시간의 차가 크게 벌어지는 것을 확인할 수 있습니다. 가령 천만번 변환의 경우 7배 빠른 것으로 확인되었습니다.
그렇다면 위 측정결과를 gRPC가 REST 방식에 비해 7배 빠르다고 말할 수 있을까요?
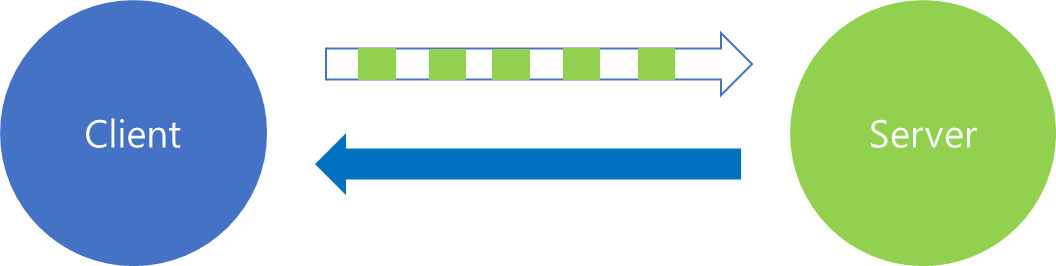
요청에 대해서 응답을 처리하는 전체 flow를 아주 간략하게 표현한다면, 위와 같이 표현할 수 있을 것입니다. 위 과정에서 오래걸리는 영역은 당연히 Business Logic 처리를 위한 수행시간일 것입니다. 따라서 Business Logic 수행 시간이 오래 걸릴 수록 격차는 현격히 줄어들 것입니다.
하지만 TPS가 높은 시스템에서는 1ms라도 응답 속도를 줄이는 것이 중요하기 때문에 이런 경우 매우 유의미한 결과라고 볼 수 있습니다.
2. JSON, Protobuf 크기 비교
이번에는 기존에 사용했던 DTO, Stub 인스턴스를 byte 배열로 변환하였을 때 크기에 대해서 비교해보고 차이점을 통해 Protobuf의 특징을 확인해보겠습니다.
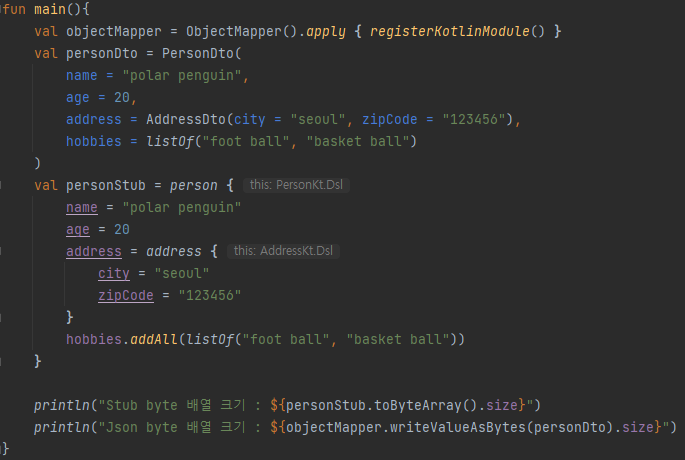
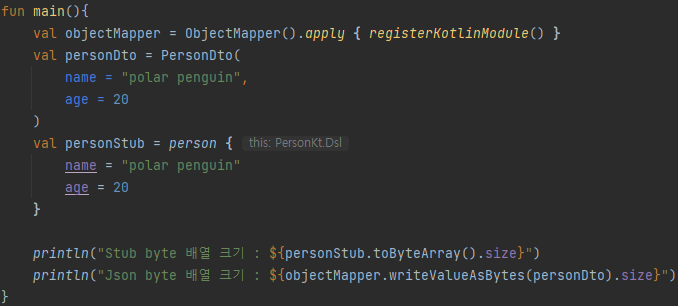
사이즈 크기 비교를 위해 작성한 프로그램은 위와 같습니다. 이전 내용과 같이 PersonDTO와 Stub 객체를 생성 후 둘 다 byte 배열로 변환한 크기를 출력하도록 구성했습니다.
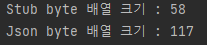
실행 결과를 보면, 동일한 데이터 입력에 있어 JSON 방식과 Proto 방식간의 결과물 크기가 상당히 차이나는 것을 확인할 수 있습니다.
이러한 차이가 발생하는 이유는 Proto 메시지 정의에 따라서 Binary 데이터를 만드는 encoding 과정에서 데이터가 압축되기 때문입니다. 이와 관련하여 자세한 기술적인 내용은 아래 네이버 기술 블로그와 구글 Protocol Encoding 공식문서를 살펴보시면 도움 되실 것 같습니다.
이전에 살펴본 Person의 proto 정의는 위와 같습니다. 그리고 테스트 프로그램에서 수행한 실제 Stub 객체에는 hobbies와 address가 포함되지 않았음을 확인할 수 있습니다.
proto 파일에서 눈여겨 볼 점은 실제 Property 옆에 표시된 field 번호가 존재하는 점입니다. 가령 name에는 1이 age에는 2가 지정되어있습니다.
해당 번호는 Protobuf의 필드를 인식하게 만들어주는 Key를 구성하는 요소입니다. 참고로 이전에 첨부한 Naver 기술 블로그나 Google 공식 문서에서는 해당 Field 번호와 Wiretype가 조합된 Key를 이용하여 Encoding 및 Decoding을 수행하여 필드 값을 Parsing 함을 자세히 확인할 수 있습니다.
그렇다면 hobbies와 address가 입력되지 않았을 때 개념적으로 어떤 변화가 발생했을까요? 먼저 개념적으로 이해하기 위해 추상적으로 어떻게 표현되었는지 살펴봅시다.
protobuf에서는 field 번호가 해당 객체 내에서 필드 값을 식별하는데 있어 주요 역할을 수행합니다. 따라서 protobuf를 설계할 때 field 별로 부여하는 field 번호는 unique 해야합니다.
결과물을 살펴보면, JSON 표현 방식에 비해서 2가지 특징을 지닌 것을 확인할 수 있습니다.
1. 해당 객체 값에 값이 입력되지 않았을 경우 결과물에 포함시키지 않습니다. 따라서 JSON에 비해서 Byte 배열 크기가 줄어들 수 있습니다.
2. 실제 필드명의 길이가 어떻든 관계없이 field 번호를 기반으로 Binary 데이터가 만들어지기 때문에 payload 크기가 감소됩니다. 이는 field 명이 길어질 수록 payload 크기가 커지는 JSON과 대비하여 공간을 절약할 수 있습니다.
이번에는 패킷 수준에서 메시지 내용을 자세하게 살펴보겠습니다. 내용을 보면 방금전 설명했던 설명과 유사함을 확인할 수 있습니다.
데이터 구조를 살펴보면 Field Number와 Wire Type을 기반으로 ( (Field Number << 3) | Wire Type ) 형태로 Hex 값으로 구성되어 있습니다. 또한 모든 Field 내용이 저장되어있지 않고 사용자가 기입한 내용만 저장되어있는 것을 확인할 수 있습니다.
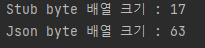
더 자세히 확인하기 위해 실제 Stub 객체에서 생성되는 Binary 내용을 해석해보도록 하겠습니다.
0A: name의 field 번호 1, wire type 2이므로 ( (1 << 3) | 2 ) 수행하면 10입니다. 따라서 이는 Hex 값으로 0A입니다.
0D: value의 길이를 의미합니다. 여기서 name에 저장된 값은 polar penguin 총 13자이므로 이는Hex값으로 0D입니다.
10: age의 field 번호 2, wire type 0이므로 ( (2 << 3) | 0 ) 수행하면 16입니다. 따라서 이는Hex값으로 10입니다.
14: age의 값인 20입니다. 이는 Hex값으로 14입니다.
지금까지 Proto에 저장되는 결과를 알아보기 위해 실제 저장된 Binary 구조까지 살펴봤습니다. 모든 기술이 장점이 있으면 단점이 존재하듯이 Protobuf는 결과물이 Binary 포맷이기 때문에 결과 값을 유추하기 쉽지 않은 점은 단점이라고 볼 수 있습니다. 하지만 성능이 더 중요시되는 환경에서는 짧은 Payload는 전송 속도에 있어 강점입니다.
마치며
이번 포스팅에서는 Protobuf와 JSON을 비교하여 변환 속도와 Payload 크기 차이점을 비교해봤습니다. Protobuf는 gRPC의 핵심 요소로써 gRPC가 가지는 성능 이점의 주요 부분 중 하나라고 생각합니다. 다음 포스팅에서는 HTTP 2.0 기반으로 gRPC의 통신 방법에 대해서 살펴보겠습니다.
최근 MSA가 각광받으면서 많은 회사에서 Monolithic 구조를 여러개의 마이크로 서비스로 분리하려고 시도하고 있습니다.
MSA 구성은 다양한 장점을 내포하고 있으나 그만큼 다양한 문제점 또한 상존합니다. 이 글에서는 MSA의 문제점 중 하나인 네트워크 통신 overhead에 초점을 맞추어 gRPC 기술이 어떤 부분을 해소해줄 수 있는지에 대해서 다루어보고 해당 기술은 어떻게 사용할 수 있는지에 대해서 설명해보고자 합니다.
2. 마이크로 서비스간 통신 이슈
Monolithic 구조에서는 하나의 프로그램으로 동작하기 때문에 그 안에서 구조적인 2개의 서비스간의 데이터는 공유 메모리를 통해서 주고받을 수 있습니다. 따라서 이 경우 서비스간 메시지 전송 성능은 큰 이슈가 되지 않습니다.
반면 MSA에서는 여러 모듈로 분리되어있고 동일 머신에 존재하지 않을 수 있습니다. 따라서 일반적으로는 보편화된 방식인 REST 통신을 통해 메시지를 주고 받습니다.
문제는 Frontend 요청에 대한 응답을 만들어내기 위해 여러 마이크로 서비스간의 협력이 필요하다면, 구간별 REST 통신에 따른 비효율로 인해 응답속도가 저하된다는 점입니다. 그렇다면 구체적으로 어떤 요인으로 인해 응답 속도 저하가 발생될까요? 이에 대해서 알아보기 전에 HTTP 1.1의 특징에 대해서 이해하고 HTTP 1.1의 또 다른 이슈를 확인해보도록 하겠습니다.
3. HTTP 1.1 통신 방법
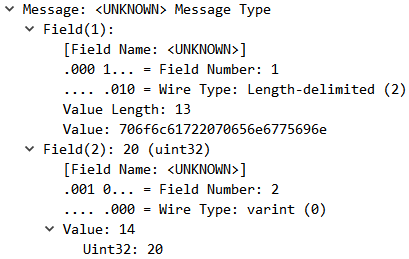
HTTP는 TCP위에서 동작하므로 데이터 송수신에 앞서서 TCP 연결 시점에 3 way handshake 과정을 거치며, 연결을 종료할 때도 4 way handshake 방식으로 종료하게됩니다.
이러한 경우 만약 여러 데이터를 전송 응답을 반복해야하는 상황이라면, 매번 연결을 맺고 종료하는 과정으로 인한 비효율이 발생합니다.
앞서 살펴본 HTTP 1.0은 요청/응답을 하기에 앞서 매번 Connection을 맺고 끊어야했기 때문에 연결 요청/해제 비용이 상당히 높았습니다.
따라서 이러한 성능 이슈를 해결하고자 HTTP 1.0 기반의 브라우저와 서버에서는 자체적으로 Keep-alive 기능을 지원하기도 했습니다. 이 경우 Header에 Keep alive 관련 헤더를 포함해서 Connection을 유지하는 경우도 있었습니다. 하지만 해당 기능은 공식 Spec은 아니였습니다.
HTTP 1.1에서는 1.0의 문제점을 해결하고자 Persistent Connection과 Pipelining 기법을 제공하였습니다. 해당 기능이 무엇인지 알아봅시다.
Persistent Connection의 경우 Keep Alive와 같이 요청/응답을 위해 매번 Connection을 맺는 것이 아니라 연결을 일정시간 지속하는 것을 의미합니다.
다만 Persistent Connection만 적용했을 경우 왼쪽 그림과 같이 1개의 요청을 보내고 요청에 대한 응답이 와야 그 다음 요청을 보내기 위해 기다려야 합니다. 따라서 오른쪽과 같이 추가로 Pipelining을 적용하여 각 요청마다 응답을 기다리지 않고, 요청을 하나의 Packet에 담아 지속적으로 요청을 전달할 수 있도록 개선하였습니다.
Pipelining을 살펴보면 HTTP 1.0과 비교해서 많은 부분이 개선된 것으로 보입니다. 하지만 Pipelining에서도 성능 이슈는 존재합니다. 과연 무엇일까요?
4. HTTP 1.1 문제점
1. HOLB(Head Of Line Blocking)
Pipelining에서 요청 자체는 응답 여부와 관계없이 보낼 수 있습니다. 하지만 여전히 순차적으로 응답을 받아야합니다. 따라서 첫 번째 요청에 대한 응답이 오래걸리는 상황이라면, 두 번째 세번 째 요청 응답은 첫번째 요청이 응답처리가 완료되기 전까지 대기해야합니다. 이러한 문제를 Head Of Line Blocking(HOLB)라고 합니다.
만약 위 예시와 같이 B, C, D, E 자원의 경우 크기가 작아 빠르게 처리될 수 있다면, 사용자 응답성이 좋아질 수 있습니다. 하지만 HTTP 1.1의 경우에는 A 자원의 응답처리가 완료되지 않았기 때문에 결과적으로는 전체 응답의 대기가 발생합니다. 이는 곧 사용성이 나빠지는 원인이 됩니다.
이러한 이슈를 해소하기 위해 대개 브라우저에서는 도메인당 기본 6개(브라우저 별 상이)의 Connection을 맺어놓고 데이터를 병렬적으로 요청 및 응답을 통해서 응답성을 개선하고 있습니다.
또한 개발자 입장에서는 브라우저 특성을 활용하여 자원 다운로드 속도를 빠르게 하기 위해 여러 기법을 사용합니다. 그 중 대표적인 방법은 여러 도메인으로 데이터를 분산하여 저장하고 도메인마다 병렬적으로 Connection 맺어 빠르게 많은 자원을 다운로드하도록 개선하는 방법입니다. 이러한 기법을 도메인 샤딩(Domain Sharding)이라고 합니다.
2. Header 문제
HTTP 통신시 헤더에는 많은 메타 정보가 저장되어 있습니다. 이때 사용자가 특정 사이트를 접속하게되면 방문 시점에 다수의 HTTP 요청이 발생하게 될 것입니다. 그리고 매 요청마다 중복된 헤더 값을 전달하며, 쿠키 또한 매 정보 요청마다 포함되어 전송됩니다. 더욱이 Header 정보는 Plain text로 전달되고 이는 Binary에 비해 상대적으로 크기가 크기 때문에 전송시 많은 비효율이 발생한다고 볼 수 있습니다.
HTTP 2.0은 2014년에 표준안이 제안되고 15년에 공개된 프로토콜입니다. HTTP 1.x 버전의 성능 개선을 위해 Multiplexed Streams 기술을 사용합니다. 해당 기술은 이전에 살펴본 HTTP pepelining의 개선 버전으로 하나의 Connection으로 여러개의 데이터를 주고 받을 수 있도록 Stream 처리가 가능합니다.
또한 응답에 대해서 우선순위(Priority)가 주어져서 요청 순서와 관계없이 우선순위가 높을 수록 더 빨리 응답을 할 수 있는 것이 특징입니다.
세 번째 특징으로는 HTTP 1.1에서는 매 요청마다 동일한 Header 정보를 보내야하는데 반해서 HTTP 2.0 버전에서는 Header 압축을 통해서 지속적인 데이터 요청에 대한 Header 크기를 줄일 수 있습니다.
즉 HTTP 2.0을 사용하게되면 더 적은 Connection으로 더 적은 Header 크기를 전송할 수 있으며 Stream 통신으로 인해 여러 데이터를 주고 받을 수 있게 되었습니다.
그 밖에 여러 특징이 존재하며, HTTP 2.0에 대해서 더 자세한 내용은 구글 개발자 페이지를 참고하시기 바랍니다.
6. REST API 이슈
gRPC는 HTTP 2.0 기반위에서 동작하기 때문에 지금까지 HTTP 2.0의 특징에 대해서 살펴봤습니다. 짧게 정리하자면, Header 압축, Multiplexed Stream 처리 지원 등으로 인해 네트워크 비용을 많이 감소시켰습니다.
그렇다면 HTTP 2.0 특징을 제외한 gRPC만의 특징은 무엇이 있을까요? 먼저 REST API 통신의 문제점에 대해서 먼저 살펴본 다음 gRPC의 특징에 대해서 살펴보도록 하겠습니다.
1) JSON Payload 비효율
REST 구조에서는 JSON 형태로 데이터를 주고 받습니다. JSON은 데이터 구조를 쉽게 표현할 수 있으며, 사람이 읽기 좋은 표현 방식입니다. 하지만 사람이 읽기 좋은 방식이라는 의미는 머신 입장에서는 자신이 읽을 수 있는 형태로 변환이 필요하다는 것을 의미합니다.
따라서 Client와 Server간의 데이터 송수신간에 JSON 형태로 Serialization 그리고 Deserialization 과정이 수반되어야합니다. JSON 변환은 컴퓨터 CPU 및 메모리 리소스를 소모하므로 수많은 데이터를 빠르게 처리하는 과정에서는 효율이 떨어질 수 밖에 없습니다.
2) API Spec 정의 및 문서 표준화 부재
REST API를 사용할 때 가장 큰 고민은 API 개발자와 API를 사용자 간의 효율적인 커뮤니케이션 방법입니다. 가령 API가 어떻게 디자인 되었는지, 그리고 해당 속성은 어떤 값을 입력해야하는지에 대해 상호간의 이해가 필요합니다. REST를 사용한다면 이를 위해서 자체적인 문서나 Restdocs 혹은 Swagger를 통해서 API 문서를 공유합니다. 하지만 이러한 방식은 REST와 관련된 표준은 아닙니다.
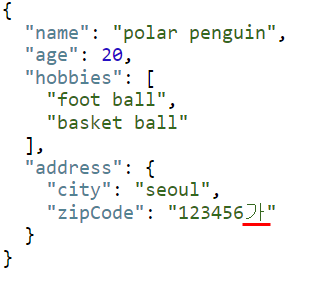
두 번째 이슈는 JSON 구조는 값은 String으로 표현됩니다. 따라서 사전에 타입 제약 조건에 대한 명확한 합의가 없거나 문서를 보고 개발자가 인지하지 못한다면, Server에 전달전에 이를 검증할 수 없습니다. 가령 위 예시와 같이 Server에서 zipCode는 숫자 타입으로 처리되어야하지만 Client에서는 이에 대한 제약 없이 문자열을 포함시켜 전달할 수 있음을 의미합니다.
그렇다면 gRPC 기술은 위 두 가지 이슈를 어떻게 풀어내었을까요?
7. gRPC Protobuf
Client에서 Server측의 API를 호출하기 위해서 기존에는 어떤 Endpoint로 호출해야할 지 그리고 전달 Spec에 대해서 API 문서 작성 혹은 Client와 Server 개발자간의 커뮤니케이션을 통해 정의해야했습니다. 그리고 이는 별도의 문서 생성이나 커뮤니케이션 비용이 추가로 발생합니다.
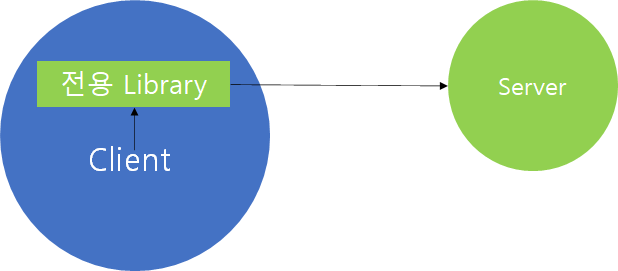
이러한 문제를 감소시키기 위해 다양한 방법이 존재합니다. 그 중 한가지는 Server의 기능을 사용할 수 있는 전용 Library를 Client에게 제공하는 것입니다. 그러면 Client는 해당 Library에서 제공하는 Util 메소드를 활용해서 호출하면 내부적으로는 Server와 통신하여 올바른 결과를 제공할 수 있습니다. 또한 해당 방법은 Server에서 요구하는 Spec에 부합되는 데이터만 보낼 수 있게 강제화 할 수 있다는 측면에서 스키마에 대한 제약을 가할 수 있습니다.
출처 : gRPC 공식 문서(https://grpc.io/docs/what-is-grpc/introduction/)
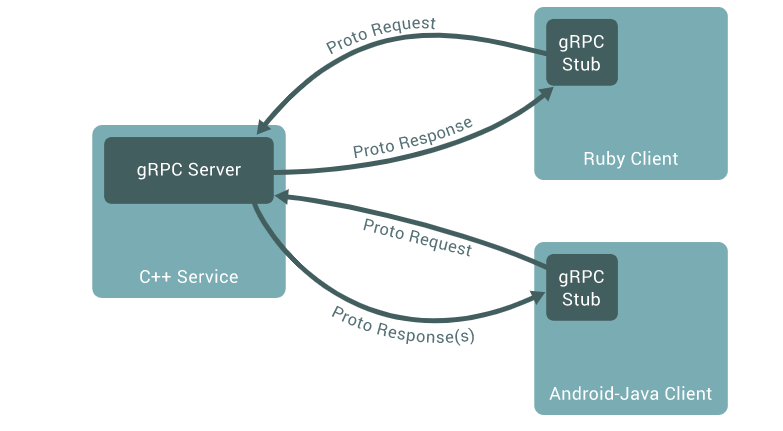
gRPC에서는 위 그림과 같이 이와 유사한 형태인 Stub 클래스를 Client에게 제공하여 Client는 Stub을 통해서만 gRPC 서버와 통신을 수행하도록 강제화 했습니다.
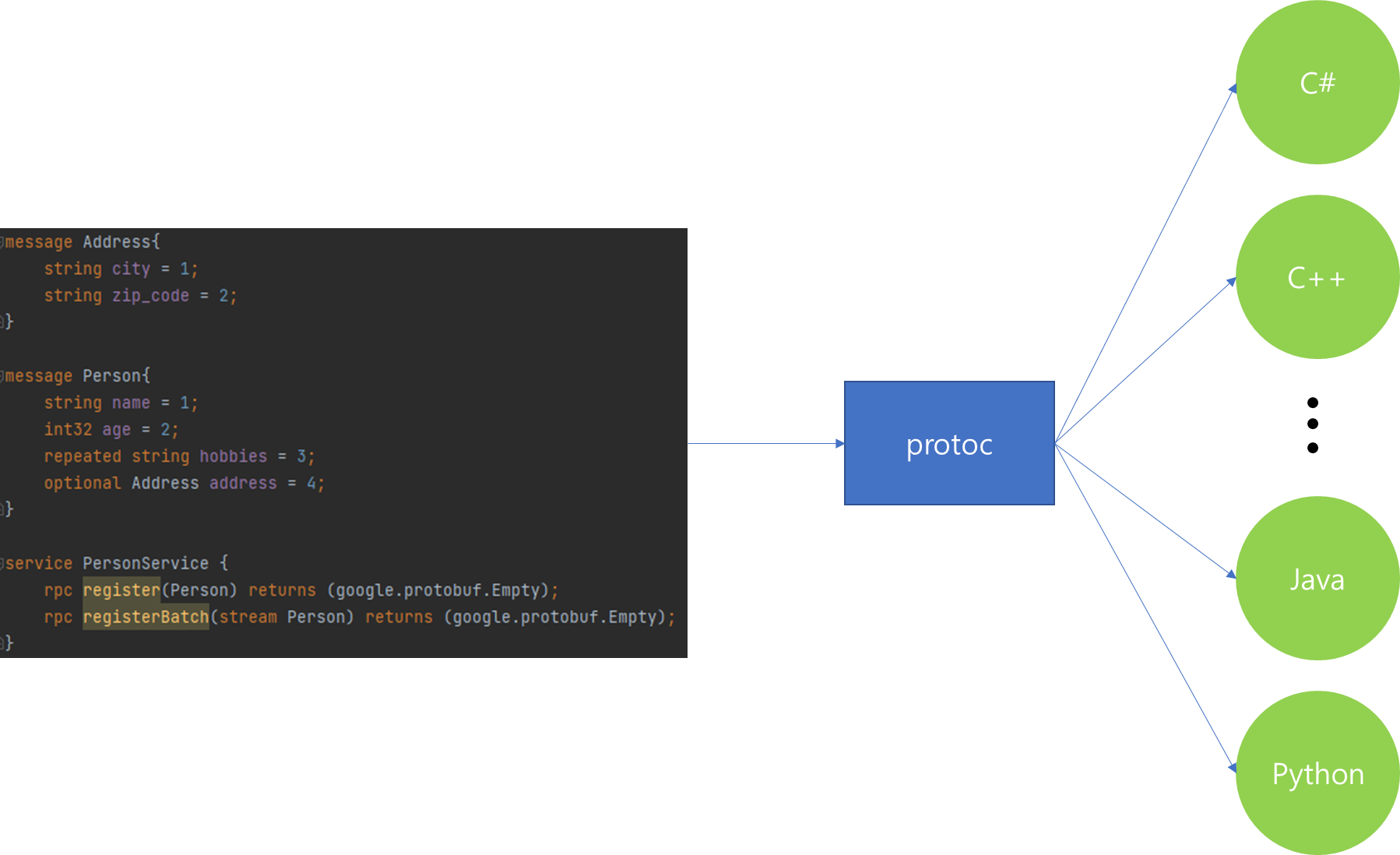
Protocol Buffer는 Google이 공개한 데이터 구조로써, 특정 언어 혹은 특정 플랫폼에 종속적이지 않은 데이터 표현 방식입니다. 하지만 Protocol Buffer는 특정 언어에 속하지 않으므로 Java나 Kotlin, Golang 언어에서 직접적으로 사용할 수 없습니다.
따라서 Protocol Buffer를 언어에서 독립적으로 활용하기 위해서는 이를 기반으로 Client 혹은 Server에서 사용할 수 있는 Stub 클래스를 생성해야합니다. 이때 protoc 프로그램을 활용해서 다양한 언어에서 사용할 수 있는 Stub 클래스를 자동 생성할 수 있습니다.
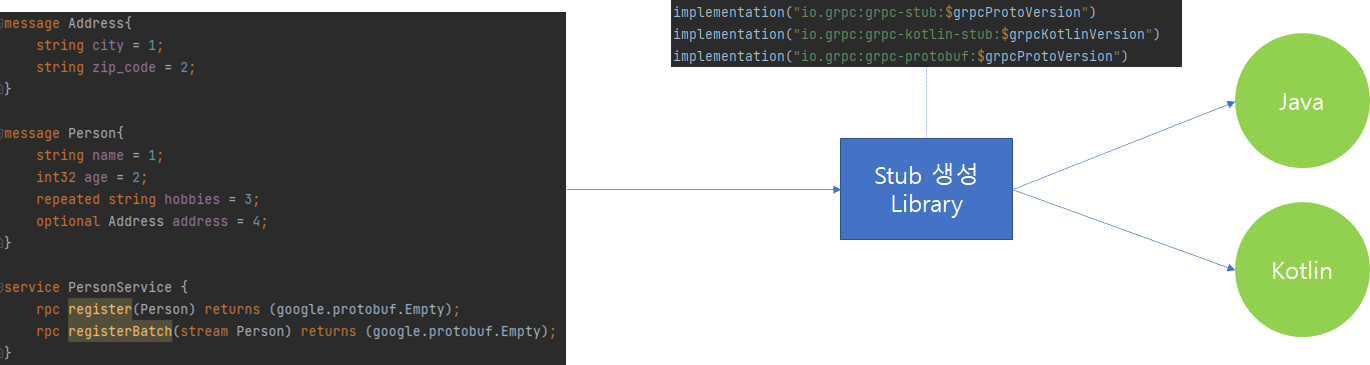
만약 Server가 Java 혹은 Kotlin 기반으로 구성되어있고 Client도 Java 혹은 Kotlin이라면, 위와 같이 Stub 생성을 자동으로 해주는 Library를 활용할 수 있습니다.
위 그림은 Library를 활용해서 Build 시점에 Proto 파일을 찾고 컴파일 단계에서 이를 분석해서 Stub 클래스를 자동으로 생성된 모습입니다.
Stub 클래스를 생성하면, 해당 클래스 정보를 Server와 Client에 공유한 다음 Stub 클래스를 활용하여 서로 양방향 통신을 수행할 수 있습니다.
위 코드는 Stub 객체를 활용하여 Client에서 특정 RPC를 호출한 모습입니다. REST 방식을 활용한다면 RestTemplate 혹은 Webclient나 Retrofit2와 같은 도구 활용해서 JSON으로 데이터를 전송해야합니다. 반면 gRPC 방법에서는 위와같이 Stub 객체에 정의된 메소드 호출을 통해서 Client/Server간 데이터 송수신을 수행할 수 있어 편리합니다.
지금까지 학습한 Protocol Buffer 내용을 정리하면 다음과 같은 장점을 지닌 것을 확인할 수 있습니다.
1. 스키마 타입 제약이 가능하다
2. Protocol buffer가 API 문서를 대체할 수 있다.
위 두가지 특징은 이전에 REST에서 다룬 이슈 중 하나인 API Spec 정의 및 문서 표준화 부재의 문제를 어느정도 해소해줄 수 있습니다. 그렇다면 또 하나의 이슈인 JSON Payload 비효율 문제와 대비하여 gRPC는 어떠한 이점을 지니고 있을까요?
JSON 타입은 위와같이 사람이 읽기는 좋지만 데이터 전송 비용이 높으며, 해당 데이터 구조로 Serialization, Deserialization 하는 비용이 높음을 앞서 지적했습니다.
gRPC의 통신에서는 데이터를 송수신할 때 Binary로 데이터를 encoding 해서 보내고 이를 decoding 해서 매핑합니다. 따라서 JSON에 비해 payload 크기가 상당히 적습니다.
또한 JSON에서는 필드에 값을 입력하지 않아도 구조상에 해당 필드가 포함되어야하기 때문에 크기가 커집니다. 반면 gRPC에서는 입력된 값에 대해서만 Binary 데이터에 포함시키기 때문에 압축 효율이 JSON에 비해 상당히 좋습니다.
결론적으로 이러한 적은 데이터 크기 및 Serialization, Deserialization 과정의 적은 비용은 대규모 트래픽 환경에서 성능상 유리합니다.
8. gRPC 단점
지금까지 gRPC에서 사용되는 기반 기술에 대해서 살펴봤습니다. gRPC는 MSA 환경에서 문제점인 네트워크 지연 문제를 어느정도 해결해 줄 수 있는 기술로써 점차 많은 곳에서 도입을 진행하고 있지만 다음과 같은 문제점 또한 존재합니다.
1) 브라우저에서 gRPC를 직접 지원 안함
현재 gRPC-WEB을 사용해서 직접 브라우저에서 서버로 gRPC 통신을 수행할 수 없습니다. 따라서 Envoy와 같은 Proxy 서버를 통해 요청을 Forwarding 해야합니다.
또 다른 방법으로는 gRPC 서버와 브라우저 사이에 Aggregator 서버를 별도로 두어 Aggregator와 브라우저간에는 REST 통신을 수행하고 Aggregator와 gRPC 서버간에 gRPC 통신을 수행하는 방법을 사용해야합니다.
2) Stub 관리 비용 추가
Client와 Server는 Stub 클래스를 통해 서로 통신을 수행합니다. 하지만 요구사항 변경으로인해 Stub 클래스 변경이 필요할 때 Server에서 변경한 내용을 Client에서도 적용을 해야합니다. 이 경우 버전 차이로 인한 하위 호환성 문제가 발생할 수 있기 때문에 서비스간 Stub 관리 방법을 정의해야합니다.
가장 많이 사용하는 방법으로는 Proto 파일을 중앙에서 gitops 형식으로 관리하고 변경이 생겼을 때 이를 감지하고 언어별로 컴파일하여 Stub 클래스를 라이브러리 형태로 배포하는 방법을 많이 사용합니다.
마치며
이번 포스팅에서는 gRPC가 MSA 환경에서 왜 대두되었는지 기존의 방식과 어떠한 차이점이 있는지에 대해서 간략하게 알아봤습니다. 다음 포스팅에서는 gRPC와 REST를 다각도로 비교해보면서 gRPC가 어떠한 장점이 있는지를 분석해보겠습니다.
이러한 문제를 어떻게 해결할 수 있을까 고민하던 와중 우아한 형제들 Excel 기술 블로그를 보고 영감을 얻어 Excel 업로드 라이브러리를 개발하기로 했습니다. 이번 포스팅은 개인 프로젝트로 진행한 라이브러리 설계 과정과 적용 기술 및 개발 당시 어려움을 겪은 내용을 다루겠습니다.
POI에서 제공하는 DOM과 SAX 방식은 구현 방법이 완전히 다릅니다. 그 이유는 제공하는 API도 다를 뿐더러 DOM 방식은 Pull 방식, SAX 방식은 Push 방식으로 Parsing 결과를 제공하기 때문입니다.
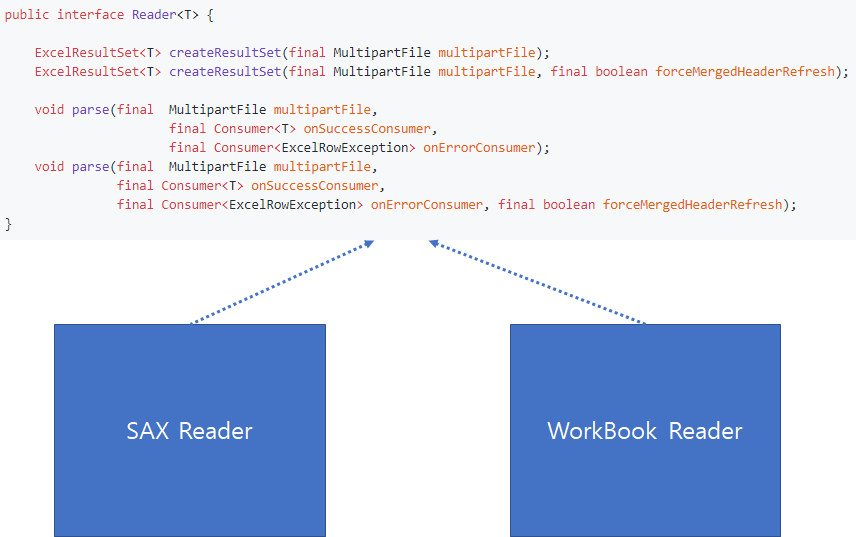
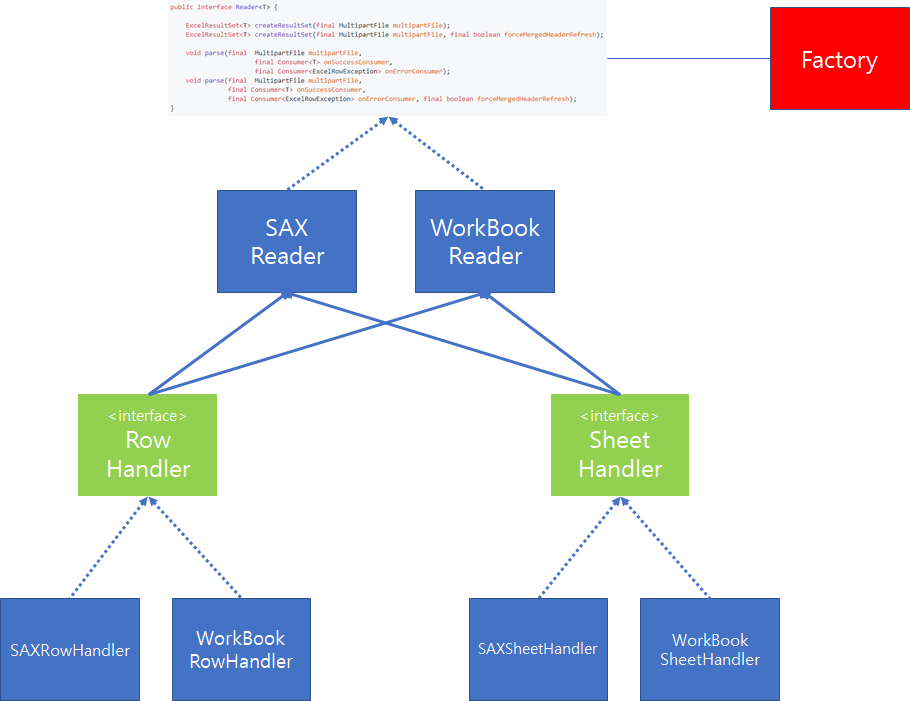
따라서, 먼저 이러한 두 가지 방법에 대해서 공통으로 처리할 수 있는 API를 설계하고 이를 Interface 제공하도록 구상하였습니다.
위와 같이 interface를 정의하면 사용자는 구현의 Detail은 알 필요없이 API 호출만으로 SAX 방식 혹은 DOM 방식으로 결과를 얻을 수 있습니다.
두번째는 Excel 파일에서 데이터를 Parsing하기 위해서는 Sheet에 대한 처리, 각각의 Row에 대한 처리가 필요합니다. 따라서, 이전과 마찬가지로 Row와 Sheet에 대한 각각의 inteface를 정의한 다음 각각의 Reader는 interface에 의존함으로써, 공통화된 기능을 제공할 수 있도록 설계했습니다.
public class ReaderFactory {
private final ExcelMetaModelMappingContext context;
public ReaderFactory(ExcelMetaModelMappingContext context) {
this.context = context;
}
public <T> Reader<T> createInstance(ReaderType type, Class<T> tClass) {
final boolean isCached = context.hasMetaModel(tClass);
if (type == ReaderType.WORKBOOK) {
return isCached ? new WorkBookReader<>(tClass, context.getMetaModel(tClass)) : new WorkBookReader<>(tClass);
}
return isCached ? new SAXReader<>(tClass, context.getMetaModel(tClass)) : new SAXReader<>(tClass);
}
public <T> Reader<T> createInstance(Class<T> tClass){
final ExcelBody entity = tClass.getAnnotation(ExcelBody.class);
return createInstance(entity.type(), tClass);
}
}
여기에, Factory 클래스를 추가하여 사용자가 Enum 값으로 SAX 혹은 DOM(WorkBook) 방식 중 하나를 지정하면, 그에 해당하는 Excel Reader를 생성하도록 추가하였습니다. 지금까지 설명한 내용을 도식화하면 위 그림과 같습니다.
2. Annotation 기반 메타 정보 작성
Excel로 읽는 각 Row 데이터는 결국 특정 Entity로 변환되어 DB에 저장되거나 비즈니스 로직에서 사용될 것입니다. 이러한 Entity를 POJO스럽게 유지하면서도 라이브러리에서 필요한 다양한 메타 정보를 기록할 수 있는 방법 중 하나는 @Annotation 활용입니다. Spring 환경에서 개발하면, 다양한 Annotation을 접하게 되는데, 라이브러리를 개발함에 있어서도 이러한 Annotation을 사용하여 Entity 클래스내에 라이브러리 코드가 직접 침투되지 않도록 설계하였습니다.
또한, Annotation을 사용함에 있어 JPA와 유사한 스타일을 적용하면, 학습곡선을 많이 낮출 수 있다고 생각하여 비슷하게 디자인했습니다.
사용자 코드에서 무엇을(What) 처리 해야할지 명시하고 어떻게(How) 처리해야할지는 기술하지 않았습니다. 즉 원하는 바만 선언하였으니, 라이브러리내에서 메타 정보를 읽어들여 사용자가 원하는대로 처리하고 반환 해야합니다.
Java에서는 Runtime 시점에 Reflection을 통해서 Instance 및 Class의 내부 정보를 알 수 있는 방법을 제공합니다. 따라서 이를 활용해서 라이브러리 내부에서 Annotation 분석 → 데이터 Parsing → Entity 생성 → 데이터 주입 → 데이터 Validation 검증 과정 순서대로 처리할 수 있도록 구상하였습니다.
위 4가지 단계에서 데이터 Parsing은 SAX Reader, WorkBook Reader가 담당하는 것을 이전 내용을 통해 확인했습니다.
따라서, Annotation 분석과, Entity 생성을 위해 이를 담당할 Class를 추가로 생성하였습니다.
ExcelEntityParser와 EntityInstantiator는 Reflection을 활용하여, Entity 내부를 탐색하는 과정을 담당합니다. Parser는 이 과정에서 Entity에 작성된 Annotation의 유효성 검증 및 헤더 정보 등을 취합하는 역할을 담당하고, Instantiator는 Entity를 생성하고, Parser에서 취합된 헤더 정보를 토대로 데이터를 주입하는 역할을 담당합니다.
public class ExcelEntityParser implements EntityParser {
...(중략)...
private void doParse() {
visited.add(tClass);
findAllFields(tClass);
final int annotatedFieldHeight = extractHeaderNames();
calcHeaderRange(annotatedFieldHeight);
validateHeaderRange();
calcDataRowRange();
validateOverlappedRange();
extractOrder();
validateOrder();
validateHeaderNames();
}
...(중략)...
private void findAllFields(final Class<?> tClass) {
ReflectionUtils.doWithFields(tClass, field -> {
final Class<?> clazz = field.getType();
if(field.isAnnotationPresent(ExcelConvert.class)){
final Class<?> converterType = field.getAnnotation(ExcelConvert.class).converter();
if(!converterType.getSuperclass().isAssignableFrom(ExcelColumnConverter.class)){
throw new InvalidHeaderException(String.format("Only ExcelColumnConverter is allowded. Entity : %s Converter: %s",this.tClass.getName(), converterType.getName()));
}
}
else if(instantiatorSource.isSupportedDateType(clazz) && !field.isAnnotationPresent(DateTimeFormat.class)){
throw new InvalidHeaderException(String.format("Date Type must be placed @DateTimeFormat Annotation. Entity : %s Field : %s ", this.tClass.getName(), clazz.getName()));
}
else if(!instantiatorSource.isSupportedInjectionClass(clazz) && visited.contains(clazz)){
throw new UnsatisfiedDependencyException(String.format("Unsatisfied dependency expressed between class '%s' and '%s'", tClass.getName(), clazz.getName()));
}
if (instantiatorSource.isSupportedInjectionClass(clazz)) {
declaredFields.add(field);
} else {
visited.add(clazz);
findAllFields(clazz);
visited.remove(clazz);
}
});
}
...(중략)...
}
public class EntityInstantiator<T> {
...(중략)...
public <R> EntityInjectionResult<T> createInstance(Class<? extends T> clazz, List<String> excelHeaderNames, ExcelMetaModel excelMetaModel, RowHandler<R> rowHandler) {
resourceCleanUp();
final T object = BeanUtils.instantiateClass(clazz);
ReflectionUtils.doWithFields(clazz, f -> {
if (!excelMetaModel.isPartialParseOperation()) {
instantiateFullInjectionObject(object, excelHeaderNames, excelMetaModel, f, rowHandler);
} else if (excelMetaModel.getInstantiatorSource().isCandidate(f)) {
instantiatePartialInjectionObject(object, excelHeaderNames, excelMetaModel, f);
}
});
if (excelMetaModel.isPartialParseOperation()) {
setupInstance(excelHeaderNames, excelMetaModel.getInstantiatorSource(), rowHandler);
}
return new EntityInjectionResult<>(object, List.copyOf(exceptions));
}
...(중략)...
private <U> void setupInstance(final List<? extends String> headers, EntitySource entitySource, final RowHandler<U> rowHandler) {
for (int i = 0; i < instances.size(); i++) {
if (Objects.isNull(instances.get(i))) continue;
Field field = instances.get(i).field;
Class<?> type = field.getType();
field.setAccessible(true);
String value = rowHandler.getValue(i);
try {
final Object instance = instances.get(i).instance;
if (!StringUtils.isEmpty(value)) {
inject(entitySource, field, type, value, instance);
}
validate(instance, headers.get(i), value, field.getName()).ifPresent(exceptions::add);
} catch (IllegalAccessException | ParseException e) {
addException(headers, field, value, e.getLocalizedMessage());
}
}
}
...(중략)...
}
Entity Parser와 Instantiator까지 적용되면, 라이브러리로 Excel Parsing 요청시, 위 흐름대로 처리되는 것을 이해할 수 있습니다.
삽질의 시작
이전 내용을 토대로 기본적인 구현을 마친 이후 테스트를 해보자 몇가지 추가 고민이 생겼습니다. 그리고 이것은 이후 시작되는 삽질의 첫삽을 푼 순간이었습니다.
고민거리
Entity에 지정된 Annotation 유효성 검증을 런타임에 수행하는데, Spring Boot 기동시점인 로드 타임에 검증하는 것이 더 좋지 않을까?
Maven Central에 배포해보자!!!
삽질 1. 대상 Entity 클래스 Scanning
Spring Boot 기동 시점에 검증을 하려면, Excel Parser 라이브러리의 대상 Entity를 모두 찾을 수 있어야 합니다. 따라서, Spring에서 Bean Scanning 하는 코드 및 관련 클래스를 사용해야겠다고 생각했지만 검색 능력의 부족으로 인해 찾는데 많은 어려움을 겪었습니다. 많은 시행착오 끝에 ClassPathScanningCandidateComponentProvider클래스가 해당 기능을 제공하는 것을 확인할 수 있었습니다.
ClassPathScanningCandidateComponentProvider provider = new ClassPathScanningCandidateComponentProvider(false);
provider.findCandidateComponents("base 패키지명");
삽질 2. Default base 패키지명은 어떻게 알 수 있을까?
ClassPathScanningCandidateComponentProvider 클래스를 통해 base 패키지명을 String 타입으로 전달하면, 하위 패키지내 클래스를 탐색하는 기능을 제공해줌을 알 수 있습니다.
여기서 한가지 의문이 들었습니다.
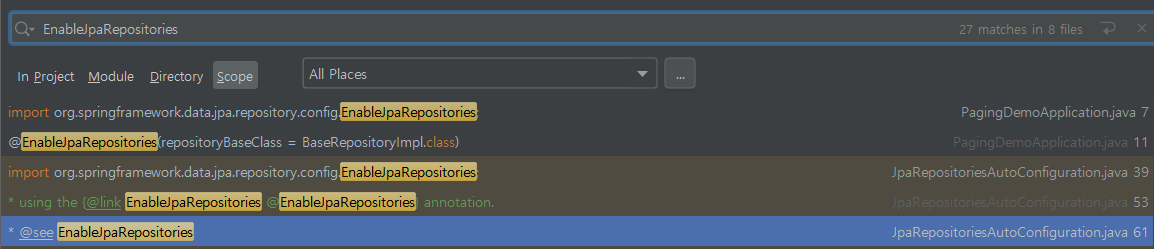
'Spring Data JPA에서는 @EnableJpaRepositories Annotation을 통해 basePackages를 입력하지 않아도 Repository Bean을 만들 수 있었는데, 어떤 원리로 그런것일까? '
이것을 알기위해 구글링을 해봤지만, 어떠한 keyword로 검색해야할지 몰라 정확한 정보를 찾을 수 없었습니다.
(대부분 @EnableJpaRepositories 설정 방법이나 basePackage를 지정하는 방법 관련된 검색결과가 대다수였습니다.)
결국, 선택한 방법은 코드내 EnableJpaRepositories 부터 시작해서 관련된 클래스 Debugger를 걸어놓고 코드를 따라 거슬러 오르는 방법이었습니다.
EnableJpaRepositores 검색결과
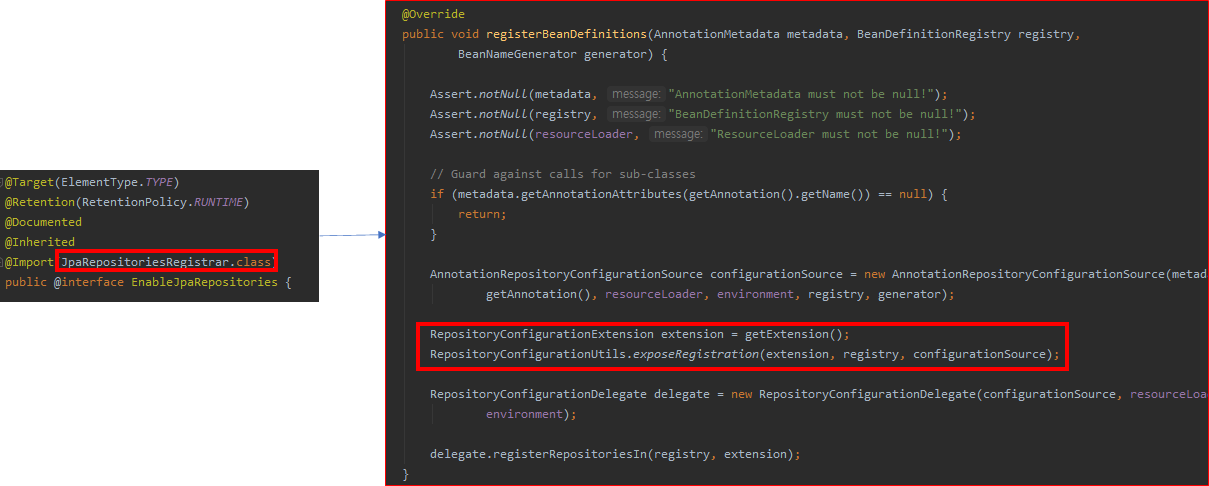
추적끝에 찾은 결과는 위와 같습니다. @EnableJpaRepositories 어노테이션을 Configuration 클래스에 선언하면, JpaRepositoriesRegistrar 클래스 정보가 같이 Import 됩니다. 이때, JpaRepositoryConfigExtension 클래스가 Bean으로 등록됩니다. 그리고 RepositoryConfigurationDelegate에게 Bean 탐색을 위임합니다.
이때, basePackages를 설정하게 되는데, 사용자가 지정한 @EnableRepositories Package 정보를 가져와서 지정합니다.
JpaRepositoriesAutoConfiguration은 JpaRepository 관련 자동설정을 하는데, JpaRepositoryConfigExtension 클래스가 Bean으로 등록되어있으면, 관련 자동설정을 하지 않습니다. @EnableJpaRepositories Annotation을 사용자가 지정했다면, 이전에 설명했듯이, JpaRepositoryConfigExtension가 Bean으로 등록되었기 때문에 자동설정을 하지 않습니다.
반면 @EnableJpaRepositories Annotation이 존재하지 않는다면, 마찬가지로 RepositoryConfigurationDelegate에게 Bean 탐색을 위임합니다. 이때 사용되는 basePackges는 AutoConfigurationPackages.get 메소드를 통해 얻을 수 있습니다. 그리고 해당 메소드가 바로 Spring Boot에서 사용되는 기본 basePackges 정보임을 알 수 있었습니다.
삽질 3. JPA는 되는데 난 안돼!!!
Spring Data JPA에서 사용되는 자동설정 Idea를 토대로 개발중인 라이브러리에 적용하기로 했습니다.
@EnableExcelEntityScan Annotation과 AutoConfiguration 클래스를 만들어서 사용자가 Annotation을 지정하여 basePackage를 지정하지 않으면 AutoConfiguration의 설정을 따르도록 했습니다.
하지만 아무리 AutoConfigurationPackages.get 메소드를 호출해도 Bean 정보가 없다는 Exception이 발생하였습니다.
처음에는 AutoConfigurationPackages.get가 아니라 혹시 다른 메소드가 이를 대신하나 싶어서 샅샅히 찾아봤지만 코드상에서는 찾을 수 없었습니다.
그렇게 한참을 삽질하다 문득 spring.factories에 EnableAutoConfiguration 설정을 하지 않았음을 알게 되었고, 설마 이것때문에? 라는 생각으로 관련 AutoConfiguration 클래스를 등록시켰습니다.
그 결과, 설정 이후에 정상적으로 basePackage 정보를 가져오는 것을 확인하고 많이 부족함을 재차 느꼈습니다.
삽질 4. Gradle기반 Spring Boot Starter 만들기
Spring Boot Starter 관련하여, Maven 기반으로 Starter를 작성하는 방법에 대해서는 다수 있지만, Gradle로 만드는 방법은 찾기 어려웠습니다. 다만 Spring Boot Starter 개념은 아래 링크에 참고된 블로그를 통해서 학습할 수 있었습니다. 한참의 삽질끝에 완성할 수 있었습니다.
운이 좋게 저보다 앞서 고생하시고 그 기록을 남겨주신 siyoon210님 블로그를 통해서 다른 과정과 비교했을 때 큰 문제 없이 업로드할 수 있었습니다.
마치며
숲을 제대로 모른 상태에서 나무만 보면서 만들다보니 삽질이 많았습니다. 하지만 그런 시행착오를 겪으면서 배워서 그런지 학습한 내용이 보다 오랫동안 기억에 남을 것같습니다. 공식 문서에 사용법에 대해서 작성했으나 나중에 기회가된다면 튜토리얼 포스팅을 작성해볼까 합니다. 관련된 자료는 아래 링크를 참고하시기 바랍니다.
이전 포스팅에서 Redis의 기본적인 구조와 복제(Replication)에 대해서 살펴봤습니다.
잠시 복기해보자면, 복제는 Master의 데이터를 Replica에 모두 저장하여 가용성과 읽기 작업의 성능을 높일 수 있습니다.
하지만 데이터 양이 폭발적으로 증가한다면 어떻게 될까요?
Replication은 모든 데이터를 복제해야하기 때문에 단일 서버에서 저장 가능한 Memory를 초과하면 이를 복제할 수 없습니다. 따라서 메모리 증설등을 통한 Scale-Up 만으로 데이터 저장 공간을 확보할 수 없다면 다른 방법이 필요합니다.
이번 포스팅에서는 데이터 분산을 통해 고가용성을 확보할 수 있는 파티셔닝 개념과 Redis에서 사용되는 샤딩전략 그리고 Cluster에 대해 다루도록 하겠습니다.
1. 파티셔닝 개념
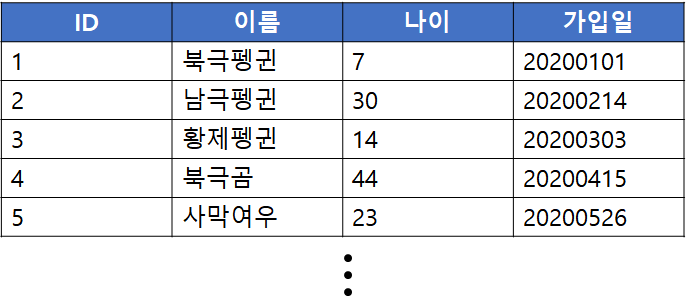
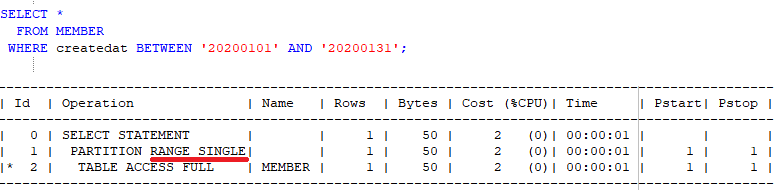
파티셔닝은 DB의 관리 용이성 및 읽기 최적화를 위해 논리적인 테이블의 물리 구조를 여러개의 파티션(Partition)으로 분할하여 분산 저장하는 기법을 말합니다. 파티셔닝 개념에 대한 이해를 돕기위해 잠시 RDBMS에서의 파티셔닝에 대해서 간략하게 알아보겠습니다.
위 그림과 같은 회원 테이블이 존재한다고 가정해봅시다. 이때 가입자가 매일 증가하여 테이블 크기가 점점 커진다면, 해당 테이블에 조회 성능을 높이기 위해 인덱스 추가등의 작업이 쉽지 않을 뿐더러 점차 조회 성능도 떨어지게 됩니다.
가령 수십억건의 데이터가 존재하는 테이블에서 매월마다 가입일이 5년지난 데이터를 삭제해야 한다면 어떻게 해야할까요?
데이터를 지우기 위해서 수십억건의 테이블을 탐색하면서 조건에 해당하는 데이터를 삭제해야합니다. 이렇게 되면 오랜시간동안 Lock으로 인해 동시성 저하가 발생할 수 있으며, 테이블 크기가 점점 더 커질 수록 해당 작업은 어려워질 것입니다.
설령 가입일에 인덱스가 생성되어있다 할지라도 디스크 Random I/O로 인해 좋은 성능이 나오지 않을 뿐더러 데이터 지속 삭제로 인해 인덱스 Sparse 현상이 발생할 수 있습니다.
따라서, 이러한 경우 사용자에게 논리적으로 보여지는 테이블은 하나이지만 기저에 물리적으로는 여러 파티션에 데이터를 나누어 저장한다면, 조회 성능 향상 및 관리가 용이해집니다.
위 그림은 가입일 기준으로 20년 1월에 발생한 데이터는 202001 파티션에 저장하도록 하였고, 2월에 가입한 회원들은 202002 파티션에 저장되도록 파티션을 구성하였습니다.
이와같이 가입일 기준으로 파티션을 구성하면 다음과 같은 이점이 있습니다.
만약 매월 가입일 기준으로 사용자를 삭제한다면, 기존에는 테이블내 모든 데이터를 탐색해야했지만 지금은 특정 월에 해당하는 파티션만 Drop(DDL 작업) 하면 되므로 작업 부담이 줄어듭니다.
그리고 특정 월에 해당하는 데이터를 조회할 때, 해당 파티션에 속한 데이터에 대해서만 Multi block I/O를 실시할 수 있기 때문에 인덱스를 사용하는 방법보다 빠른 조회가 가능할 수 있습니다.
정리하자면 파티셔닝은 위 사례와 같이 대용량의 논리적 구조를 여러 물리적인 파티션으로 분할하여 조회 및 관리 용이성을 위해 사용됩니다.
2. 파티셔닝 종류
이번에는 파티셔닝 종류에 대해서 알아보겠습니다. 파티셔닝은 수직적 파티셔닝과 수평적 파티셔닝 2가지 종류가 있습니다.
수평적 파티셔닝은 이전 파티셔닝 개념에서 살펴보았듯이, 특정 데이터(가입일) 기준으로 데이터를 다른 파티션에 저장하는 방법을 말합니다.
반면, 수직적 파티셔닝은 특정 컬럼을 기준으로 데이터를 분할하는 방법을 말합니다. 위 그림과 같이 기존 회원 테이블을 특정 컬럼을 기준으로 2개의 파티션으로 분할한 경우가 이에 해당됩니다.
수직적 파티셔닝의 이점은 한쪽 세그먼트에서 발생하는 DML이 다른쪽에 영향을 끼치지 않습니다. 반면, 레코드 전체 데이터를 읽어야할 경우에는 데이터가 물리적으로 분산되었으므로 I/O에서 다소 비효율이 발생합니다.
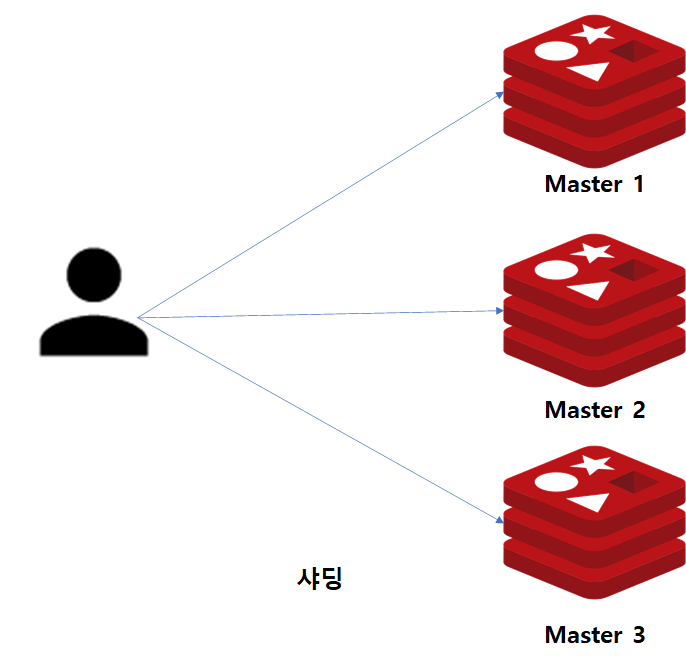
그렇다면, NoSQL 제품군에서 주로 사용되는 샤딩(Sharding)은 무엇일까요?
샤딩이란 수평적 파티셔닝의 한 종류입니다. 수평적 파티셔닝과 비교하여 다른점은 파티셔닝은 단일 DBMS내에서의 데이터 분할 정책이고, 샤딩은 분할된 여러 데이터베이스 서버로 데이터를 분할하는 방법입니다.
따라서, 샤딩을 구성하게되면 샤드의 수만큼 노드가 존재하며, 서버가 여러대 존재하므로 부하를 적절히 분산할 수 있는 장점이 있습니다.
지금까지 파티셔닝 종류에 대해서 알아봤습니다. 용량을 고려하여 데이터 크기를 분할할 때, 수직적 파티션보다는 수평적 파티션이 분배에 용이하므로 이후 내용은 수평적 파티셔닝 전략을 기준으로 작성하였음을 참고바랍니다.
3. 파티셔닝 전략
이전에 살펴본 예제는 가입일 컬럼 대상 특정 월을 기준으로 데이터 파티션을 나누었습니다. 이때 특정 범위를 기준으로 데이터를 분할한 파티션을 Range 파티션이라고 합니다.
Range 파티셔닝의 장점은 논리적인 범위의 분산에 효율적입니다. 또한, 원하는 데이터가 특정 파티션에 모여있어 관리하기가 용이합니다.
이렇듯 사용자가 원하는대로 데이터를 분산시킬 수 있는 장점이 있지만 다음과 같은 문제점을 지니고 있습니다. 사례를 통해 Range 파티션의 문제점을 알아보겠습니다.
만약 대한민국 전체 국민의 개인정보를 관리하는 시스템 테이블에서 사람들의 나이 10살 범위 기준으로 Range 파티셔닝 했다고 가정해보겠습니다.
출처 : 국가 통계 포털 20년 7월 기준 대한민국 인구 통계
차트를 통해 알 수 있듯이 50대 파티션에 가장 많은 데이터가 적재되며 파티션별로 데이터 편차가 크게 나는 것을 확인할 수 있습니다.
이를 통해 알 수 있는 사실은 Range 파티셔닝의 가장 큰 문제점은 데이터 분포도가 고르지 못할 경우 데이터 배분을 균등하게 할 수 없습니다.
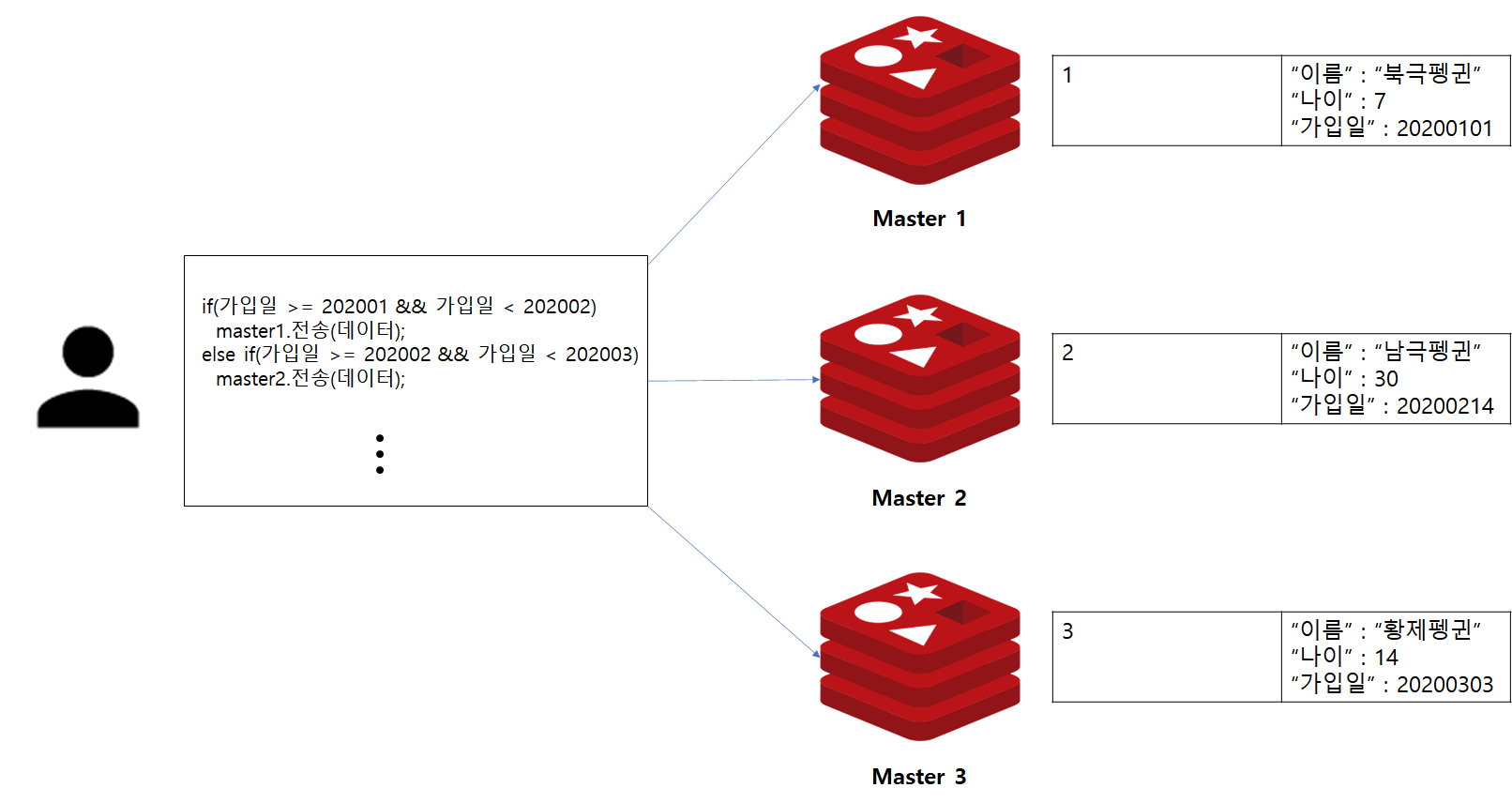
지금까지 RDBMS 테이블 구조로 Range 파티션 구조를 살펴보았습니다. 만약 Redis로 회원 데이터를 샤딩하면 어떤 모습일까요?
대략 위 그림과 같이 전체 데이터를 특정 범위로 나뉘어 각각의 Master 서버에게 할당할 것입니다. 그리고 범위에 따른 파티션 지정의 책임은 Client에게 있는 것을 확인할 수 있습니다.
이처럼 Redis에서의 샤딩 전략은 RDMBS 파티셔닝과 차이가 존재합니다.
RDBMS의 경우에는 테이블 생성시, 파티션 전략을 지정하면, 이후 데이터 입력이나 조회가 필요할 경우에는 테이블을 대상으로 입력/조회 작업을 수행합니다. 그러면 옵티마이저가 적당한 파티션으로 분배할 것입니다.
하지만 Redis에서 파티셔닝 전략을 사용하려면 데이터 분배 책임은 Client에게 있습니다. 다시말해 이는 Client에서 데이터를 어디에 저장할지혹은 데이터를 어디서 찾아야할지를 정해야함을 의미합니다.
Range 파티셔닝의 경우에는 특정 범위와 이에 해당하는 Master 노드를 매핑시키는 Mapping 테이블이나 Client 로직에 범위를 지정하여 분배하는 로직이 들어가야 합니다. 또한 데이터를 균등하게 분배하기 위해서는 철저한 전략 수립이 필요합니다.
결론적으로 Range 파티셔닝을 구현하는 것은 꽤 번거로운 일입니다. 공식 홈페이지에서 해당 내용에 대해서 다루고 있으며, 데이터 균등 분배를 위해 다음에 설명할 해시 파티셔닝 전략을 사용하는 것을 권하고 있습니다.
해시 파티셔닝
Redis에서 샤딩을 구현하기 위해서는 데이터를 서버별로 균등하게 분포해야 부하를 고르게 분산할 수 있습니다. 따라서 Range 파티셔닝은 데이터가 고르게 분포되지 못하므로 적절하지 못합니다. 이번에는 해시 파티셔닝을 통해서 데이터를 균등분배 하는 방법에 대해서 알아보겠습니다.
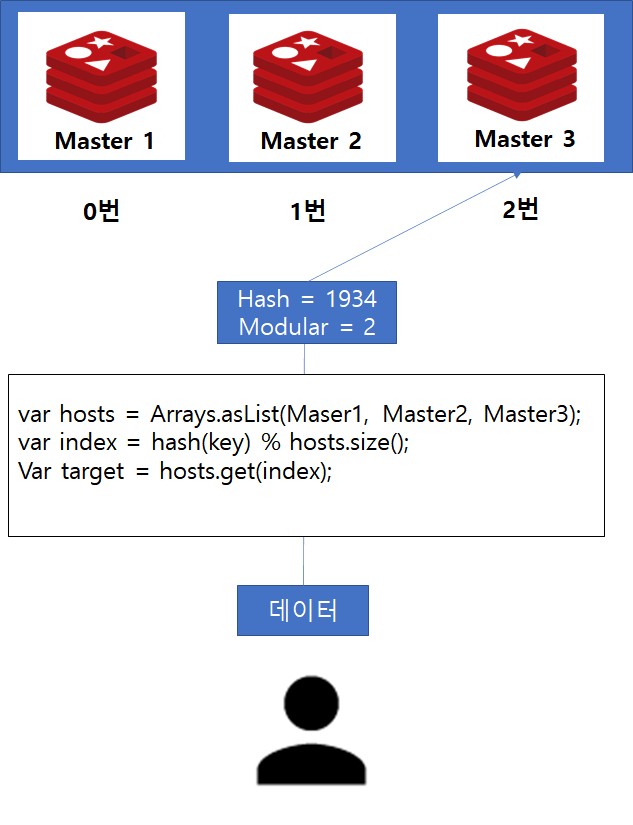
해시 파티셔닝은 Redis의 Key값에 대하여 해시함수를 적용한 결과를 Redis Master의 개수만큼 나머지 연산을 토대로 데이터를 저장할 Master 서버를 지정하는 방법입니다.
다음과 같이 hash 함수를 적용한 다음 Modulo 연산을 통해서 데이터를 저장하거나 찾아야할 Redis 노드를 지정할 수 있습니다.
var hosts = {Master1, Master2, Master3, ... }
var index = hash(key) % hosts.length;
예를들어 Master 서버가 3대가 있고, 이를 배열로써 담았다고 가정합시다.
그러면 master1번은 0번 인덱스, master2는 1번 인덱스, master3은 2번 인덱스가 될 것입니다.
이때, Redis Key에 대하여 hash 함수를 적용한 결과가 1934라면 1934 % 3(서버 개수) 의 결과인 2에 해당하는 Master 3노드가 해당 Key의 저장소가 되며, 데이터를 조회할 때도 Client는 해당 저장소에서 데이터를 찾으려고 할 것입니다.
해시파티셔닝의 경우에는 Modulo 연산을 통해 데이터의 분포여부와 상관없이 고르게 분포시킬 수 있는 장점이 있어 주로 사용되는 전략입니다.
Rebalancing 문제
지금까지 Redis의 샤딩, Range 파티셔닝의 문제점 및 해시 파티셔닝을 통한 데이터 균등 분배 방법에 대해서 살펴봤습니다.
만약 해시 파티셔닝이 적용된 상황에서 데이터 용량이 더욱 커져 Master 서버 추가를 해야한다면, 어떤 이슈가 존재할까요? 사례를 통해서 알아보겠습니다.
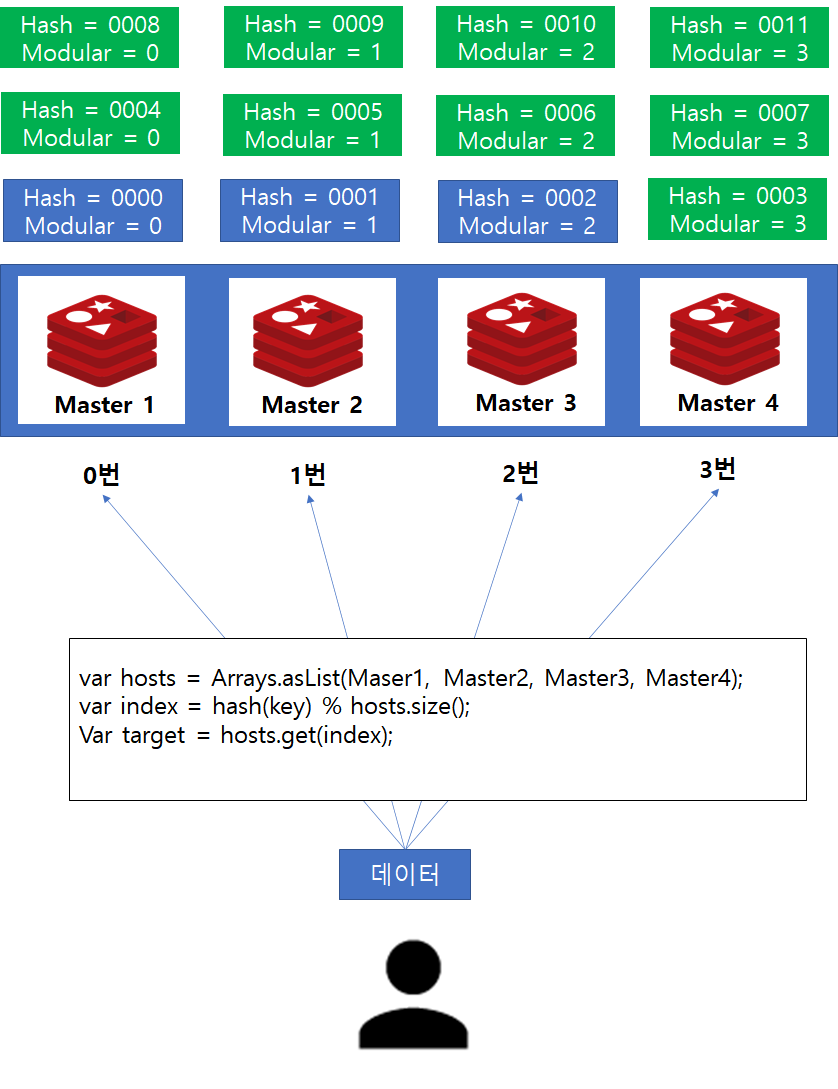
위 그림과 같이 현재 총 12개의 데이터가 3개의 Master 서버에 고르게 분배되어있다고 가정해봅시다. 위와 같은 상황에서 Hash 함수 결과가 9를 저장하고 있는 Master는 9 % 3(서버 대수)에 의하여 Master 1번이 선택될 것이고 Client는 해당 연산을 통해서 Master1번에게 질의할 것입니다.
이러한 상황에서 Master4를 새롭게 추가한다고 가정해봅시다.
위와 같은 상황에서 기존과 같이 Hash 함수 9의 결과를 가지고 있는 Redis 서버를 찾고자하면 어떤일이 발생할까요?
서버의 개수가 증가하였으므로 9 % 4 = 1이되어 엉뚱한 서버에 질의 하는 결과를 낳게 됩니다.
따라서, 서버를 추가할 경우에는 그에 맞게 데이터의 재분배(Rebalancing) 작업이 필요합니다.
그럼 데이터 재분배를 진행한 결과를 살펴보겠습니다.
위 그림에서 초록색으로 표기된 데이터는 원래 노드에서 새로운 노드로 재분배된 데이터를 의미합니다.
이를 통해서 알 수 있는 사실은 Master 노드 추가 이후 75%의 데이터가 재분배 작업을 통해 다른 노드로 이전하였음을 확인할 수 있습니다. 이는 데이터를 재분배하는 과정에서 굉장히 많은 부하가 발생할 수 있으며, 운영중에 노드 추가 작업이 자유롭지 못함을 의미합니다.
따라서 단순 Modulo를 적용한 해시파티셔닝 전략으로는 신규 노드 추가/삭제 작업으로부터 자유롭지 못합니다.
그렇다면 어떻게 하면 데이터 재분배 작업을 최소화할 수 있을까요?
Consistent Hashing
이전에 살펴보았듯이, 노드 추가에 따른 Rebalancing 부하를 줄이기 위해서는 재분배되는 데이터 양이 적어야 합니다.
Consistent Hashing 기법은 데이터와 더불어 Master 서버에 대하여 동일한 해시 함수를 적용하고, Master 서버 해시값 구간에 해당되는 데이터를 저장하는 방법입니다.
예를 들어 설명하겠습니다.
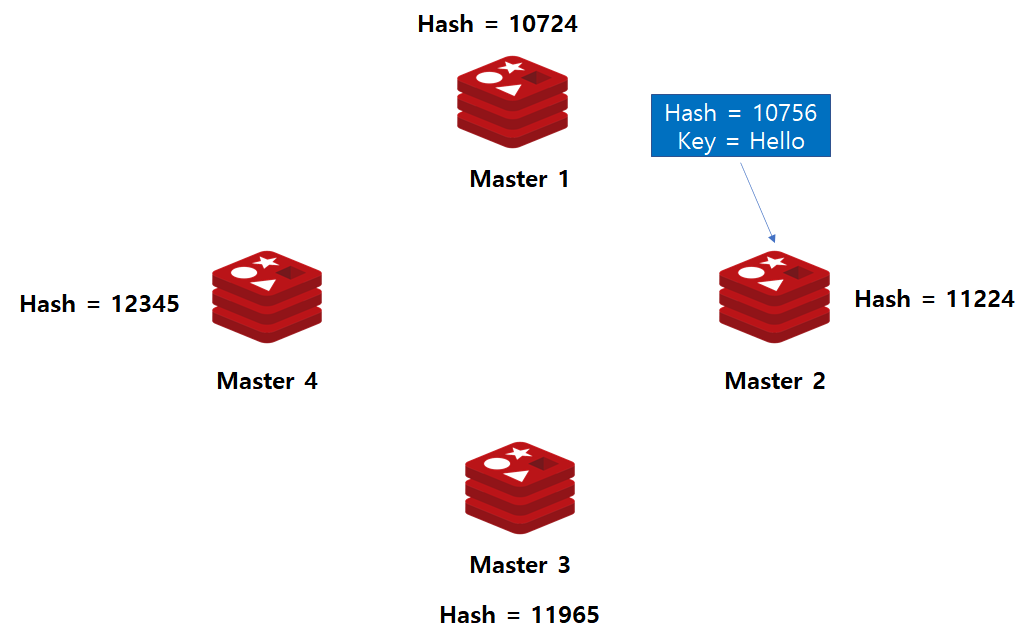
위 그림과 같이 Redis Master 노드에 대하여 해시함수를 적용합니다.
그리고 해시함수 결과를 기준으로 데이터를 처리할 Master 노드를 결정합니다.
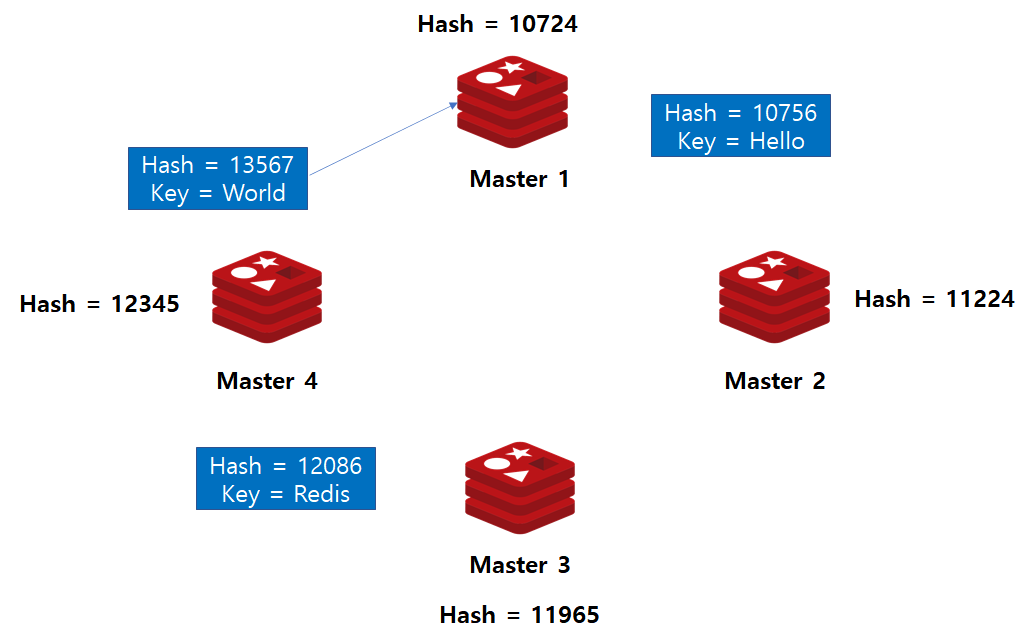
노드
데이터 담당 범위
Master1
해시값 <= 10724 OR 해시값 > 12345
Master2
10725 < 해시값 <= 11224
Master3
11224 < 해시값 <= 11965
Master4
11965 < 해시값 <= 12345
Case 1. 해시값 10756 데이터 입력시
Redis Master 서버에 대하여 해시 함수가 적용된 상황에서 해시 값이 10756인 데이터가 입력되었다고 가정해봅시다.
이는 10724보다는 크고 11224보다는 작으므로 Master2 노드가 해당 데이터의 저장소로 선정됩니다.
Case 2. 12086 해시값 데이터 입력시
12086 해시값 데이터가 입력되면, 12345 보다 작고 11965보다 크므로 Master4 노드가 해당 데이터의 저장소가 됩니다.
Case 3. 13567 해시값 데이터 입력시
12345보다 큰 값이 입력되었으므로, 해당 데이터의 저장소는 Master 1번이 됩니다.
Case 4. 5576 해시값 데이터 입력시
10724보다 작은 데이터가 입력되었으므로 해당 데이터의 저장소는 Master 1번이 됩니다.
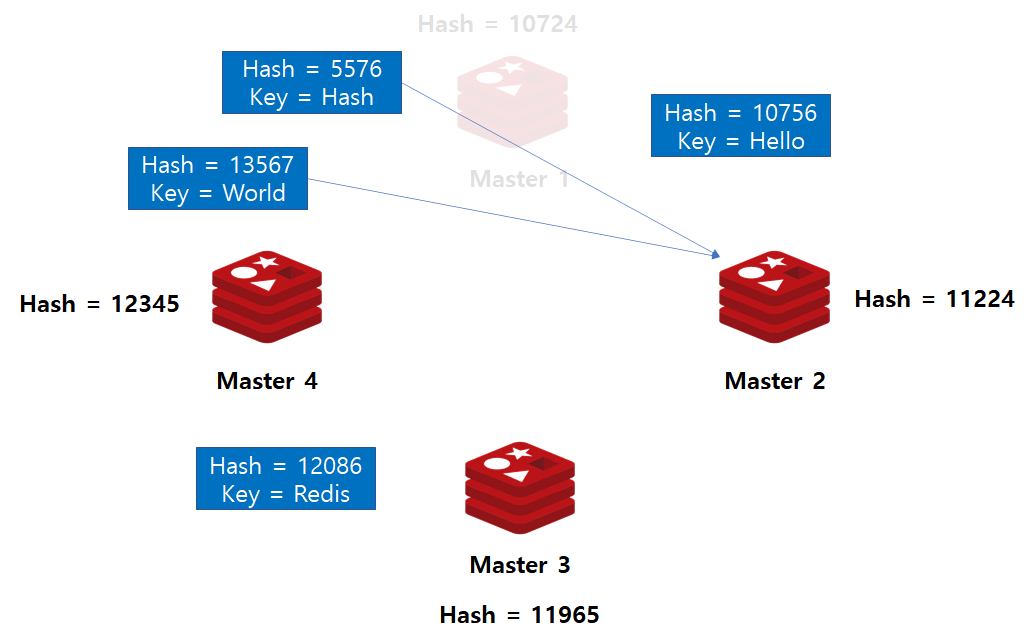
이렇듯 Consistent Hashing 기법에서는 서버를 추가하면 해시 함수를 적용하여 Hash Ring 형태로 만듭니다. 이후 입력되는 데이터는 해시 값 결과에 따라 저장소가 결정됩니다.
그렇다면 위와 같은 상황에서 노드가 삭제되거나 추가될 때 효율적인 Rebalancing이 일어날까요? Master 1 노드를 제거하는 상황을 가정해보겠습니다.
Master1 노드 삭제로 인해 Master1 노드가 가지고 있던 데이터를 재분배 해야하는 상황입니다. 따라서, 지금 상황에서는 Master2 노드가 Master1 노드의 데이터를 전부 이관 받아야하는 상황이며, 이는 효율적으로 데이터 재분배가 일어났다고 보기 힘듭니다.
그렇다면, 어떻게 해야 데이터를 효율적으로 나눌 수 있을까요?
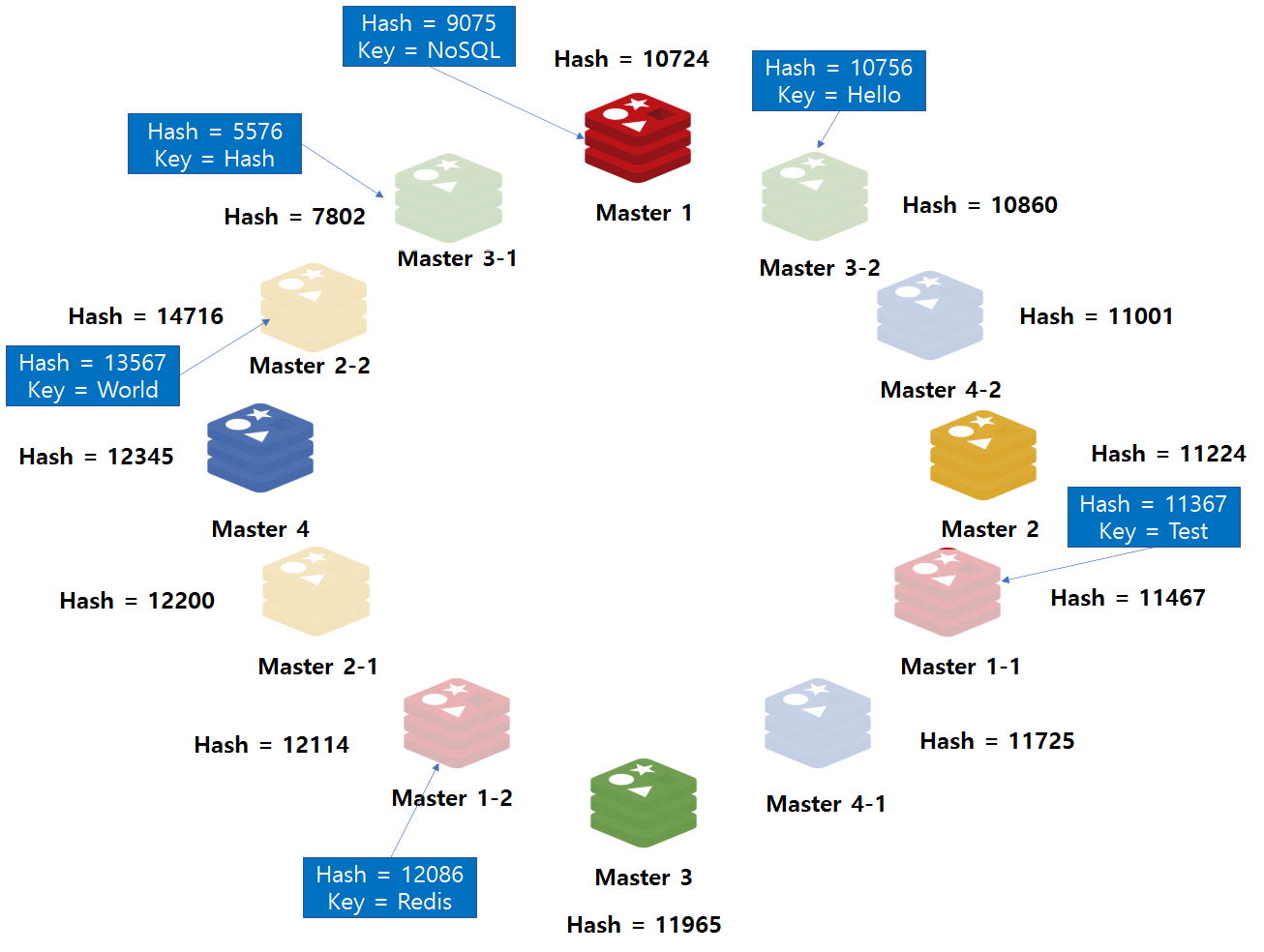
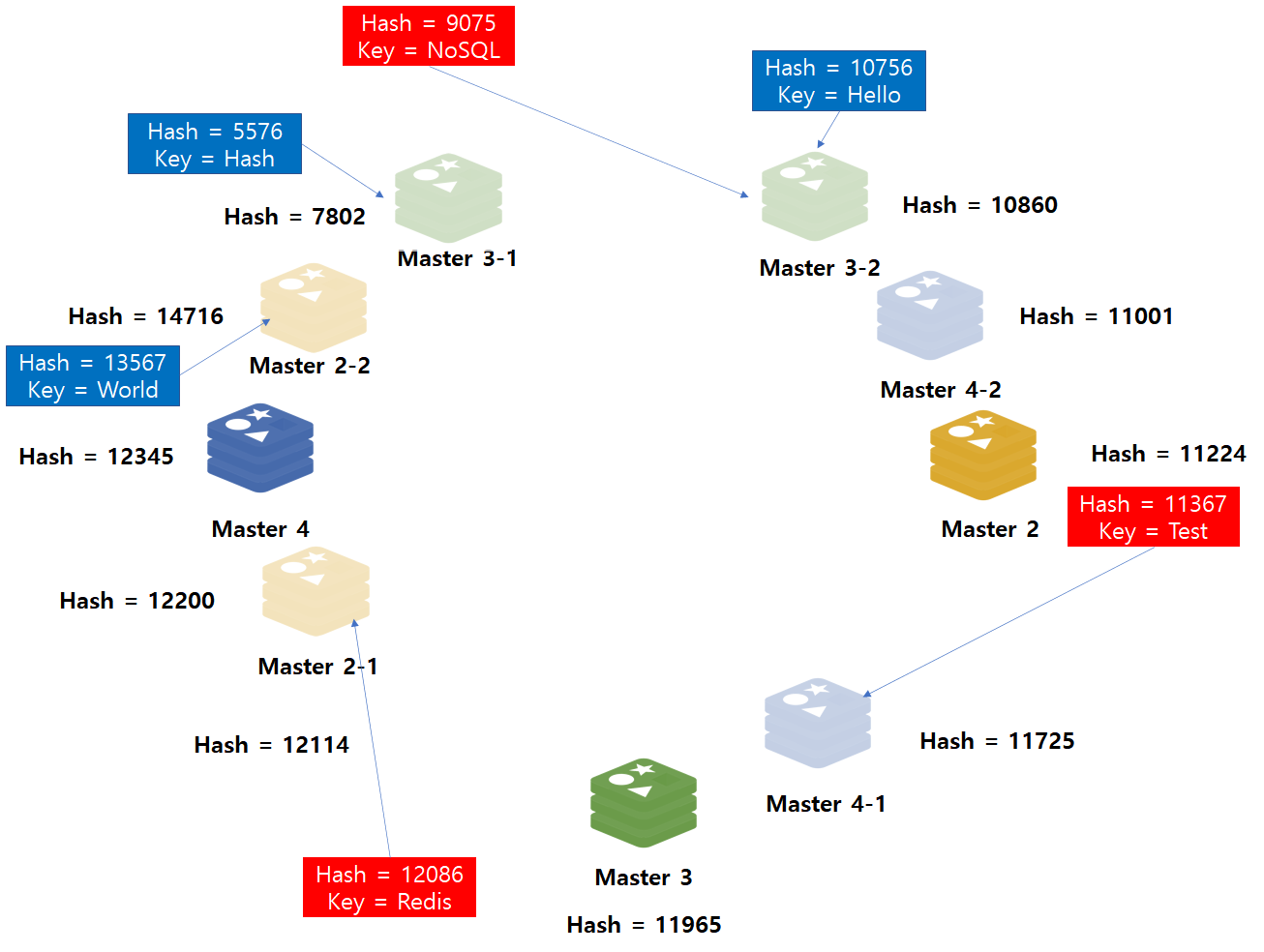
가상 노드 추가
Hash Ring에 단일 노드만 배치하니까 발생한 문제는, 노드를 제거했을 때, 인접해있는 다른 노드 하나에 모든 데이터를 이관해야하는 문제점이 있습니다. 따라서 이를 해소하는 방법은 Hash Ring에 여러 가상 노드를 배치하는 것입니다.
위와 같이 하나의 노드가 아니라 여러개의 가상 노드를 Hash Ring에 배치하면, 노드와 데이터사이 해시 값 범위가 좁아집니다. 따라서 이런 상황에서 Master1 노드를 제거하면, 해당 노드의 데이터가 다른 노드로 적절히 분배될 수 있습니다.
위 사례는 Master1번 노드가 삭제된 이후 Master1번 노드가 가지고 있었던 데이터(빨간색 음영)가 다른 노드로 적절히 분산되었음을 확인할 수 있습니다.
만약, 노드를 추가할 경우에는 특정 노드가 담당하고 있던 적은 범위의 데이터 영역을 재분배합니다.
정리하자면, 해시 파티셔닝을 사용함으로 인하여 데이터를 균등하게 분포하면서, 데이터 재분배에 대한 영향도를 최소화 하기 위해서 Consistent Hashing 알고리즘을 이용할 수 있습니다. Consistent Hashing 알고리즘을 사용시 고려 사항은 Hash Ring에 가상 노드를 촘촘하게 그리고 노드가 간격을 균일하게 배치할 수 있도록 Hash 알고리즘이 적용되야 합니다. 특정 노드간의 범위가 벌어지게된다면, 그만큼 재분배해야할 데이터 양이 많아지므로 이를 유의해야 합니다.
지금부터 다룰 Redis 시리즈는 개인 공부 내용 정리 목적으로 작성하였습니다. 주요 포스팅 내용은 redis-cli 명령어 학습과 Spring Data Redis를 활용해서 해당 명령어 적용방법에 대해서 살펴보겠습니다.
이번 포스팅은 Redis를 다루는 첫 포스팅으로 Redis 구조에 대해서 개략적으로 살펴보겠습니다. 전문지식을 기반으로 작성한 내용이 아닌만큼 틀린 부분이 있다면 피드백 부탁드립니다.
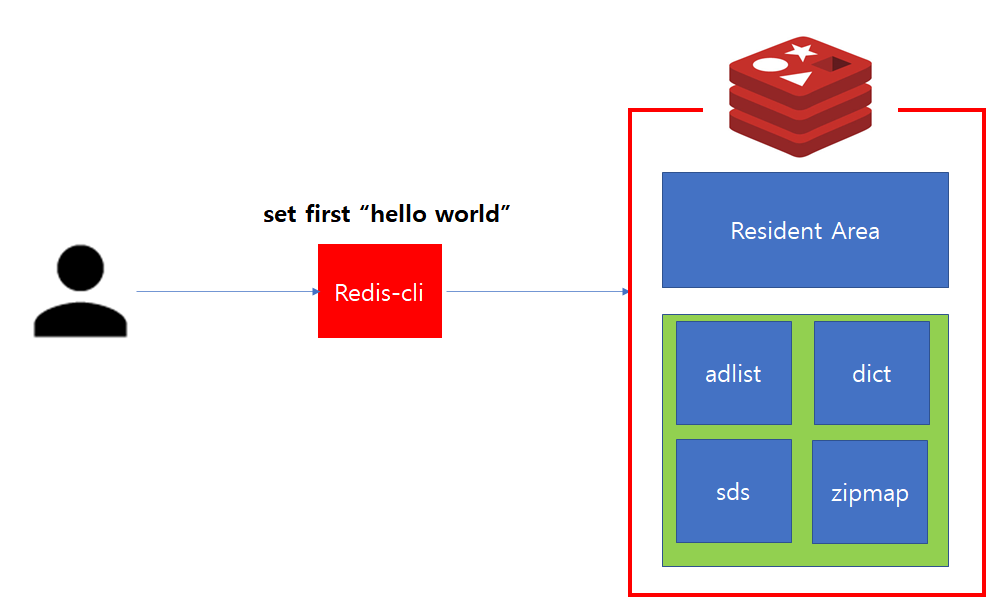
1. Redis 접속
DBMS을 사용하기 위해서는 명령어 처리를 위한 별도 프로그램이 필요합니다. 이를 위해 각 DBMS 벤더사에서 DB와 통신을 위한 CLI(Command Line Interface) 프로그램을 제공합니다. 가령 oracle 사용한다면, oracle에서 기본적으로 제공하는 sql * plus 프로그램을 사용해서 DB에 접속할 수 있습니다.
마찬가지로 Redis를 사용하기 위해서는 Redis에 접속할 수 있는 프로그램이 필요합니다.
redis 접속화면
Redis에서는 이를 위해 redis-cli를 제공하며, Redis가 설치된 환경에서 사용자가 Redis를 사용하기 위해 가장 처음 접하게 되는 프로그램이 redis-cli입니다.
출처 : https://github.com/redis/redis
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
Redis에 접속하게되면, redis-server는 Client 구조체로 저장하여 linked list 형식으로 관리합니다. 여기서 주목할 점은 Client 명령을 처리하기 위해 필요한 인자는 argc와 argv 멤버 변수를 통해 전달되며, 해당 구조는 redisObject 구조체로 정의되어있습니다.
해당 구조체에서 type 멤버 변수는 Redis에서 지원하는 데이터 타입을 의미합니다. 지원하는 타입 종류로는 String, List, Set, Sorted Set, Hash, Bitmap, HyperLogLogs 등이 있습니다. 각 데이터 타입에 대한 소개는 차후 포스팅을 통해 살펴보겠습니다.
그외 redisObject 구조체 각 멤버 변수에 대한 설명은 redisgate 홈페이지에 자세히 소개되어있으니 참고 바랍니다.
2. Redis 구조
출처 : 빅데이터 저장 및 분석을 위한 NoSQL & Redis 책 5.1절 Redis 아키텍처
인스턴스에 정상적으로 접속했다면, 명령어 전달을 통해 데이터를 저장하거나 조작할 수 있습니다. Redis는 In Memory 데이터 구조 저장소로써 위 그림에서 해당되는 데이터 구조는 모두 메모리에 상주합니다.
위 구조에서 Resident Area는 명령어를 통해 실제 데이터가 저장 및 작업이 수행되는 공간입니다. 초록색 영역은 내부적으로 서버 상태를 저장하고 관리하기 위한 메모리 공간으로 사용되며, Data Structure 영역으로 불립니다.
Data Structure 영역에 대한 설명은 차후 데이터 타입 포스팅을 진행할 때 다루어보겠습니다.
출처 : 빅데이터 저장 및 분석을 위한 NoSQL & Redis 책 5.1절 Redis 아키텍처
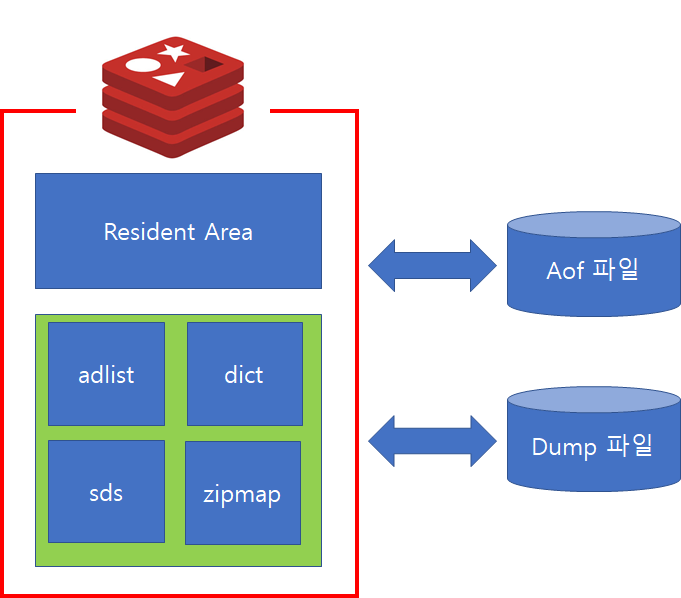
앞서 Redis는 In Memory 데이터 구조 저장소라고 설명했습니다. 하지만 Memory는 휘발성이기 때문에, 프로세스를 종료하게되면 데이터는 모두 유실됩니다. 따라서 단순 캐시용도가 아닌 Persistence 저장소로 활용을 위해서는 Disk에 저장하여 데이터 유실이 발생되지 않도록 해야합니다. 이를 위해 AOF(Append Only File)기능과 RDB(Snapshot) 기능이 존재합니다.
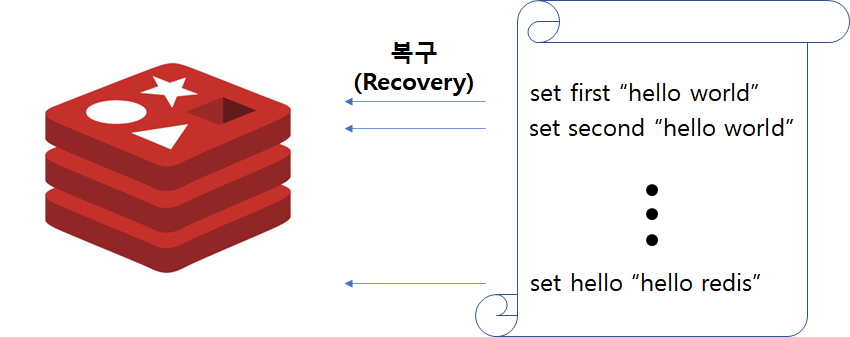
AOF는 전달된 명령을 별도에 파일에 기록하는 방법으로 RDBMS의 Redo 메커니즘과 유사합니다. AOF의 역할은 재기동시 파일에 기록된 명령어를 일괄 수행하여 데이터를 복구하는데 사용됩니다.
AOF의 장점으로는 데이터 유실이 발생하지 않습니다. 하지만 매 명령어마다 File과의 동기화가 필요하기 때문에 처리속도가 현격히 줄어듭니다. 따라서 이를 해소하기위해 File Sync 옵션(appendfsync)이 존재하며, 해당 옵션에 따라 Sync 주기를 조절할 수 있으나 그만큼 데이터 유실이 발생할 수 있습니다.
반면 RDB는 특정 시점의 메모리 내용을 복사하여 파일에 기록하는 방법으로 RDBMS Full Backup에 해당합니다. 따라서, 정기적 혹은 비정기적으로 저장이 필요할 시점에 데이터를 저장이 가능합니다.
RDB의 장점으로는 AOF에 비해 부하가 적으며, LZF 압축을 통해 파일 압축이 가능합니다. 또한 덤프파일을 그대로 메모리에 복원(Restore)하므로 AOF에 비해 빠릅니다. 반면 덤프를 기록한 시점이후 데이터는 저장되지 않으므로 복구시에 데이터 유실이 발생할 수 있는 문제점이 있습니다.
AOF와 RDB를 사용할 때는 유의해야할 점이 있습니다. 바로 Copy On Write입니다. AOF를 백그라운드로 수행하거나 RDB를 수행할때 redis-server에서 자식 프로세스를 fork하여 처리를 위임합니다. 만약 이과정에서 redis-server의 데이터에 쓰기 작업을 수행한다면, 기존 페이지를 수정하는 것이 아닌 이를 별도 공간에 저장 후 처리합니다. 따라서 해당 작업을 수행도중에 쓰기 작업이 증가한다면, 메모리 사용량이 급격히 증가될 수 있습니다.(최대 2배) 따라서 이를 유의해야합니다.
3. Redis 복제(Replication)
이번에는 Redis 복제에 대해서 알아보겠습니다. 먼저 복제가 필요한 이유에 대해서 먼저 알아봅시다.
Redis는 충분히 빠르고 안정적입니다. 하지만 서비스가 갑자기 잘되어 트래픽이 몰린다면 어떻게 될까요?
서버의 한계점을 넘어간다면, 인스턴스 장애가 발생할 수 있습니다. 이때 만약 단일 인스턴스로만 구성되었다면, Redis의 장애가 모든 Application에 영향을 미칩니다.
한편, Redis를 운영하는 입장에서 버전 업그레이드 혹은 서버 PM 작업이 필요하나 Application 영향도로 인해 섯불리 작업할 수 없는 문제가 생깁니다.
마지막으로, 캐시 목적으로 사용하는 Redis는 쓰기 작업보다는 읽기 작업이 주로 발생합니다. 따라서 읽기 작업 성능을 높힐 수 있는 아키텍처 구성이 필요할 수 있습니다.
이를 위해 Redis에서는 어느정도 고가용성을 확보 및 쓰기/읽기 작업 성능을 개선할 수 있는 Master/Replica 토폴로지를 제공합니다.
1. Master/Replica 구조
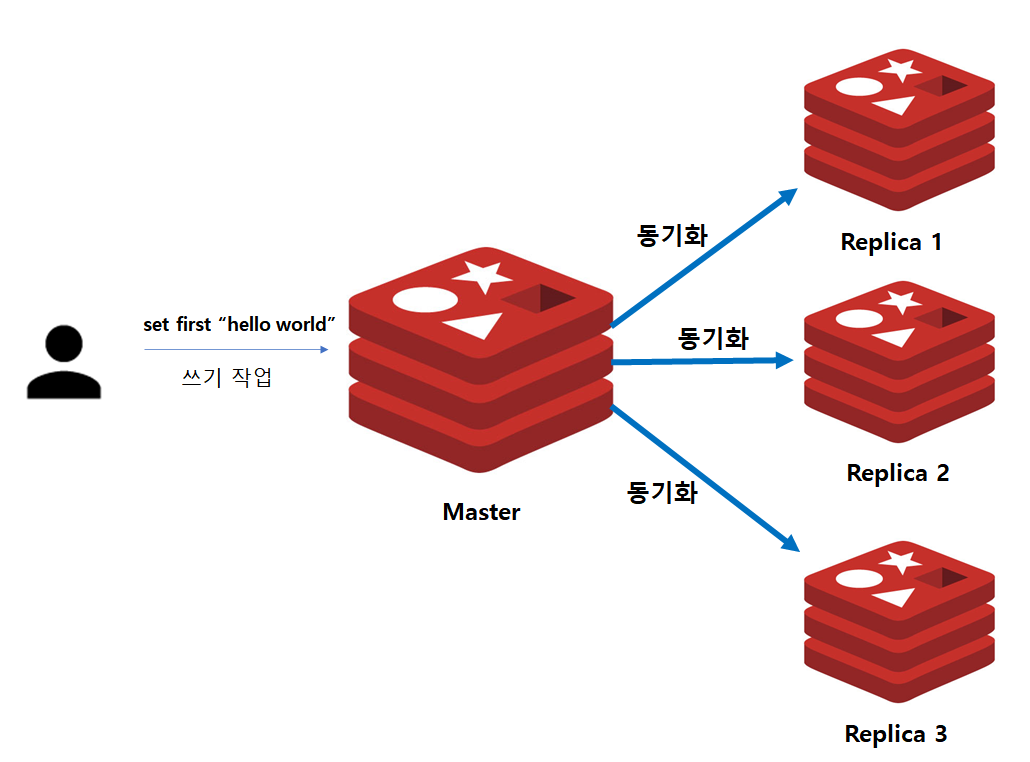
위 그림은 Master/Replica의 구조를 나타냅니다.
최초 Master/Replica 구성시 Master의 데이터는 모든 Replica에 복사합니다. 따라서 어느 Redis 인스턴스에서 데이터를 조회해도 원하는 결과를 얻을 수 있습니다.
만약 데이터의 변경이 발생한다면, 변경 작업은 Master에서만 가능합니다. 이후 변경된 데이터는 비동기적으로 모든 Replica에게 전달되어 반영됩니다.
(※replica-read-only 옵션을no로 설정하면, Replica 상태를 변경할 수 있으나 전체 동기화가 발생하면 모두 유실되므로 추천하지 않습니다.)
이러한 과정은 Oracle Data Guard의 SQL Apply 서비스와 유사합니다. 데이터가 아닌 문장(Statement)이 전달되므로 LuaScript가 적용된 문장이라면 Master와 Replica의 결과가 다를 수 있습니다.
2. Master/Replica 동기화 과정
이번에는 Master/Replica 동기화 과정에 대해서 살펴보겠습니다.
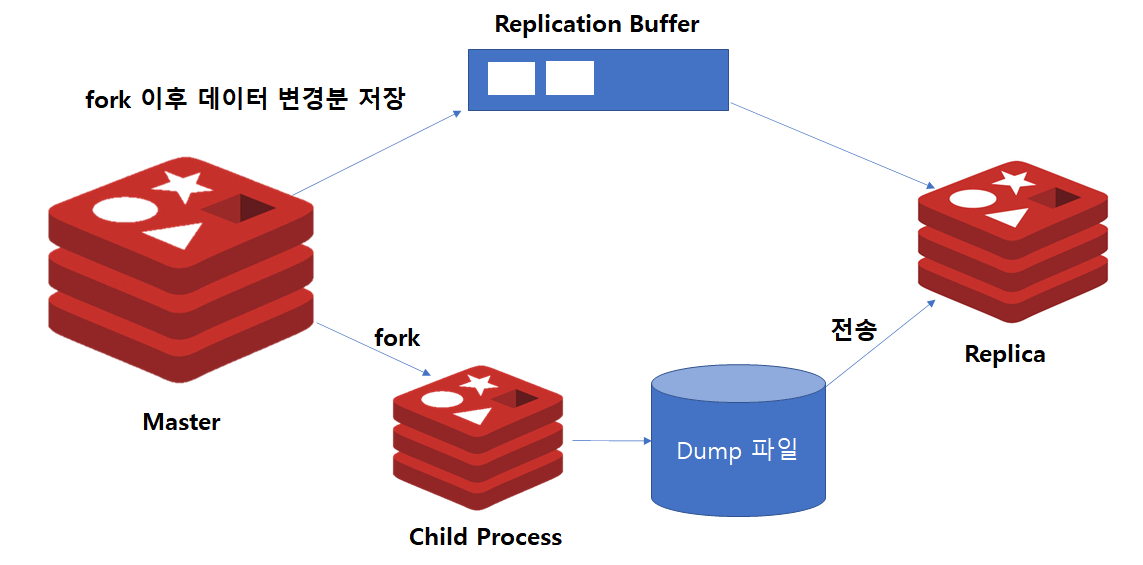
Replica에는 Master 노드에 적재된 데이터가 하나도 존재하지 않으므로 최초 구성시에는 전체 동기화가 발생합니다.
전체 동기화 과정은 다음과 같습니다.
1. Master와 Replica 인스턴스를 별도로 구성합니다.
2. Replica 인스턴스에서 ReplicaOf명령어를 통해 Master 인스턴스와의 동기화 명령을 수행합니다.
3. Master에서는 fork를 통해 자식 프로세스를 생성합니다.
4. 자식 프로세스에서는 Master 메모리에 있는 모든 데이터를 Disk로 dump 합니다.
5. dump가 완료되면, 이를 Replica에 전달하여 반영합니다.
6. Master에서는 복제가 진행되는 동안 변경 데이터를 Replication Buffer에 저장합니다.
7. Dump 전송이 완료되면, Replication Buffer의 내용을 Replica에게 전달하여 데이터를 최신상태로 만듭니다.
8. 작업이 완료되면, 이후에는 데이터 변경발생분만 비동기방식으로 전달됩니다.
최초 구성시에는 전체 동기화(Full Syncronization)이 발생하고, 이때 fork가 발생하므로 메모리 사용량이 증가할 수 있습니다. 따라서 이를 유의해야 합니다.
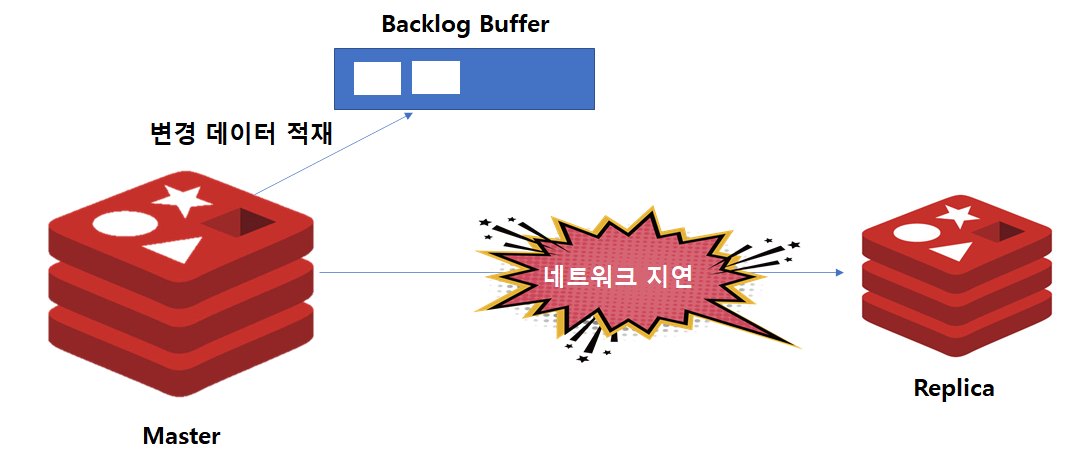
만약 Master/Replica 구성이 완료된 이후에 네트워크 지연이 발생되면 동기화는 어떻게 처리가 될까요?
ReplicaOf 명령어를 통해 Master/Replica 구조가되면, Master 인스턴스에서는 내부적으로 repl-backlog-size 옵션 만큼의 Backlog Buffer가 만들어집니다. 이후 Replica와의 단절이 발생하게 되면, Master 인스턴스에서는 변경 데이터를 Backlog Buffer에 저장합니다. Backlog Buffer는 유한한 크기를 지녔으므로, 지연이 오랫동안 발생한다면 Buffer가 넘칠 수 있습니다.
단절 이후 다시 재연결 되었을 때 과정은 다음과 같습니다.
1. Replica에서 Master와 동기화를 위해 부분 동기화를 시도합니다.
2. 만약 Backlog Buffer에 네트워크 단절 이후의 데이터가 모두 존재하면, Buffer에있는 데이터를 전달받아 최신 상태를 만듭니다.
3. 만약 오랜 시간 네트워크 단절로 인해 Backlog Buffer에 데이터가 유실되었을 경우에는 전체 동기화 과정을 진행합니다.
ADB, RDB를 설명할때도 살펴봤지만, 프로세스 fork가 일어나게되면 메모리 사용율이 급격하게 증가할 수 있으므로 전체 동기화 작업 혹은 Replica 추가 작업시에는 모니터링과 메모리 조정등이 필요합니다.
지금까지 Master/Replica 구조에 대해서 살펴보았습니다. 해당 구조의 장점은 무엇이 있을까요?
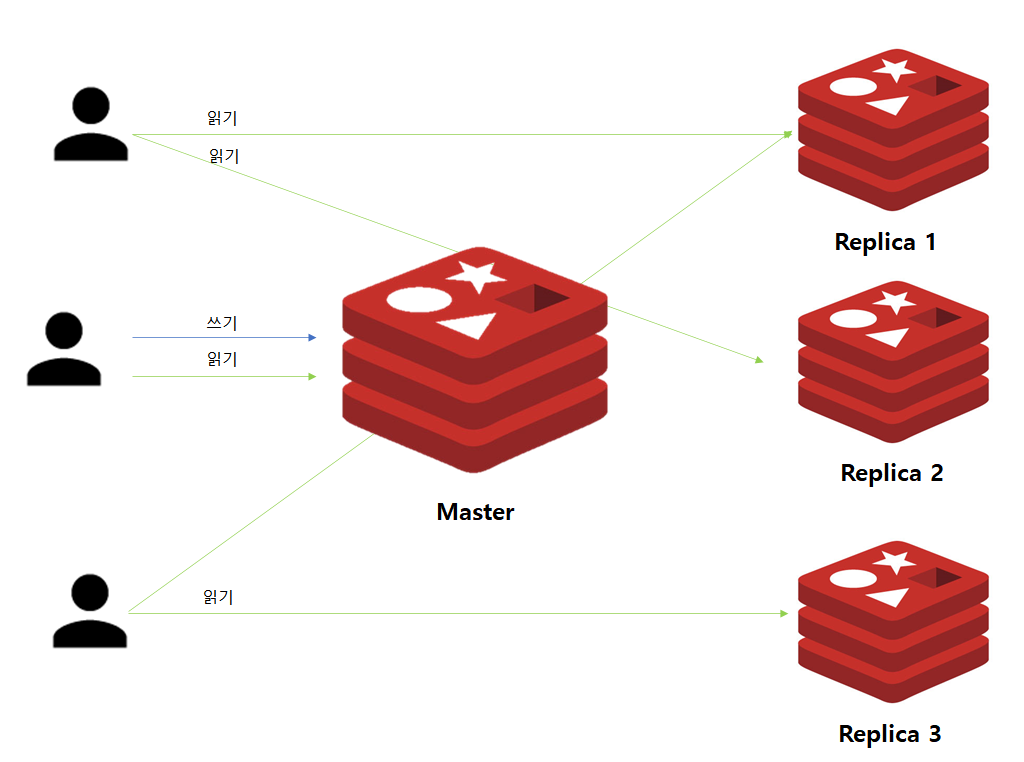
우선 Master 인스턴스와 Replica 인스턴스간 데이터가 공유되어있습니다. 따라서 Replica 중 어느 인스턴스가 다운되더라도 Application의 영향을 최소화할 수 있습니다.
또한, 데이터 조회를 위해 굳이 Master에게 요청하지 않아도 되므로 Read 작업에 대한 부하를 여러 인스턴스로 분산시킬 수 있는 장점이 있습니다.
이번에는 Master/Replica 구성했을 경우 발생되는 문제점에 대해서 살펴보겠습니다.
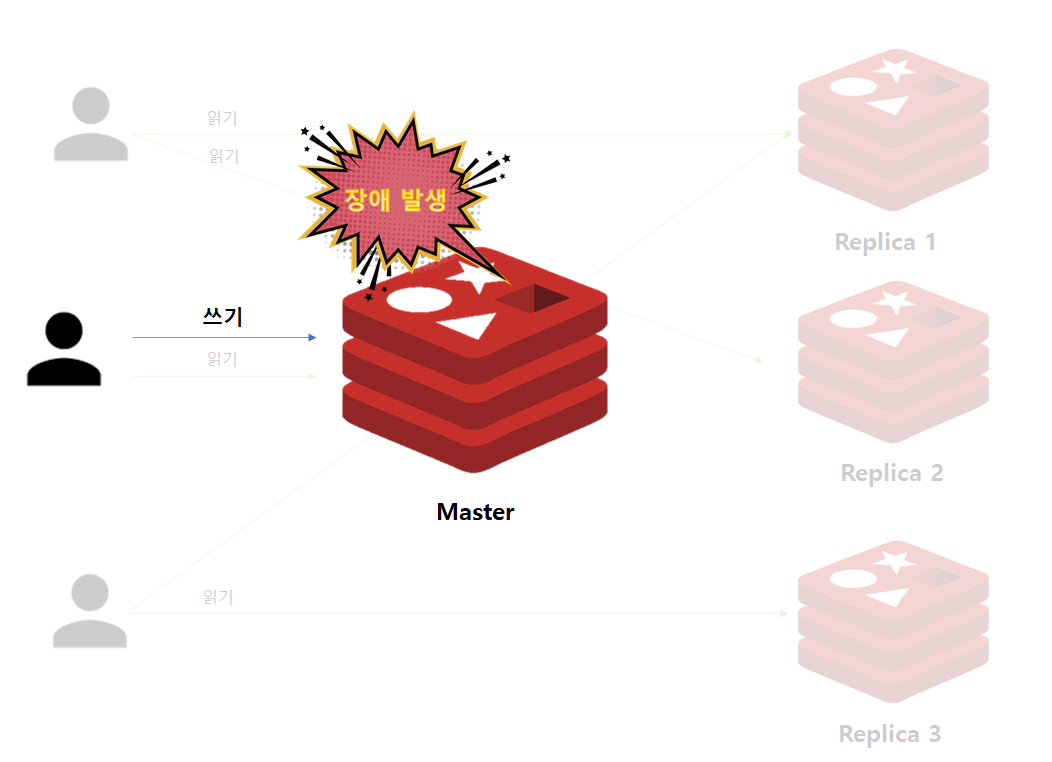
Master 인스턴스에 장애가 발생하여도 다른 Replica에 데이터가 모두 복제되어있으므로 읽기 연산은 문제가 없습니다. 하지만 쓰기 작업은 Master를 통해 이루어지므로 더이상 쓰기 작업 수행될 수 없는 문제가 있습니다.
따라서 단순 Master/Replica 구성을 했을 경우에는 관리자가 모니터링을 통해 장애 여부를 감지하고, 수동으로 Replica 인스턴스 중 하나를 Master로 선정하고, 나머지 Replica에서 새로 변경한 Master를 바라보도록 설정을 변경해야합니다.
즉 다시말해 Master 인스턴스 Crash 발생 시, 자동으로 Failover 해주지 않습니다. Master/Replica를 구성하는 이유 중 하나는 고가용성을 달성하기 위함인데, Failover를 자동으로 해주지 않는 것은 운영자 입장에서는 많이 불편할 수 밖에 없습니다.
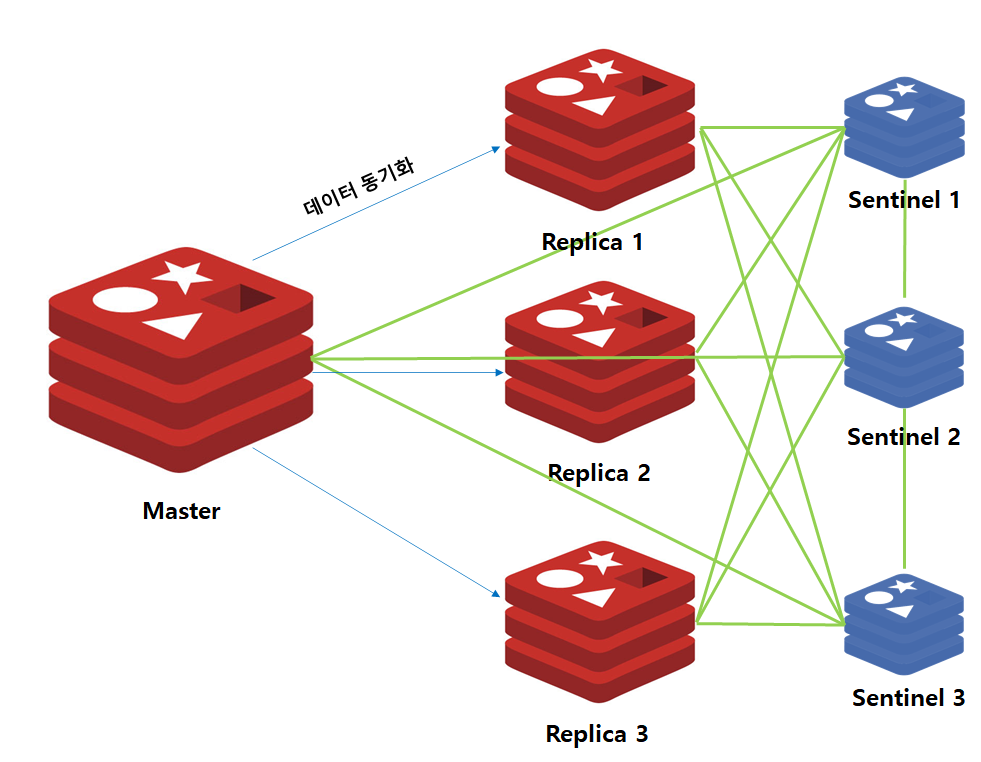
따라서 이러한 이슈를 해결하기 위해 Redis Sentinel 기능을 제공하였습니다. Sentinel은 별도의 프로세스로 Master 인스턴스 다운시, 이를 감지하여 Replica 중 하나를 Master 인스턴스로 Failover 및 이를 Application에게 통지하는 기능을 포함하고 있습니다.
위 그림은 Master/Replica/Sentinel의 구조입니다. 여기서 녹색으로 연결된 선이 Sentinel과 연결된 네트워크 Path를 의미합니다.
Sentinel은 다른 Sentinel을 포함한 모든 Redis 인스턴스와 연결합니다. 이후 1초마다 HeartBeat 통신을 통해 Master 및 Replica 서버가 정상적으로 작동중인지 여부 확인하고 이상 발생시 자동으로 Failover 및 Application에 알림을 전송합니다.
그렇다면, Sentinel을 통해 Failover는 어떤 방식으로 이루어질까요?
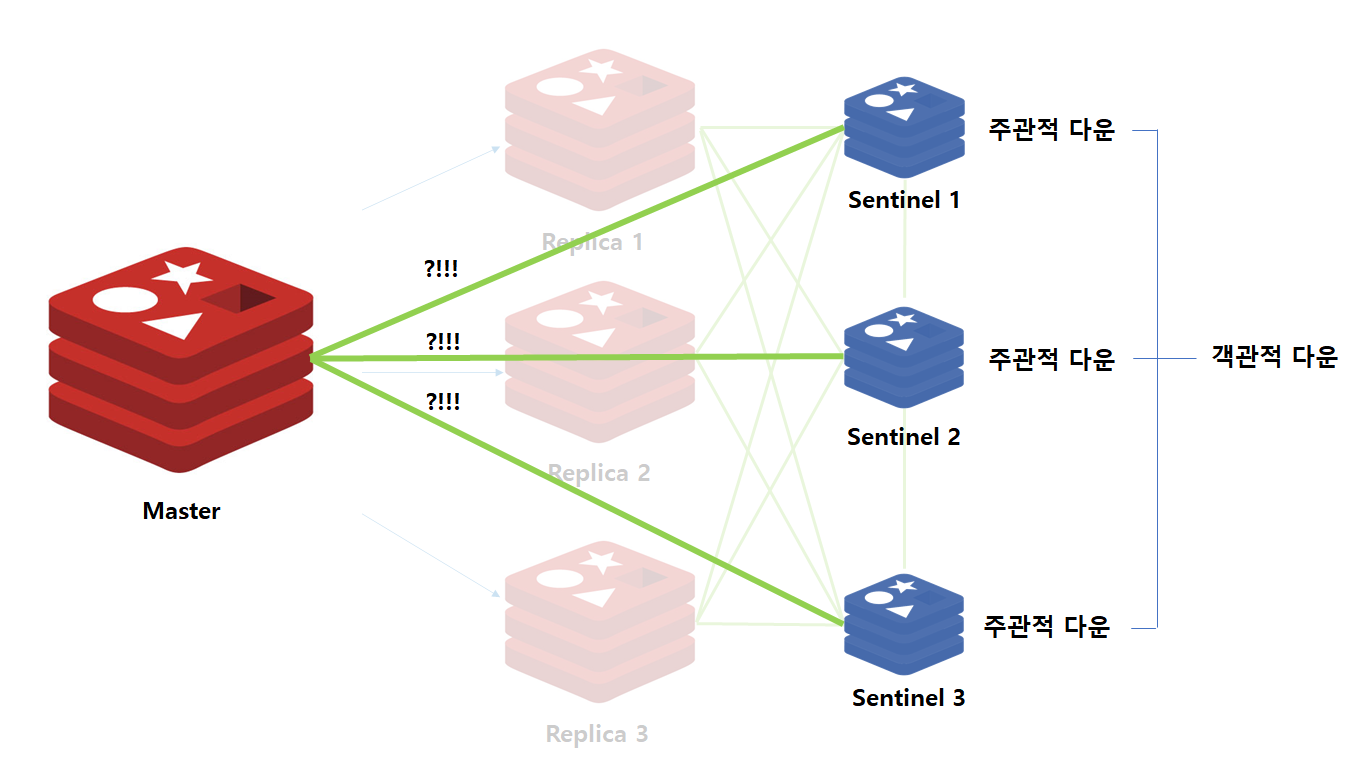
Sentinel과 연결된 노드 중 HeartBeat에 일정 시간동안 응답하지 않는 경우 해당 Sentinel은 장애가 발생한 것으로 간주하고 해당 노드를 주관적 다운(Subjectively Down)으로 인지합니다.
주관적 다운으로 별도 지정한 이유는 해당 Sentinel과의 일시적인 네트워크 연결이 끊긴 것일 수도 있기 때문에 정확한 장애 여부는 아직 확정할 수 없기 때문입니다.
만약 장애가 발생한 인스턴스가 Master일 경우에는 모든 Sentinel에게 Master Down 여부를 묻습니다. Master Down 여부를 전달받은 Sentinel 들은 실제 Master 인스턴스가 죽었는지를 확인 후 이를 응답합니다.
이때 Master 인스턴스에 장애가 발생했다고 응답하는 비율이 정족수(Quorum)를 넘게 되면 이를 객관적 다운(Objectively Down)이라고 인지하게됩니다. 위 구조에서는 2개의 Sentinel 인스턴스가 Master 장애를 인지하게되면, 정족수를 넘게되는 것이므로 객관적 다운으로 인지하게 됩니다.
객관적 다운이 발생하게 되면, 다른 Sentinel 인스턴스와 통신하여 장애 조치 작업을 시작합니다.
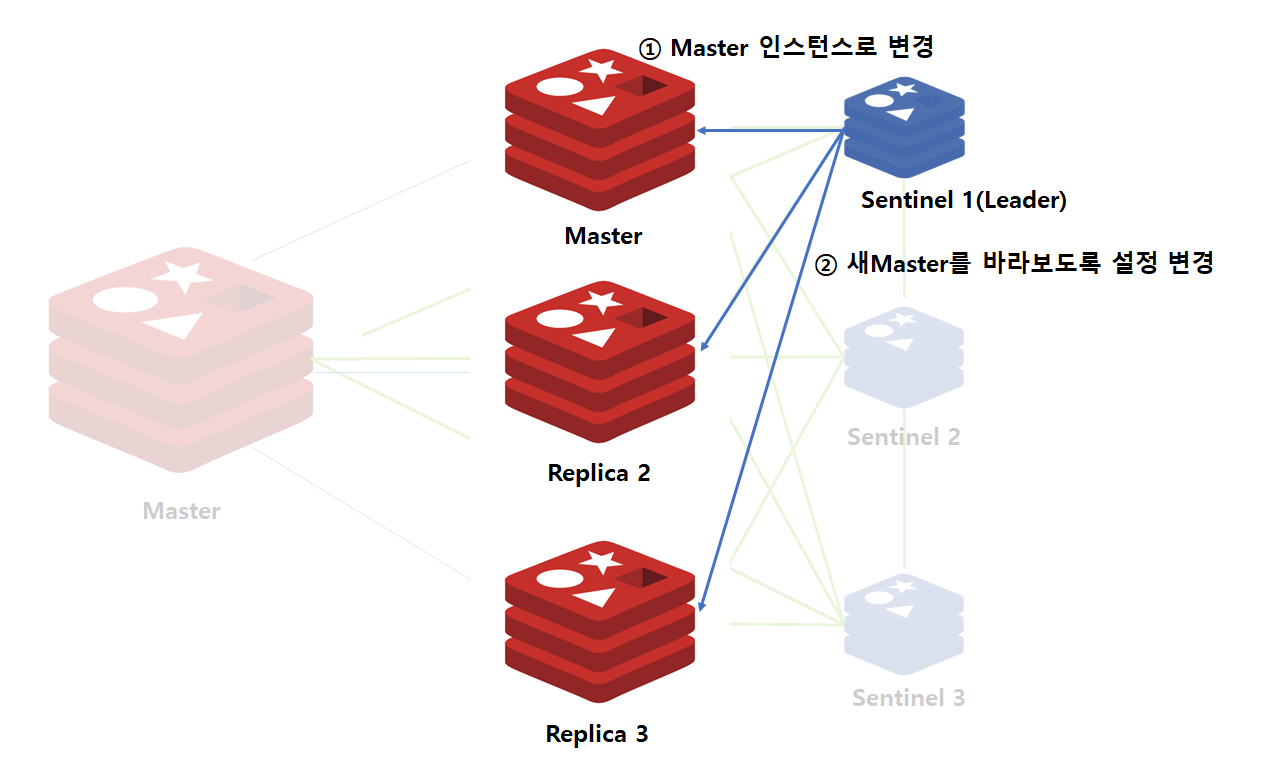
Master 장애가 발생하게 되면 더이상 쓰기 작업이 안되므로 가장 먼저 해야할 작업은 새로운 Master를 선출하는 일입니다. 이를 위해서 Sentinel 프로세스는 새로운 Master 선출 권한이 있는 Sentinel 리더를 뽑는 작업을 합니다.
Sentinel 리더가 선출되면, 리더는 Replica 인스턴스 중 하나를 Master로 승격합니다. 이후 나머지 Replica에서 Master 인스턴스를 모니터링할 수 있도록 명령을 수행하고 장애 복구 작업을 종료합니다.
만약 기존 Master 인스턴스가 다시 살아난다면, 이미 Master가 바뀌었으므로 기존 Master는 Replica로 자동으로 변경됩니다.
이로써, 운영자의 개입없이 자동으로 Failover 하여 고가용성을 어느정도 확보할 수 있게 되었습니다.
여기서 어느정도라는 말을 쓰는 이유는 Master/Replica/Sentinel 구조에서도 데이터 유실이 발생할 수 있기 때문입니다.
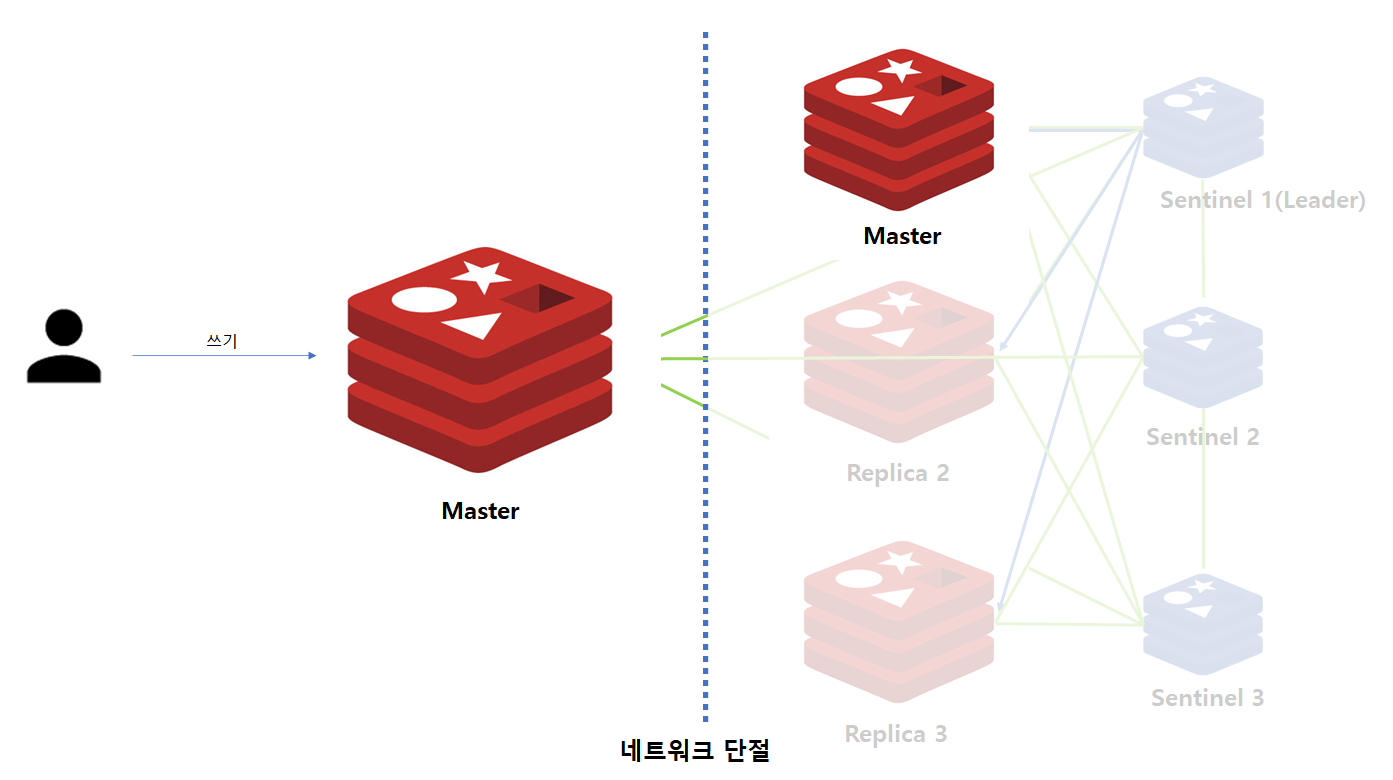
예를 위해 다음과 같은 상황을 가정해보겠습니다.
위 그림은 기존 Master 인스턴스와 나머지 Redis 인스턴스 사이 네트워크가 단절된 모습입니다. 네트워크 이슈이므로 Master 인스턴스는 현재 정상적으로 Client와 통신이 가능하며, 데이터 쓰기 작업이 발생하면 Master 인스턴스에 데이터가 저장됩니다.
하지만 Sentinel과 연결이 끊겼기 때문에 Sentinel은 Master가 죽은 것으로 판단하고 Replica 중 하나를 Master로 선출하게됩니다.
만약 이러한 상황에서 네트워크 단절 이슈가 해결된다면 기존 Master 인스턴스는 Sentinel에 의하여 Replica로 변경이 될 것이고, 이때 기존 Master 인스턴스에 새롭게 수정된 데이터는 유실됩니다.
이번 포스팅에서는 JPA에 Cache 적용방법에 대해서 다루어보겠습니다. 먼저 Cache 선정 기준 및 패턴에 대한 소개 및 적용 방법을 설명합니다. Cache로는 Ehcache3을 적용하며, Spring Actuator를 통해서 캐시 Metric 변화도 함께 살펴보겠습니다.
1. Cache 적용 기준
캐시란 간단하게 말해서 Key와 Value로 이루어진 Map이라고 볼 수 있습니다.
하지만 일반 Map과는 다르게 만료 시간을 통해 freshness 조절 및 캐시 제거 등을 통해서 공간을 조절할 수 있는 특징이 있습니다.
위 그림은 파레토 법칙을 표현합니다. 즉 시스템 리소스 20%가 전체 전체 시간의 80% 정도를 소요함을 의미합니다. 따라서 캐시 대상을 선정할 때에는 캐시 오브젝트가 얼마나 자주 사용하는지, 적용시 전체적인 성능을 대폭 개선할 수 있는지 등을 따져야합니다.
2. HitRatio
HitRatio는 캐시에 대하여 자원 요청과 비례하여 얼마나 캐시 정보를 획득했는지를 나타내며, 계산 식은 다음과 같습니다.
HitRatio = hits / (hits + misses) * 100
캐시공간은 한정된 공간이기 때문에, 만료시간을 설정하여 캐시 유지시간을 설정할 수 있습니다. misses가 높다는 것은 캐시공간의 여유가 없어 이미 캐시에서 밀려났거나, 혹은 자주 사용하지 않는 정보를 캐시하여 만료시간이 지난 오브젝트를 획득하고자할 때 발생할 수 있습니다. 따라서 캐시를 설정할 때는 캐시 공간의 크기 및 만료 시간을 고려해야합니다.
2. Cache 패턴
이번에는 캐시에 적용되는 패턴에 대해서 알아보도록 하겠습니다.
1. No Caching
말 그대로 캐시없이 Application에서 직접 DB로 요청하는 방식을 말합니다. 별도 캐시한 내역이 없으므로 매번 DB와의 통신이 필요하며, 부하가 유발되는 SQL이 지속 수행되면 DB I/O에 영향을 줍니다.
2. Cache-aside
Application 기동시 캐시에는 아무 데이터가 없으며, Application이 요청시에 Cache Miss가 발생하면, DB로부터 데이터를 읽어와 Cache에 적재합니다. 이후에 동일한 요청을 반복하면, 캐시에 데이터가 존재하므로 DB 조회 없이 바로 데이터를 전달받을 수 있습니다.
해당 패턴은 Application이 캐시 적재와 관련된 일을 처리하므로, Cache Miss가 발생했을 때 응답시간이 저하될 수 있습니다.
3. Cache-through
캐시에 데이터가 없는 상황에서 Miss가 발생했을 때, Application이 아닌 캐시제공자가 데이터를 처리한 다음 Application에게 데이터를 전달하는 방법입니다. 즉 기존에는 동기화의 책임이 Application에 있었다면, 해당 패턴은 캐시 제공자에게 책임이 위임됩니다.
Cache-through 패턴은 다음과 같이 세분화할 수 있습니다.
Read-through
데이터 읽기 요청시, 캐시 제공자가 DB와의 연계를 통해 데이터를 적재하고 이를 반환합니다.
Write-through
데이터 쓰기 요청시, Application은 캐시에만 적용을 요청하면, 캐시 제공자가 DB에 데이터를 저장하고, Application에게 응답하는 방식입니다. 모든 작업은 동기로 진행됩니다.
Write-behind
데이터 쓰기 요청시, Application은 데이터를 캐시에만 반영한 다음 요청을 종료합니다. 이후 일정 시간을 간격으로 비동기적으로 캐시에서 DB로 데이터를 저장요청합니다. 이 방식은 Application의 쓰기 요청 성능을 높일 수 있으나 만약 캐시에 DB에 저장하기 전에 다운된다면, 데이터 유실이 발생합니다.
3. EhCache
Ehcache는 Java에서 주로 사용하는 캐시 관련 오픈소스이며, Application에 Embedded되어 간편하게 사용할 수 있는 특징을 지니고 있습니다. EhCache3에서는 JSR-107에서 요구하는 표준을 준수하여 만들어졌기 때문에 2 버전과 3 버전 설정 방법이 다릅니다.
Ehcache에서는 이전에 설명한 캐시 패턴을 모두 적용할 수 있습니다. 그 중 Cache-through 전략은 CacheLoaderWriter 인터페이스 구현을 통해서 적용할 수 있으나 해당 내용에 대해서는 다루지 않겠습니다.
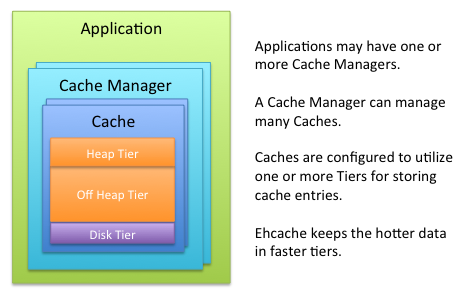
공식 메뉴얼에 따르면, 캐시 중요도에 따라 세군데 영역으로 나뉘어 저장할 수 있습니다. 먼저 Heap Tier는 GC가 관여할 수 있는 JVM의 Heap영역을 말합니다. 반면, Off Heap은 GC에서 접근이 불가능하며 OS가 관리하는 영역입니다. 해당 영역에 데이터를 저장하려면, -XX:MaxDirectMemorySize 옵션 설정을 통해 충분한 메모리를 확보해야합니다. 마지막 영역은 Disk 영역으로 해당 설명은 Skip 하겠습니다.
그럼 지금부터 지금까지 JPA 포스팅하면서 다룬 예제를 확장하여 EhCache를 적용하겠습니다. 예제 프로그램은 Cache-Aside 패턴을 통해 구현하며, 그외 나머지 패턴은 다루지 않겠습니다.
먼저 SharedCache는 캐시모드를 설정할 수 있는 옵션으로 enable_selective는 @Cacheable이 설정된 엔티티에만 캐시를 적용함을 의미합니다. 만약 모든 엔티티에 적용하려면 all 옵션을 줄 수 있습니다.
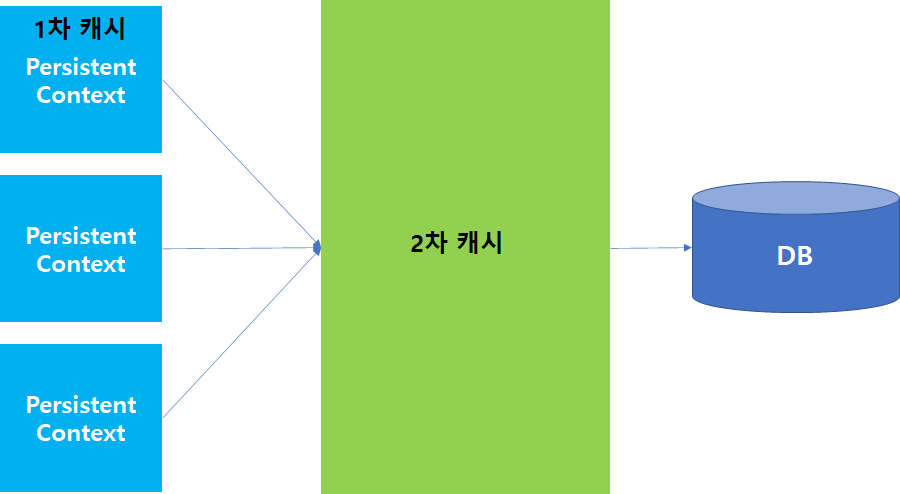
use_second_level_cache는 2차 캐시 활성화 여부를 지정합니다. JPA에서 1차 캐시는 PersistentContext를 의미하며, 각 세션레벨에서 트랜잭션이 진행되는 동안에 캐시됩니다. 반면 2차 캐시는 SessionFactory 레벨에서의 캐시를 의미하며 모든 세션에게 공유되는 공간입니다. 해당 옵션을 통해서 2차 캐시 설정 여부를 지정합니다.
factory_class는 캐시를 구현한 Provider 정보를 지정합니다. Ehcache3는 JSR-107 표준을 준수하여 개발되었기 때문에 JCacheRegionFactory를 지정합니다.
2. Configuration 설정
@Configuration
public class CachingConfig {
public static final String DB_CACHE = "db_cache";
private final javax.cache.configuration.Configuration<Object, Object> jcacheConfiguration;
public CachingConfig() {
this.jcacheConfiguration = Eh107Configuration.fromEhcacheCacheConfiguration(CacheConfigurationBuilder.newCacheConfigurationBuilder(Object.class, Object.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10000, EntryUnit.ENTRIES))
.withSizeOfMaxObjectSize(1000, MemoryUnit.B)
.withExpiry(ExpiryPolicyBuilder.timeToIdleExpiration(Duration.ofSeconds(300)))
.withExpiry(ExpiryPolicyBuilder.timeToLiveExpiration(Duration.ofSeconds(600))));
}
@Bean
public HibernatePropertiesCustomizer hibernatePropertiesCustomizer(javax.cache.CacheManager cacheManager) {
return hibernateProperties -> hibernateProperties.put(ConfigSettings.CACHE_MANAGER, cacheManager);
}
@Bean
public JCacheManagerCustomizer cacheManagerCustomizer() {
return cm -> {
cm.createCache(DB_CACHE, jcacheConfiguration);
};
}
}
Cache Config 클래스를 작성합니다. 먼저 생성자를 통해 캐시의 기본 설정을 구성했습니다. 위 구성은 테스트를 위해 임의로 지정하였으며, 커스터마이징하여 작성 가능합니다.
지정된 옵션 설명은 다음과 같습니다.
총 10000개의 Entity를 저장할 수 있으며, 각 오브젝트 사이즈는 1000 Byte를 넘지 않도록 제한하였습니다. Object는 최초 캐시에 입력후 600초 동안 저장되며, 만약 마지막으로 캐시 요청이후에 300초동안 재요청이 없을 경우 만료되도록 지정하였습니다.
@Entity
@Table
@Getter
@Cacheable
@org.hibernate.annotations.Cache(region = CachingConfig.DB_CACHE, usage = CacheConcurrencyStrategy.READ_ONLY)
public class Customer {
@Id
@GeneratedValue
@Column(name = "id")
private Long customerId;
@Column(name = "name")
private String customerName;
}
SharedCache 모드를 enable_selective로 지정하였으므로, @Cacheable 어노테이션을 추가하여 해당 엔티티를 캐시할 수 있도록 설정하였습니다. 캐시 제공자내에는 여러 캐시가 존재할 수 있으며, 캐시마다 이름이 부여되어있으므로 region영역에는 캐시내에서 참조할 캐시이름을 지정합니다.
usage는 캐시와 관련된 동시성 전략을 지정할 수 있습니다. 지정할 수 있는 옵션으로는 NONE, READ_ONLY, NONSTRICT_READ_WRITE, READ_WRITE, TRANSACTIONAL 총 5가지 입니다. 예제 프로그램에서는 읽기 전용으로만 지정하기 위해서 READ_ONLY 옵션을 부여했습니다.
@Service
@Slf4j
public class CustomerService {
...(중략)...
public CustomerDTO getCustomer(Long id) {
log.info("getCustomer from db ");
Customer customer = repository.findById(id).orElseThrow(IllegalAccessError::new);
return CustomerDTO.of(customer);
}
}
@RestController
@RequiredArgsConstructor
@RequestMapping("/customers")
public class CustomerController {
...(중략)...
@GetMapping("/{id}")
public CustomerDTO getCustomer(@PathVariable Long id) {
return service.getCustomer(id);
}
}
테스트를 위해 Service 및 Controller에 관련 메소드를 생성합니다.
2020-08-05 23:09:30.493 INFO 1872 --- [nio-8080-exec-1] c.e.paging_demo.service.CustomerService : getCustomer from db
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
customer customer0_
where
customer0_.id=?
2020-08-05 23:09:40.278 INFO 1872 --- [nio-8080-exec-2] c.e.paging_demo.service.CustomerService : getCustomer from db
2020-08-05 23:09:51.598 INFO 1872 --- [nio-8080-exec-3] c.e.paging_demo.service.CustomerService : getCustomer from db
2020-08-05 23:09:52.384 INFO 1872 --- [nio-8080-exec-4] c.e.paging_demo.service.CustomerService : getCustomer from db
실행 후 로그 출력 결과입니다. 최초 요청시에는 SQL 수행결과가 로그에 기록되었지만, 그 이후에는 SQL이 수행되지 않고 2차 캐시에서 정상적으로 가져온 것을 확인할 수 있습니다.
3. DTO 레벨 캐시 추가 설정
이번에는 테스트 목적으로 Entitiy 뿐만 아니라 DTO에도 캐시를 적용해보겠습니다. 테스트를 위해 두 대상은 다른 캐시영역에 저장되며, 두 캐시영역간 설정에 차이를 두겠습니다.
@Configuration
public class CachingConfig {
public static final String DB_CACHE = "db_cache";
public static final String USER_CACHE = "user_cache";
...(중략)...
@Bean
public JCacheManagerCustomizer cacheManagerCustomizer() {
return cm -> {
cm.createCache(DB_CACHE, jcacheConfiguration);
cm.createCache(USER_CACHE, Eh107Configuration.fromEhcacheCacheConfiguration(CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, CustomerDTO.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10000, EntryUnit.ENTRIES))
.withSizeOfMaxObjectSize(1000, MemoryUnit.B)
.withExpiry(ExpiryPolicyBuilder.timeToIdleExpiration(Duration.ofSeconds(10)))
.withExpiry(ExpiryPolicyBuilder.timeToLiveExpiration(Duration.ofSeconds(20)))));
};
}
}
새로운 캐시를 추가하기 위해서 위와같이 Configuration 클래스를 수정했습니다. 신규로 추가하는 USER_CACHE는 만료시간을 훨씬 짧게하여 최장 20초간만 캐시에 저장되도록 설정하였습니다.
@Service
@Slf4j
public class CustomerService {
...(중략)...
@Cacheable(value = CachingConfig.USER_CACHE, key ="#id")
public CustomerDTO getCustomer(Long id) {
log.info("getCustomer from db ");
Customer customer = repository.findById(id).orElseThrow(IllegalAccessError::new);
return CustomerDTO.of(customer);
}
}
@RestController
@RequiredArgsConstructor
@RequestMapping("/customers")
@Slf4j
public class CustomerController {
...(중략)...
@GetMapping("/{id}")
public CustomerDTO getCustomer(@PathVariable Long id) {
log.info("Controller 영역");
return service.getCustomer(id);
}
}
Service 클래스에 @Cacheable 어노테이션을 추가하여 캐시를 지정합니다. 이때 key는 파라미터로 전달받은 id를 지정하며, SPEL을 사용할 수 있습니다.
Controller 클래스에는 별다른 로직 추가 없이 로그만 남기도록 수정했습니다. 이제 어플리케이션을 재기동 후 결과를 보겠습니다.
2020-08-05 23:18:53.012 INFO 13244 --- [nio-8080-exec-1] c.e.p.controller.CustomerController : Controller 영역
2020-08-05 23:18:53.055 INFO 13244 --- [nio-8080-exec-1] c.e.paging_demo.service.CustomerService : getCustomer from db
Hibernate:
select
customer0_.id as id1_0_0_,
customer0_.name as name2_0_0_
from
customer customer0_
where
customer0_.id=?
2020-08-05 23:18:57.093 INFO 13244 --- [nio-8080-exec-2] c.e.p.controller.CustomerController : Controller 영역
2020-08-05 23:18:57.821 INFO 13244 --- [nio-8080-exec-3] c.e.p.controller.CustomerController : Controller 영역
2020-08-05 23:19:03.127 INFO 13244 --- [nio-8080-exec-4] c.e.p.controller.CustomerController : Controller 영역
2020-08-05 23:19:29.327 INFO 13244 --- [nio-8080-exec-6] c.e.p.controller.CustomerController : Controller 영역
2020-08-05 23:19:29.329 INFO 13244 --- [nio-8080-exec-6] c.e.paging_demo.service.CustomerService : getCustomer from db
최초 기동 후에는 모든 캐시에 정보가 없으므로 Controller -> Service -> DB 순으로 호출되어 데이터가 캐싱되었음을 확인할 수 있습니다.
이후에는 Service Layer의 DTO 또한 캐시되었으므로 지속 호출시에 Controller 로그는 출력되나 Service 레벨 메소드는 호출되지 않습니다.
20초가 지난 이후에는 Service Layer에 지정된 DTO 캐시가 만료되므로 Entity에 접근하나 해당 캐시는 아직 유효하므로 별도 DB 통신 없이 캐시에서 데이터를 반환하는 것을 확인할 수 있습니다.
지금까지 캐시 적재에 대해서만 살펴봤는데, 만약 수정, 삭제등으로 인해 캐시를 삭제해야한다면 @CacheEvict 어노테이션을 통해 삭제할 수 있습니다.
4. Actuator 적용
Spring Actuator 프로젝트를 사용하게되면, 모니터링에 필요한 유용한 Metric 뿐만 아니라 HealthCheck 및 Dump 생성 그리고 Reload 등이 가능합니다. Spring Actuator를 통해서 Cache와 관련된 Metric을 활용해 Prometheus & Grafana 대시보드로 시각화 또한 가능합니다.
이번에는 Actuator 적용 후 URL 호출을 통해 Metric을 확인하는 방법에 대해서 살펴보겠습니다.
프로그램 기동 후 ip:port/actuator URL을 호출하면 위와 같이 상세 정보를 볼 수 있는 URL이 제공됩니다.
Cache 관련 정보는 metrics 하위에 위 표시된 영역으로 정보를 확인할 수 있습니다.
위 그림은 gets과 관련된 metric 정보이며, 총 7번의 get 요청이 있었음을 확인할 수 있습니다. 그 밖에 다른 정보들도 제공되는 URL을 통해 정보 확인이 가능합니다.
마치며
이번 포스팅에서는 JPA 캐시 적용에 대해서 알아봤습니다. 일반적으로 코드성 데이터나 공지사항과 같이 수정/삭제가 거의 없고 자주 사용되는 데이터에 대해서 캐시를 적용하면, 좋은 효과를 볼 수 있습니다. 하지만 무턱대고 적용했다가는 오히려 성능 저하가 발생될 수 있으니 전략 수립이 필요합니다.
이번 포스팅에서는 각 Application 내부에서만 유효한 Local Cache에 대해서 다루었습니다. EhCache가 Clustering을 지원하지만, Application Scale Out에 영향을 주기때문에 개인적으로는 가급적 Local Cache로써 사용하고 캐시 무효화 시간을 짧게 가지는 것이 좋다고 생각합니다. 만약 캐시간의 동기화가 필요하다면 Clustering을 고려하거나 Redis와 같은 Third 캐시를 추가로 두는 것을 고려해볼 수 있습니다.